Clear Sky Science · it
Z-Calling: uno strumento per la chiamata A/Z (2,6-diaminopurina) e il rilevamento di dZ-DNA usando letture PacBio HiFi
Perché un nuovo tipo di DNA conta
Il DNA viene spesso descritto come il progetto universale della vita, costruito da quattro lettere familiari: A, T, C e G. Ma alcuni virus violano silenziosamente questa regola, sostituendo la lettera A con una cugina chimica chiamata Z che rende il loro DNA più robusto e più difficile da attaccare. Questa scoperta suggerisce l’esistenza di uno strato nascosto di diversità genetica con importanti implicazioni per biotecnologia, medicina e persino archiviazione dei dati. La sfida è semplice da enunciare ma difficile da risolvere: come possono gli scienziati individuare e mappare in modo affidabile questo insolito Z‑DNA, soprattutto quando è mescolato al DNA ordinario? Questo studio presenta Z-Calling, uno strumento computazionale che rende finalmente possibile tutto ciò utilizzando la tecnologia di sequenziamento a letture lunghe già esistente.
Una lettera strana nell’alfabeto genetico
Nella maggior parte degli organismi, la base adenina (A) si appaia con la timina (T) tramite due legami a idrogeno, contribuendo a stabilizzare la classica doppia elica del DNA. Alcuni batteriofagi — virus che infettano i batteri — si sono evoluti per sostituire A con la 2,6-diaminopurina, soprannominata Z. Z forma tre legami a idrogeno con la T, rendendo l’elica del DNA più stabile e alterandone il comportamento fisico. Questa chimica insolita può dare ai virus contenenti Z un vantaggio contro le difese dell’ospite e apre la strada a molecole ingegnerizzate con prestazioni migliori. I ricercatori hanno già dimostrato che Z può affinare test genetici, modulare reazioni di editing genico CRISPR e ridurre risposte immunitarie verso farmaci sperimentali a base di RNA. Tuttavia, senza un metodo per individuare esattamente dove Z si trova lungo un filamento di DNA, è stato difficile comprendere appieno o sfruttare questi vantaggi.
Gli strumenti attuali non bastano
Le tecnologie di sequenziamento standard assumono che tutti i segnali simili ad A siano realmente A, quindi tendono a leggere Z come adenina ordinaria. Metodi chimici come la cromatografia liquida ad alte prestazioni possono rilevare la quantità di Z presente in massa, ma non possono indicare dove ciascuna Z sia collocata lungo un genoma, soprattutto in campioni ambientali complessi che mescolano molte specie. Alcune piattaforme di terza generazione, come i dispositivi nanopore, sono teoricamente sensibili abbastanza da percepire la differenza tra basi, ma in pratica i loro segnali possono essere rumorosi e difficili da interpretare quando è presente una chimica non familiare. Fino ad ora non esisteva un modo conveniente e affidabile per scandagliare miscugli di DNA complessi e separare chiaramente il DNA normale da quello contenente Z, né per distinguere A e Z una lettera alla volta.
Ascoltare il ritmo della sintesi del DNA
Gli autori si sono concentrati sul PacBio Circular Consensus Sequencing, una tecnologia che copia ripetutamente la stessa molecola di DNA e registra non solo quale base viene aggiunta, ma anche quanto velocemente avviene ogni aggiunta. Due misure temporali — la durata dell’impulso (pulse width, quanto tempo la polimerasi impiega per aggiungere una base) e la durata inter‑impulso (inter‑pulse duration, la pausa tra aggiunte) — formano una sorta di traccia ritmica della sintesi del DNA. Confrontando molti campioni di DNA progettati ad arte, inclusi DNA ordinario, DNA completamente sostituito con Z e molecole ibride dove A e Z coesistono, il gruppo ha dimostrato che la sostituzione di A con Z genera cambiamenti temporali sottili ma coerenti. Questi cambiamenti dipendono dal contesto di sequenza circostante e colpiscono principalmente la durata dell’impulso in una finestra ristretta attorno al sito Z, lasciando l’accuratezza complessiva del sequenziamento quasi pari a quella del DNA non modificato.
Come Z-Calling individua le basi Z nascoste
Sfruttando questi schemi temporali, i ricercatori hanno addestrato modelli di apprendimento automatico per riconoscere l“accento” cinetico della Z. Il loro strumento, Z-Calling, svolge due compiti principali. Primo, classifica intere letture di sequenziamento come DNA ordinario o DNA contenente Z, anche in metagenomi artificiali che mescolano molte specie e chimiche. Lo fa usando una rete neurale che assegna a ciascuna posizione simile ad A un punteggio di probabilità di essere Z, quindi immettendo la distribuzione di questi punteggi in una macchina a vettori di supporto (support vector machine) che decide se l’intera lettura provenga da DNA-Z. Secondo, esegue la discriminazione a singola lettera, assegnando a ogni posizione la designazione A o Z in base al contesto sequenziale locale e ai segnali cinetici. Nei dataset provenienti da batteri, lievito, piante, animali e da un fago naturalmente contenente Z, questi modelli hanno raggiunto elevata accuratezza (valori area under curve intorno a 0,94–0,98), simili agli strumenti di punta che rilevano marchi comuni di metilazione del DNA.
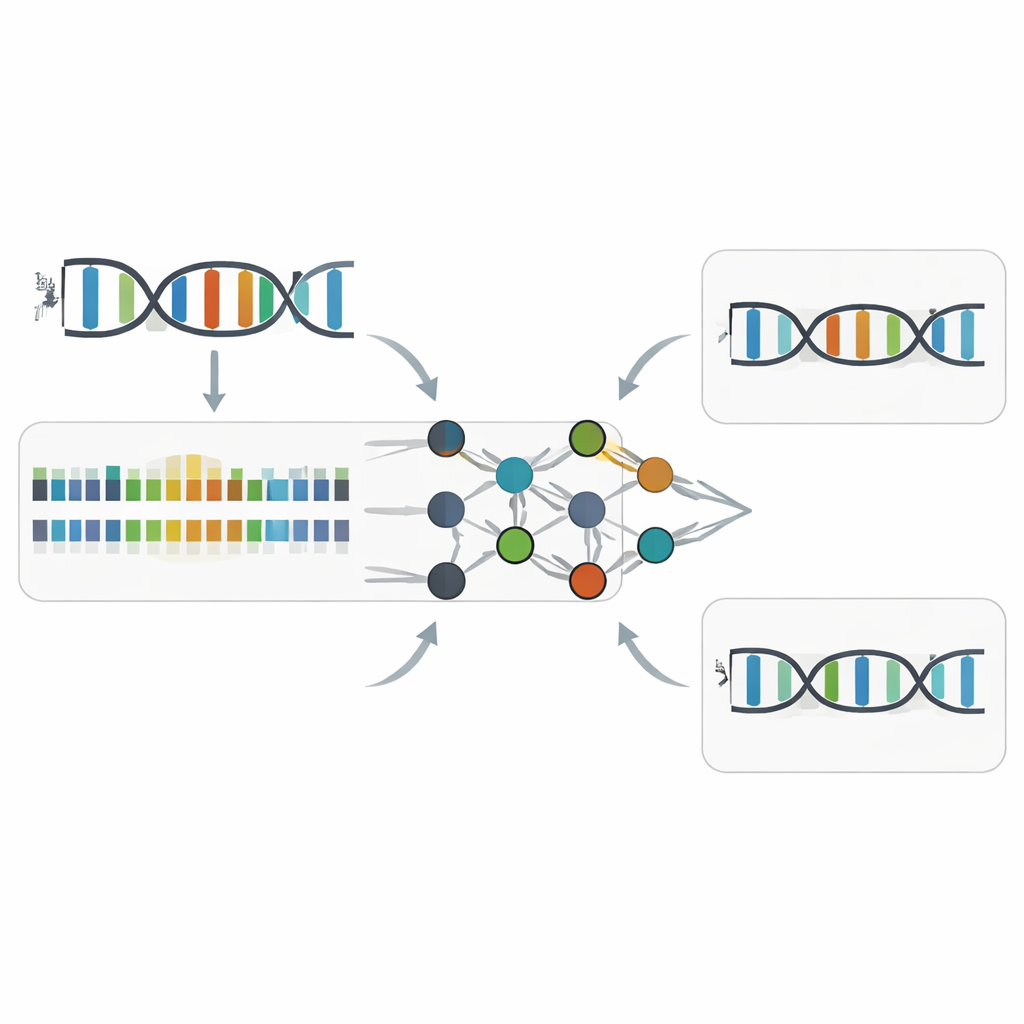
Mettere lo strumento alla prova nel mondo reale
Per dimostrare che Z-Calling funziona oltre i costrutti di laboratorio puri, gli autori lo hanno applicato a un ceppo di lievito ingegnerizzato che sostituisce parzialmente l’adenina con Z in tutto il suo genoma. L’analisi chimica ha indicato che circa un quarto di tutte le posizioni simili ad A era diventato Z. Z-Calling ha stimato in modo indipendente una frazione simile e ha mappato come Z fosse distribuito su cromosomi e plasmidi del lievito, rivelando una distribuzione sostanzialmente casuale. Lo strumento ha anche scandagliato dataset misti in cui solo una piccolissima frazione di letture apparteneva a virus con DNA-Z o genomi ibridi. Anche quando le letture contenenti Z costituivano appena circa l’uno percento del totale, Z-Calling riusciva comunque a segnalarne la presenza con alta confidenza, mantenendo al contempo falsi allarmi estremamente rari su molti genomi di controllo ricchi di marchi epigenetici naturali.
Cosa significa per il futuro
Trasformando le sottili stranezze temporali del sequenziamento del DNA in segnali chiari, Z-Calling fornisce il primo modo pratico per mappare sistematicamente dove compaiono le basi Z, base per base e genoma per genoma. Per il lettore generale, il messaggio chiave è che il nostro alfabeto genetico è più flessibile di quanto si pensasse e ora disponiamo di un metodo per leggere una delle sue lettere alternative più intriganti ad alta risoluzione. Questa capacità aiuterà gli scienziati a cercare più virus basati su Z in natura, a validare organismi ingegnerizzati che usano Z per maggiore stabilità o nuove funzioni, ed esplorare polimeri simili al DNA esotici per l’archiviazione sicura delle informazioni e terapie avanzate. In breve, Z-Calling trasforma una curiosità chimica oscura in una caratteristica tracciabile dei genomi del mondo reale.
Citazione: Wu, B., Chen, Y., Zhou, Y. et al. Z-Calling: a tool for A/Z (2,6-diaminopurine) base calling and dZ-DNA detection using PacBio HiFi reads. Commun Biol 9, 594 (2026). https://doi.org/10.1038/s42003-026-09849-8
Parole chiave: Z-DNA, basi non canoniche, sequenziamento PacBio, apprendimento automatico genomica, genomica dei fagi