Clear Sky Science · de
Z-Calling: ein Werkzeug zur A/Z-(2,6-Diaminopurin)-Basenbestimmung und dZ-DNA-Erkennung mit PacBio-HiFi-Lesungen
Warum eine neue Art von DNA wichtig ist
DNA wird oft als universeller Bauplan des Lebens beschrieben und besteht aus vier vertrauten Buchstaben: A, T, C und G. Manche Viren brechen diese Regel jedoch leise, indem sie das A durch einen chemischen Verwandten namens Z ersetzen, der ihre DNA robuster und schwerer angreifbar macht. Diese Entdeckung deutet auf eine versteckte Ebene genetischer Vielfalt hin, mit großen Folgen für Biotechnologie, Medizin und sogar Datenspeicherung. Die Herausforderung war einfach formuliert, aber schwer zu lösen: Wie können Wissenschaftler zuverlässig dieses ungewöhnliche Z-DNA finden und kartieren, gerade wenn sie mit gewöhnlicher DNA vermischt ist? Diese Studie stellt Z-Calling vor, ein rechnergestütztes Werkzeug, das dies mithilfe vorhandener Langlese-Sequenzierungstechnologie erstmals möglich macht.
Ein seltsamer Buchstabe im genetischen Alphabet
In den meisten Organismen paart sich die Base Adenin (A) mit Thymin (T) über zwei Wasserstoffbrücken und stabilisiert so die klassische DNA-Doppelhelix. Einige Bakteriophagen — Viren, die Bakterien infizieren — haben sich entwickelt, das A durch 2,6-Diaminopurin, kurz Z, zu ersetzen. Z bildet drei Wasserstoffbrücken mit T, wodurch die DNA-Helix stabiler wird und sich ihr physikalisches Verhalten ändert. Diese ungewöhnliche Chemie kann Z-enthaltenden Viren einen Vorteil gegenüber Wirtsabwehrmechanismen verschaffen und eröffnet Möglichkeiten für konstruierte Moleküle mit verbesserten Eigenschaften. Forschende haben bereits gezeigt, dass Z genetische Tests schärfen, CRISPR-Geneditierungsreaktionen beeinflussen und Immunreaktionen auf experimentelle RNA-Medikamente verringern kann. Doch ohne eine Methode, genau zu lokalisieren, wo Z in einer DNA-Strangs sitzt, war es schwierig, diese Vorteile vollständig zu verstehen oder zu nutzen.
Aktuelle Werkzeuge reichen nicht aus
Standard-DNA-Sequenzierungstechnologien gehen davon aus, dass alle A-ähnlichen Signale tatsächlich A sind, und lesen Z daher meist fälschlich als gewöhnliches Adenin. Chemische Methoden wie Hochleistungsflüssigkeitschromatographie können zwar die Gesamtmenge an Z in der Probe bestimmen, aber nicht angeben, wo jedes einzelne Z entlang eines Genoms sitzt — insbesondere nicht in verfilzten Umweltproben, die viele Arten mischen. Einige Sequenzierplattformen der dritten Generation, etwa Nanopore-Geräte, sind theoretisch empfindlich genug, um Unterschiede zwischen Basen zu erfassen, doch in der Praxis sind ihre Signale oft rauschbehaftet und schwer zu interpretieren, wenn ungewohnte Chemie vorliegt. Bislang gab es keinen bequemen, zuverlässigen Weg, komplexe DNA-Gemische zu durchsuchen und normale DNA klar von Z-enthaltender DNA zu trennen oder A und Z Buchstabe für Buchstabe zu unterscheiden.
Dem Rhythmus der DNA-Synthese zuhören
Die Autoren konzentrierten sich auf die PacBio Circular Consensus Sequencing-Technologie, die ein DNA-Molekül wiederholt kopiert und nicht nur aufzeichnet, welcher Baustein eingebaut wird, sondern auch wie schnell jeder Einbau erfolgt. Zwei Zeitmessungen — die Pulsbreite (wie lange die Polymerase für das Einfügen einer Base benötigt) und die Inter-Puls-Dauer (die Pause zwischen den Einfügungen) — bilden eine Art Rhythmusspur der DNA-Synthese. Durch den Vergleich vieler sorgfältig gestalteter DNA-Proben, darunter normale DNA, vollständig Z-substituierte DNA und Hybridmoleküle, in denen A und Z koexistieren, zeigte das Team, dass der Ersatz von A durch Z subtile, aber konsistente zeitliche Veränderungen bewirkt. Diese Änderungen hängen vom umgebenden Sequenzkontext ab und betreffen hauptsächlich die Pulsbreite in einem engen Fenster um die Z-Stelle, während die allgemeine Sequenziergenauigkeit nahezu so hoch bleibt wie bei unveränderter DNA.
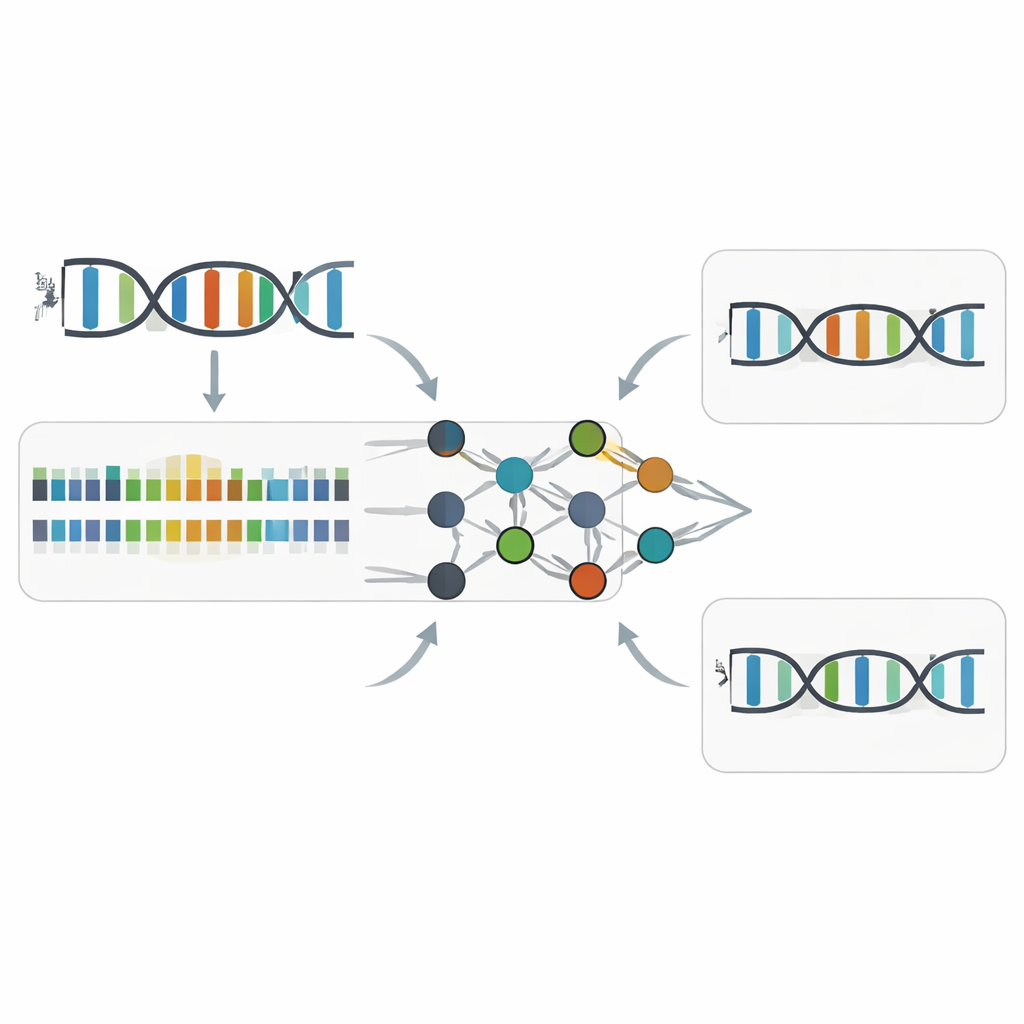
Wie Z-Calling versteckte Z-Basen findet
Aufbauend auf diesen zeitlichen Mustern trainierten die Forschenden Maschinenlernmodelle, um das kinetische „Akzentmuster“ von Z zu erkennen. Ihr Werkzeug, Z-Calling, hat zwei Hauptaufgaben. Erstens klassifiziert es ganze Sequenzierlesungen als gewöhnliche DNA oder Z-enthaltende DNA, selbst in künstlichen Metagenomen, die viele Spezies und Chemien mischen. Dazu verwendet es ein neuronales Netzwerk, das für jede A-ähnliche Position bewertet, wie wahrscheinlich sie Z ist, und übergibt dann die Verteilung dieser Bewertungen an eine Support-Vektor-Maschine, die entscheidet, ob die gesamte Lese aus Z-DNA stammt. Zweitens führt es die Einzelbuchstaben-Unterscheidung durch und ordnet jede Position A oder Z zu, basierend auf lokalem Sequenzkontext und kinetischen Signalen. Über Datensätze aus Bakterien, Hefe, Pflanzen, Tieren und einem natürlich Z-enthaltenden Phagen erreichten diese Modelle hohe Genauigkeiten (AUC-Werte um 0,94–0,98), vergleichbar mit führenden Werkzeugen zur Erkennung gängiger DNA-Methylierungsmarken.
Wie das Werkzeug in der Praxis getestet wurde
Um zu zeigen, dass Z-Calling über saubere Laborproben hinaus funktioniert, wendeten die Autoren es auf einen gentechnisch veränderten Hefestamm an, der Adenin teilweise durch Z im gesamten Genom ersetzt. Chemische Analysen zeigten, dass ungefähr ein Viertel aller A-ähnlichen Positionen zu Z geworden war. Z-Calling schätzte unabhängig einen ähnlichen Anteil und kartierte, wie Z über Hefechromosomen und Plasmide verteilt war, wobei es eine weitgehend zufällige Verteilung offenbarte. Das Werkzeug durchsuchte auch gemischte Datensätze, in denen nur ein winziger Bruchteil der Reads zu Z-DNA-Viren oder Hybridgenomen gehörte. Selbst wenn Z-enthaltende Reads nur etwa ein Prozent des Gesamten ausmachten, konnte Z-Calling ihre Anwesenheit noch mit hoher Sicherheit markieren, während Fehlalarme über viele Kontrollgenome mit natürlichen epigenetischen Markierungen hinweg extrem selten blieben.
Was das für die Zukunft bedeutet
Indem es subtile zeitliche Eigenheiten der DNA-Sequenzierung in klare Signale verwandelt, liefert Z-Calling die erste praktikable Methode, systematisch zu kartieren, wo Z-Basen erscheinen, Base für Base und Genom für Genom. Für eine allgemeine Leserschaft ist die Kernbotschaft, dass unser genetisches Alphabet flexibler ist, als man früher annahm, und dass wir nun eine Möglichkeit haben, einen seiner faszinierendsten alternativen Buchstaben hochauflösend zu lesen. Diese Fähigkeit wird Forschenden helfen, mehr Z-basierte Viren in der Natur zu suchen, gentechnisch veränderte Organismen zu validieren, die Z für erhöhte Stabilität oder neue Funktionen verwenden, und exotische DNA-ähnliche Polymere für sichere Informationsspeicherung und fortschrittliche Therapeutika zu erforschen. Kurz gesagt verwandelt Z-Calling eine obscure chemische Kuriosität in ein nachverfolgbares Merkmal realer Genome.
Zitation: Wu, B., Chen, Y., Zhou, Y. et al. Z-Calling: a tool for A/Z (2,6-diaminopurine) base calling and dZ-DNA detection using PacBio HiFi reads. Commun Biol 9, 594 (2026). https://doi.org/10.1038/s42003-026-09849-8
Schlüsselwörter: Z-DNA, nichtkanonische Basen, PacBio-Sequenzierung, maschinelles Lernen Genomik, Phagen-Genomik