Clear Sky Science · ja
Z-Calling:PacBio HiFiリードを用いたA/Z(2,6-ジアミノプリン)塩基判定とdZ-DNA検出のためのツール
なぜ新しい種類のDNAが重要なのか
DNAはしばしば生命の普遍的な設計図として、A、T、C、Gの四つの文字で表されます。しかし一部のウイルスはこのルールを静かに破り、アデニン(A)の代わりに化学的に類似したZと呼ばれる塩基を取り込むことで、自らのDNAをより頑丈にし攻撃に強くしています。この発見は、バイオテクノロジーや医療、さらにはデータ保存に至るまで大きな意味を持つ遺伝的多様性の隠れた層を示唆します。課題は一言で言えば簡単ですが解決は難しかった:普通のDNAに混ざった状態で、この異例のZ-DNAを信頼して検出・マッピングするにはどうすればよいのか。本研究は既存のロングリードシーケンシング技術を用いて、ついにそれを可能にする計算ツールZ-Callingを紹介します。
遺伝のアルファベットに現れた奇妙な文字
ほとんどの生物では、塩基アデニン(A)はチミン(T)と二本の水素結合で対になり、古典的なDNA二重らせんを安定化します。しかしある種のバクテリオファージ(細菌を感染させるウイルス)は、Aを2,6-ジアミノプリン(通称Z)に置き換える進化を遂げました。ZはTと三本の水素結合を形成し、らせん構造をより安定にし物理的性質を変化させます。この特異な化学的性質は、宿主の防御に対する優位性をウイルスに与えるかもしれず、性能の高い設計分子への応用の道を開きます。研究ではすでに、Zが遺伝子検査の精度向上、CRISPR遺伝子編集の反応調整、実験的RNA医薬への免疫反応の低減に役立つことが示されています。しかしZがDNA鎖のどこにあるかを正確に特定する方法がなければ、これらの利点を完全に理解し活用することは困難でした。
既存ツールの限界
標準的なDNAシーケンシング技術は、A様の信号をすべて本物のAと仮定するため、Zを普通のアデニンとして誤読する傾向があります。高性能液体クロマトグラフィーのような化学的手法はバルク中のZ量を検出できますが、ゲノム上の各Zがどこにあるか、特に多種が混ざった環境試料では特定できません。ナノポアのような第三世代シーケンス装置は理論的には塩基間の違いを検出し得ますが、実際には未知の化学変化があると信号がノイズに埋もれ解釈が困難です。これまで、複雑なDNA混合物を手軽かつ確実に走査して通常のDNAとZ含有DNAを明確に分離し、1塩基ずつAとZを識別する便利で信頼できる方法は存在しませんでした。
DNA合成の“リズム”を聴く
著者らはPacBioのCircular Consensus Sequencing(CCS)に着目しました。この技術は同じDNA分子を繰り返し複写し、どの塩基が入るかだけでなく各塩基の追加に要する速度も記録します。二つのタイミング測定—パルス幅(ポリメラーゼが塩基を加えるのに費やす時間)とインターパルス期間(追加間の一瞬の間隔)—は、DNA合成の一種のリズムトラックを形成します。通常のDNA、完全にZ置換されたDNA、AとZが共存するハイブリッド分子など、多数の設計サンプルを比較することで、AをZに置き換えるとわずかだが一貫したタイミングの変化が生じることが示されました。これらの変化は周辺の配列に依存し、主にZ位置周辺の狭い範囲でパルス幅に影響を与え、全体のシーケンシング精度は修飾のないDNAとほぼ同程度に保たれます。
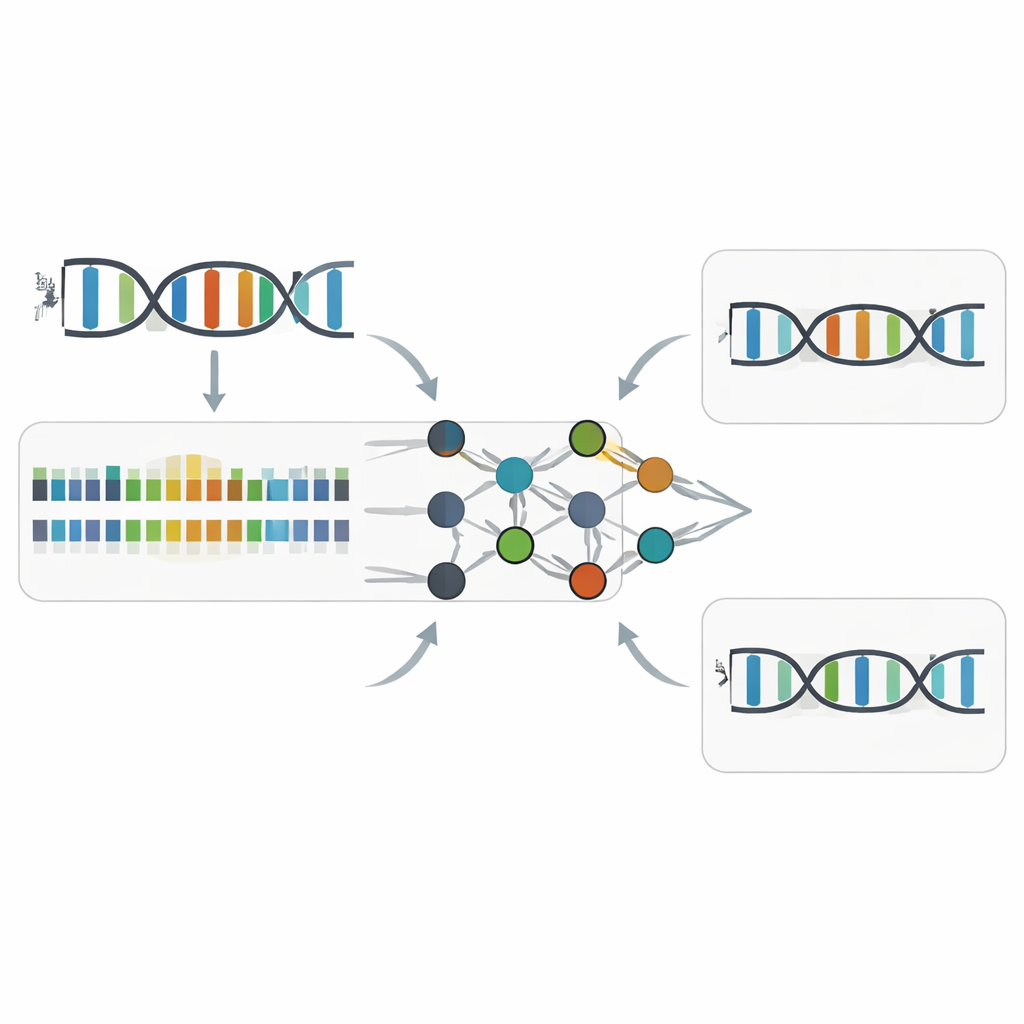
Z-Callingが隠れたZ塩基を見つける仕組み
これらのタイミングパターンに基づき、研究者らはZの動的な“アクセント”を認識する機械学習モデルを学習させました。ツールZ-Callingには二つの主要な役割があります。まず、個々のシーケンスリード全体を通常のDNAかZ含有DNAかに分類すること。これは、各A様位置がZである確率をニューラルネットワークでスコア化し、そのスコア分布をサポートベクターマシンに入力してリード全体がZ-DNA由来かどうかを判定することで行います。第二に、局所的な配列文脈と動力学信号に基づいて各位置をAまたはZに割り当てる一塩基判別を行います。細菌、酵母、植物、動物、そして自然にZを含むファージからのデータセット全体で、これらのモデルは高い精度(AUC値約0.94–0.98)を達成し、一般的なDNAメチル化マークを検出する先進的ツールと同等の性能を示しました。
実環境での評価
Z-Callingが単純な実験構築物を超えて機能することを示すため、著者らはアデニンを部分的にZに置き換えた設計酵母株に適用しました。化学解析は、A様位置の約4分の1がZに変わっていることを示しました。Z-Callingは独立して同様の割合を推定し、酵母染色体やプラスミド上にZが広くランダムに散在している様子をマップしました。ツールはまた、わずかな割合のリードのみがZ-DNAウイルスやハイブリッドゲノムに由来するような混合データセットも走査しました。Z含有リードが全体の約1%ほどしかない場合でも、Z-Callingは高い信頼度でその存在を検出でき、天然のエピジェネティックマークに富む多くの対照ゲノムでも誤報を極めて低く抑えました。
将来への意義
DNAシーケンシングにおける微妙なタイミングの揺らぎを明確な信号に変えることで、Z-Callingは塩基ごと・ゲノムごとにZ塩基の出現場所を体系的にマッピングする最初の実用的手段を提供します。一般読者にとって重要なメッセージは、私たちの遺伝のアルファベットはかつて考えられていたより柔軟であり、その最も興味深い代替文字の一つを高解像度で読み取る方法を今持っているということです。この能力は、自然界でさらなるZベースのウイルスを探索すること、安定性や新機能のためにZを利用する設計生物の検証、そして安全な情報保存や高度な治療法のための異種DNA様ポリマーの探求を支援します。要するに、Z-Callingは周縁的だった化学的興味を現実のゲノムの追跡可能な特徴へと変えます。
引用: Wu, B., Chen, Y., Zhou, Y. et al. Z-Calling: a tool for A/Z (2,6-diaminopurine) base calling and dZ-DNA detection using PacBio HiFi reads. Commun Biol 9, 594 (2026). https://doi.org/10.1038/s42003-026-09849-8
キーワード: Z- DNA, 非正準塩基, PacBioシーケンシング, 機械学習ゲノミクス, ファージゲノミクス