Clear Sky Science · en
Z-Calling: a tool for A/Z (2,6-diaminopurine) base calling and dZ-DNA detection using PacBio HiFi reads
Why a New Kind of DNA Matters
DNA is often described as the universal blueprint of life, built from four familiar letters: A, T, C and G. But some viruses quietly break this rule, swapping the letter A for a chemical cousin called Z that makes their DNA stronger and harder to attack. This discovery hints at a hidden layer of genetic diversity with big implications for biotechnology, medicine and even data storage. The challenge has been simple to state but hard to solve: how can scientists reliably find and map this unusual Z-DNA, especially when it is mixed with ordinary DNA? This study introduces Z-Calling, a computational tool that finally makes that possible using existing long-read sequencing technology.
A Strange Letter in the Genetic Alphabet
In most organisms, the base adenine (A) pairs with thymine (T) through two hydrogen bonds, helping stabilize the classic DNA double helix. Some bacteriophages—viruses that infect bacteria—have evolved to replace A with 2,6-diaminopurine, nicknamed Z. Z forms three hydrogen bonds with T, making the DNA helix more stable and altering its physical behavior. This unusual chemistry may give Z-containing viruses an edge against host defenses and opens doors to engineered molecules with better performance. Researchers have already shown that Z can sharpen genetic tests, tune CRISPR gene-editing reactions and reduce immune reactions to experimental RNA medicines. Yet, without a way to pinpoint exactly where Z sits in a DNA strand, it has been difficult to fully understand or harness these advantages.
Current Tools Fall Short
Standard DNA sequencing technologies assume that all A-like signals really are A, so they tend to misread Z as ordinary adenine. Chemical methods such as high-performance liquid chromatography can detect how much Z is present in bulk, but they cannot say where each Z is located along a genome, especially in tangled environmental samples that mix many species. Some third-generation sequencing platforms, like nanopore devices, are theoretically sensitive enough to feel the difference between bases, but in practice their signals can be noisy and hard to interpret when unfamiliar chemistry is present. Until now, there has been no convenient, reliable way to scan complex DNA mixtures and clearly separate normal DNA from Z-containing DNA, or to tell A and Z apart one letter at a time.
Listening to the Rhythm of DNA Synthesis
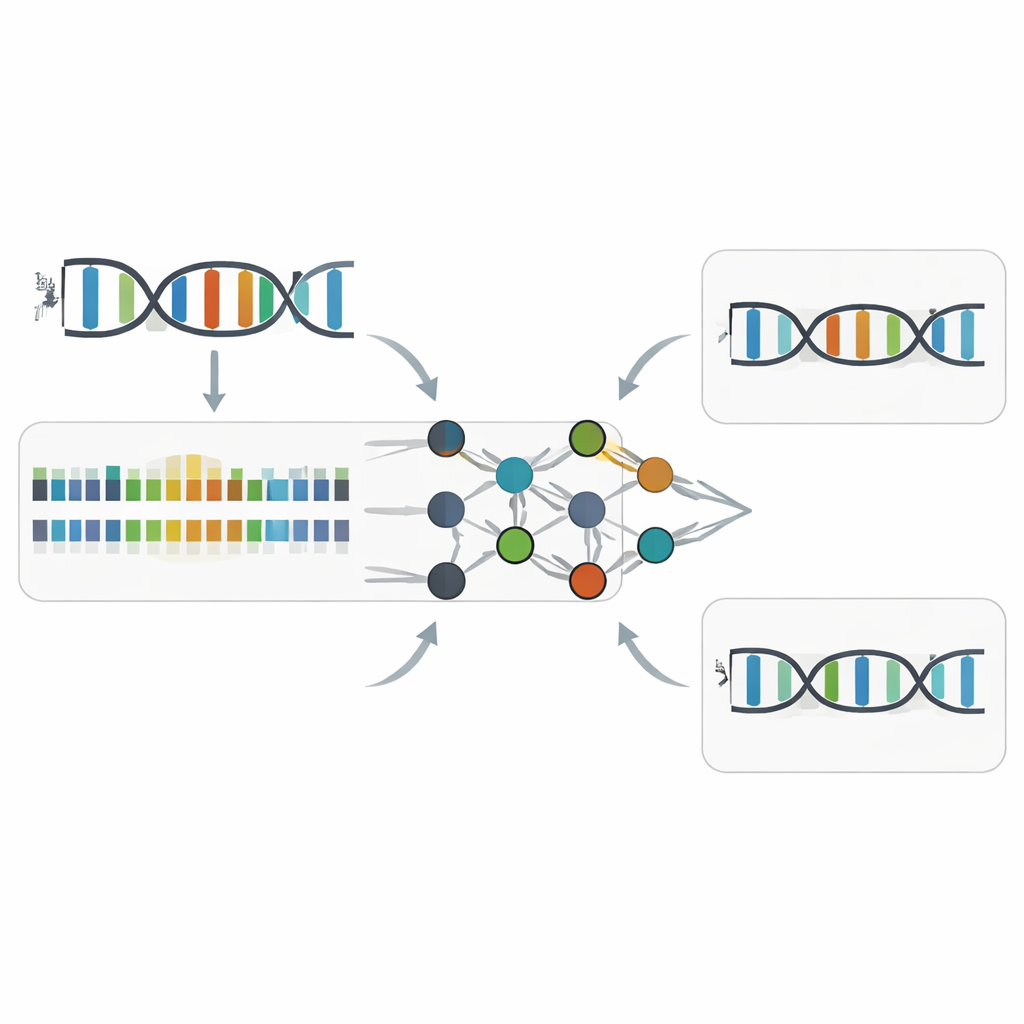
The authors focused on PacBio Circular Consensus Sequencing, a technology that repeatedly copies the same DNA molecule and records not just which base is added, but how fast each addition occurs. Two timing measurements—pulse width (how long the polymerase spends adding a base) and inter-pulse duration (the pause between additions)—form a kind of rhythm track for DNA synthesis. By comparing many carefully designed DNA samples, including ordinary DNA, fully Z-substituted DNA and hybrid molecules where A and Z coexist, the team showed that swapping A for Z creates subtle but consistent timing changes. These changes depend on the surrounding sequence, and they mainly affect pulse width within a narrow window around the Z site, while leaving overall sequencing accuracy almost as high as for unmodified DNA.
How Z-Calling Finds Hidden Z Bases
Building on these timing patterns, the researchers trained machine-learning models to recognize the kinetic “accent” of Z. Their tool, Z-Calling, has two main jobs. First, it classifies entire sequencing reads as either ordinary DNA or Z-containing DNA, even in artificial metagenomes that mix many species and chemistries. It does this by using a neural network to score how likely each A-like position is to be Z, then feeding the distribution of those scores into a support vector machine that decides whether the whole read comes from Z-DNA. Second, it performs single-letter discrimination, assigning each position to A or Z based on its local sequence context and kinetic signals. Across datasets from bacteria, yeast, plants, animals and a naturally Z-containing phage, these models reached high accuracy (area-under-curve values around 0.94–0.98), similar to leading tools that detect common DNA methylation marks.
Putting the Tool to Real-World Tests
To show that Z-Calling works beyond clean lab constructs, the authors applied it to an engineered yeast strain that partially replaces adenine with Z throughout its genome. Chemical analysis indicated that roughly a quarter of all A-like positions had become Z. Z-Calling independently estimated a similar fraction and mapped how Z was scattered across yeast chromosomes and plasmids, revealing a broadly random distribution. The tool also scanned mixed datasets in which only a tiny fraction of reads belonged to Z-DNA viruses or hybrid genomes. Even when Z-containing reads made up as little as about one percent of the total, Z-Calling could still flag their presence with high confidence, while keeping false alarms extremely rare across many control genomes rich in natural epigenetic marks.
What This Means for the Future
By turning subtle timing quirks in DNA sequencing into clear signals, Z-Calling provides the first practical way to systematically map where Z bases appear, base by base and genome by genome. For a general reader, the key message is that our genetic alphabet is more flexible than once thought, and we now have a way to read one of its most intriguing alternative letters at high resolution. This capability will help scientists hunt for more Z-based viruses in nature, validate engineered organisms that use Z for added stability or new functions, and explore exotic DNA-like polymers for secure information storage and advanced therapeutics. In short, Z-Calling transforms an obscure chemical curiosity into a trackable feature of real-world genomes.
Citation: Wu, B., Chen, Y., Zhou, Y. et al. Z-Calling: a tool for A/Z (2,6-diaminopurine) base calling and dZ-DNA detection using PacBio HiFi reads. Commun Biol 9, 594 (2026). https://doi.org/10.1038/s42003-026-09849-8
Keywords: Z-DNA, noncanonical bases, PacBio sequencing, machine learning genomics, phage genomics