Clear Sky Science · es
Z-Calling: una herramienta para la identificación de bases A/Z (2,6-diaminopurina) y la detección de dZ-ADN usando lecturas PacBio HiFi
Por qué importa un tipo nuevo de ADN
El ADN suele describirse como el plano universal de la vida, formado por cuatro letras familiares: A, T, C y G. Pero algunos virus rompen silenciosamente esa regla, sustituyendo la letra A por una prima química llamada Z que hace su ADN más resistente y más difícil de atacar. Este hallazgo sugiere una capa oculta de diversidad genética con grandes implicaciones para la biotecnología, la medicina e incluso el almacenamiento de datos. El reto ha sido sencillo de enunciar pero difícil de resolver: ¿cómo pueden los científicos localizar y cartografiar con fiabilidad este inusual ADN-Z, sobre todo cuando está mezclado con ADN corriente? Este estudio presenta Z-Calling, una herramienta computacional que finalmente lo hace posible usando la tecnología de lectura larga ya existente.
Una letra extraña en el alfabeto genético
En la mayoría de los organismos, la base adenina (A) se empareja con timina (T) mediante dos enlaces de hidrógeno, contribuyendo a estabilizar la clásica doble hélice del ADN. Algunos bacteriófagos —virus que infectan bacterias— han evolucionado para reemplazar A por 2,6-diaminopurina, apodada Z. Z forma tres enlaces de hidrógeno con T, haciendo la hélice más estable y alterando su comportamiento físico. Esta química inusual puede conferir a los virus que contienen Z una ventaja frente a las defensas del huésped y abre la puerta a moléculas diseñadas con mejor rendimiento. Los investigadores ya han mostrado que Z puede afinar pruebas genéticas, ajustar reacciones de edición génica CRISPR y reducir las respuestas inmunes a medicamentos experimentales basados en ARN. Sin embargo, sin una forma de precisar exactamente dónde se encuentra Z en una cadena de ADN, ha sido difícil comprender plenamente o aprovechar esas ventajas.
Las herramientas actuales se quedan cortas
Las tecnologías estándar de secuenciación presuponen que todas las señales parecidas a A son realmente A, por lo que tienden a leer Z como adenina ordinaria. Métodos químicos como la cromatografía líquida de alta resolución pueden detectar la cantidad de Z presente en masa, pero no pueden decir dónde está cada Z a lo largo de un genoma, especialmente en muestras ambientales complejas que mezclan muchas especies. Algunas plataformas de tercera generación, como los dispositivos de nanopore, son teóricamente lo bastante sensibles para notar la diferencia entre bases, pero en la práctica sus señales pueden ser ruidosas y difíciles de interpretar cuando hay química poco familiar. Hasta ahora no existía una manera práctica y fiable de rastrear mezclas complejas de ADN y separar claramente el ADN normal del que contiene Z, ni de distinguir A y Z una letra a la vez.
Escuchar el ritmo de la síntesis del ADN
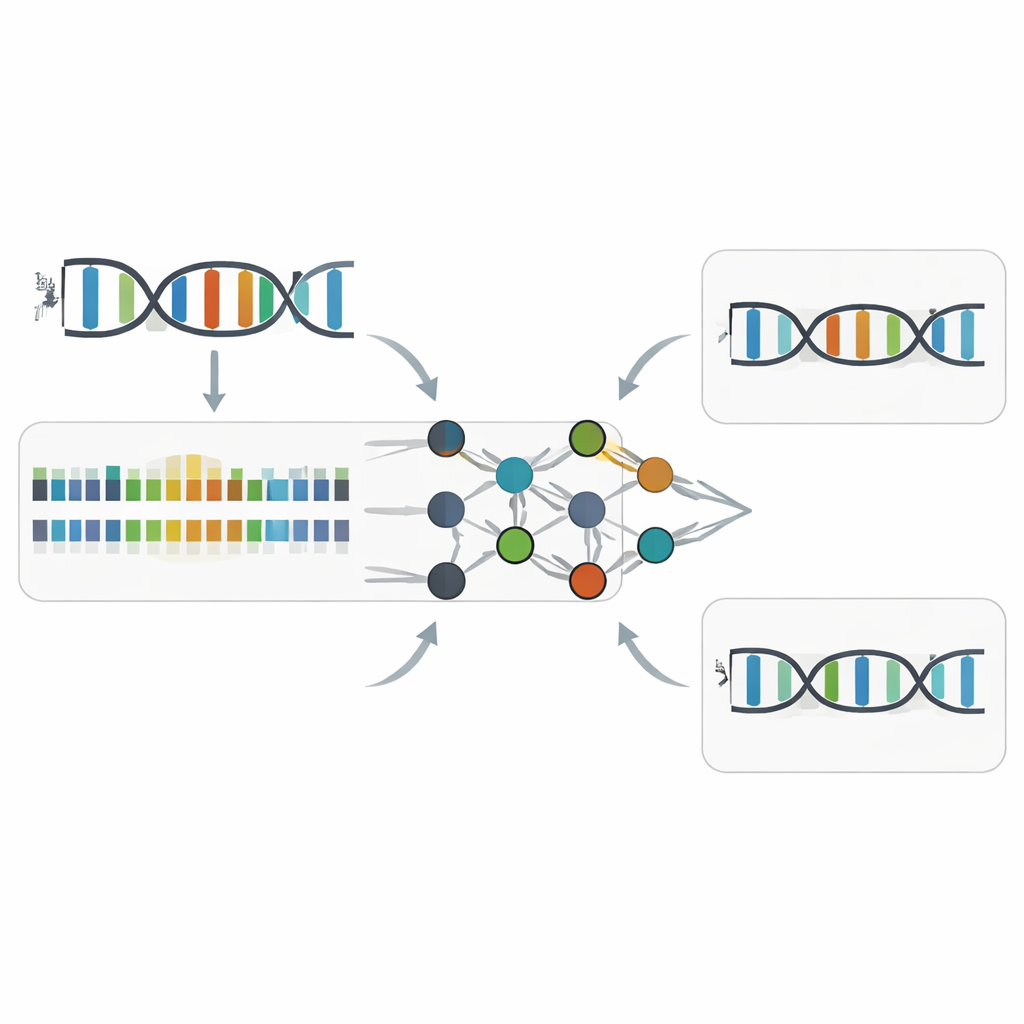
Los autores se centraron en PacBio Circular Consensus Sequencing, una tecnología que copia repetidamente la misma molécula de ADN y registra no solo qué base se añade, sino la velocidad de cada adición. Dos medidas temporales —la anchura del pulso (cuánto tiempo tarda la polimerasa en añadir una base) y la duración entre pulsos (la pausa entre adiciones)— forman una especie de pista rítmica de la síntesis del ADN. Comparando muchas muestras de ADN cuidadosamente diseñadas, incluyendo ADN ordinario, ADN totalmente sustituido por Z y moléculas híbridas donde A y Z coexisten, el equipo mostró que sustituir A por Z crea cambios temporales sutiles pero consistentes. Estos cambios dependen de la secuencia circundante y afectan principalmente a la anchura del pulso dentro de una ventana estrecha alrededor del sitio Z, sin disminuir apenas la precisión global de la secuenciación respecto al ADN no modificado.
Cómo Z-Calling encuentra las bases Z ocultas
Partiendo de estos patrones temporales, los investigadores entrenaron modelos de aprendizaje automático para reconocer el “acento” cinético de Z. Su herramienta, Z-Calling, tiene dos funciones principales. Primero, clasifica lecturas de secuencia completas como ADN ordinario o ADN que contiene Z, incluso en metagenomas artificiales que mezclan muchas especies y químicas. Lo hace usando una red neuronal para puntuar la probabilidad de que cada posición parecida a A sea Z, y luego alimentando la distribución de esas puntuaciones a una máquina de soporte vectorial que decide si la lectura entera proviene de ADN-Z. Segundo, realiza la discriminación letra a letra, asignando cada posición a A o Z según su contexto de secuencia local y las señales cinéticas. En conjuntos de datos de bacterias, levaduras, plantas, animales y un fago que naturalmente contiene Z, estos modelos alcanzaron alta precisión (valores de área bajo la curva alrededor de 0,94–0,98), similares a las herramientas líderes que detectan marcas comunes de metilación del ADN.
Probar la herramienta en el mundo real
Para demostrar que Z-Calling funciona más allá de constructos de laboratorio limpios, los autores lo aplicaron a una cepa de levadura modificada que sustituye parcialmente adenina por Z en todo su genoma. El análisis químico indicó que aproximadamente una cuarta parte de todas las posiciones parecidas a A se habían convertido en Z. Z-Calling estimó de forma independiente una fracción similar y cartografió cómo se distribuía Z por los cromosomas y plásmidos de la levadura, revelando una distribución generalmente aleatoria. La herramienta también examinó conjuntos de datos mixtos en los que solo una pequeña fracción de lecturas pertenecía a virus con ADN-Z o genomas híbridos. Incluso cuando las lecturas que contenían Z representaban apenas alrededor del uno por ciento del total, Z-Calling pudo detectar su presencia con alta confianza, manteniendo las falsas alarmas extremadamente raras en muchos genomas de control ricos en marcas epigenéticas naturales.
Qué significa esto para el futuro
Al convertir peculiaridades temporales sutiles de la secuenciación del ADN en señales claras, Z-Calling ofrece la primera forma práctica de cartografiar sistemáticamente dónde aparecen las bases Z, base por base y genoma por genoma. Para un lector general, el mensaje clave es que nuestro alfabeto genético es más flexible de lo que se pensaba y que ahora disponemos de una manera para leer una de sus letras alternativas más intrigantes con alta resolución. Esta capacidad ayudará a los científicos a buscar más virus basados en Z en la naturaleza, validar organismos diseñados que usan Z para mayor estabilidad o nuevas funciones, y explorar polímeros exóticos similares al ADN para almacenamiento seguro de información y terapias avanzadas. En resumen, Z-Calling transforma una curiosidad química oscura en una característica rastreable de genomas del mundo real.
Cita: Wu, B., Chen, Y., Zhou, Y. et al. Z-Calling: a tool for A/Z (2,6-diaminopurine) base calling and dZ-DNA detection using PacBio HiFi reads. Commun Biol 9, 594 (2026). https://doi.org/10.1038/s42003-026-09849-8
Palabras clave: ADN-Z, bases no canónicas, secuenciación PacBio, aprendizaje automático genómico, genómica de fagos