Clear Sky Science · nl
MIrROR release 02: Uitgebreide en verfijnde 16S-ITS-23S rRNA-operon dataset
Waarom kleine microben belangrijk voor ons zijn
Microben vormen onze gezondheid, onze omgeving en zelfs het klimaat, maar precies vaststellen welke microscopische soorten aanwezig zijn in een bodemmonster, een rivier of de menselijke darm is verrassend moeilijk. Dit artikel introduceert een verbeterde referentiedataset genaamd MIrROR release 02, die wetenschappers helpt lange stukken microbieel DNA nauwkeuriger te lezen zodat ze nauw verwante soorten van elkaar kunnen onderscheiden en beter kunnen begrijpen hoe microbiele gemeenschappen functioneren.
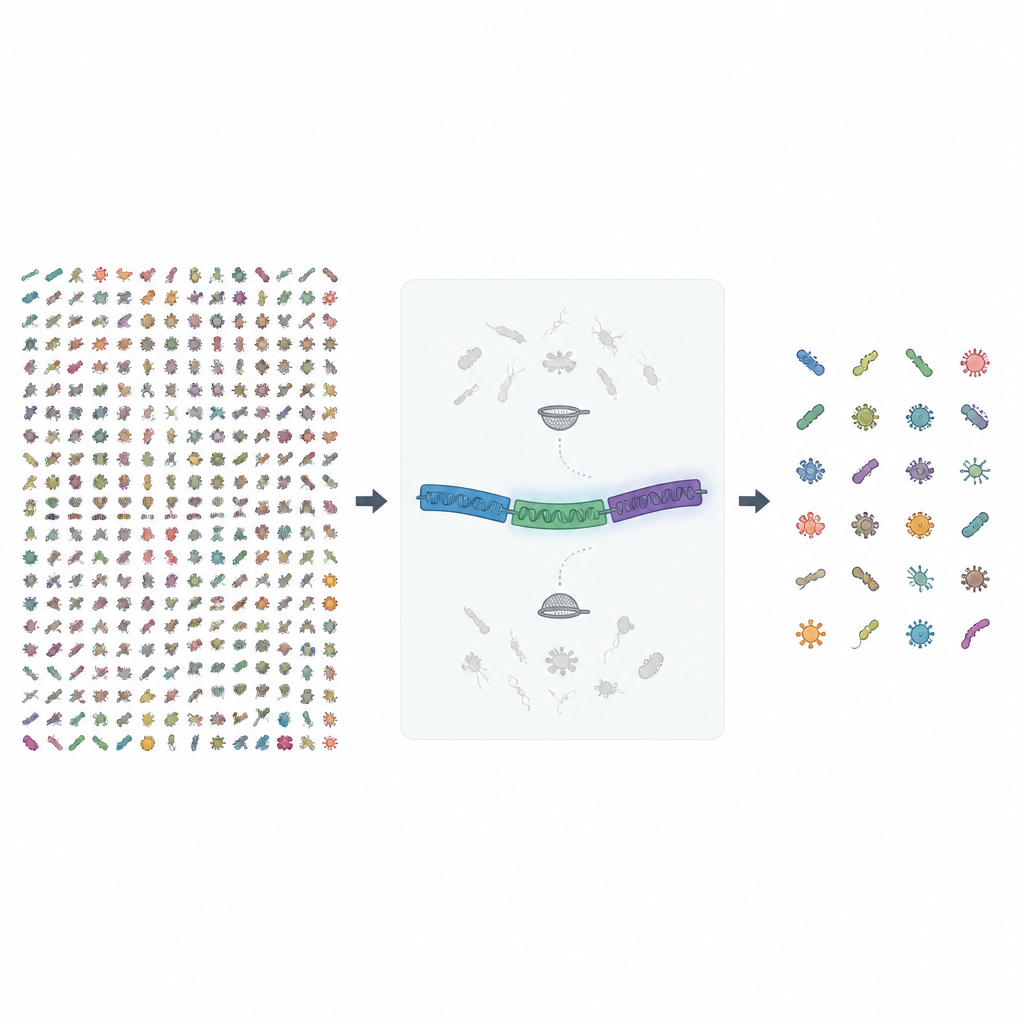
Voorbij een enkel genetisch herkenningspunt kijken
Jarenlang vertrouwden microbiologen op korte fragmenten van één gen, bekend als 16S rRNA, om bacteriën en archaea in een monster te detecteren en te tellen. Die methode is snel en goedkoop, maar vervaagt vaak het beeld en behandelt verschillende soorten alsof ze hetzelfde waren. Zelfs met nieuwere long-read sequencingapparaten die het volledige 16S-gen kunnen lezen, blijven sommige soorten ononderscheidbaar omdat dit gen te vergelijkbaar is bij nauwe verwanten. Het MIrROR-project pakt dit aan door een langere DNA-streek te gebruiken die het volledige rRNA-operon bestrijkt, inclusief 16S, een spacer-regio en een ander rRNA-gen genaamd 23S, waardoor veel meer sequentiedetails beschikbaar zijn om gelijkende microben uit elkaar te houden.
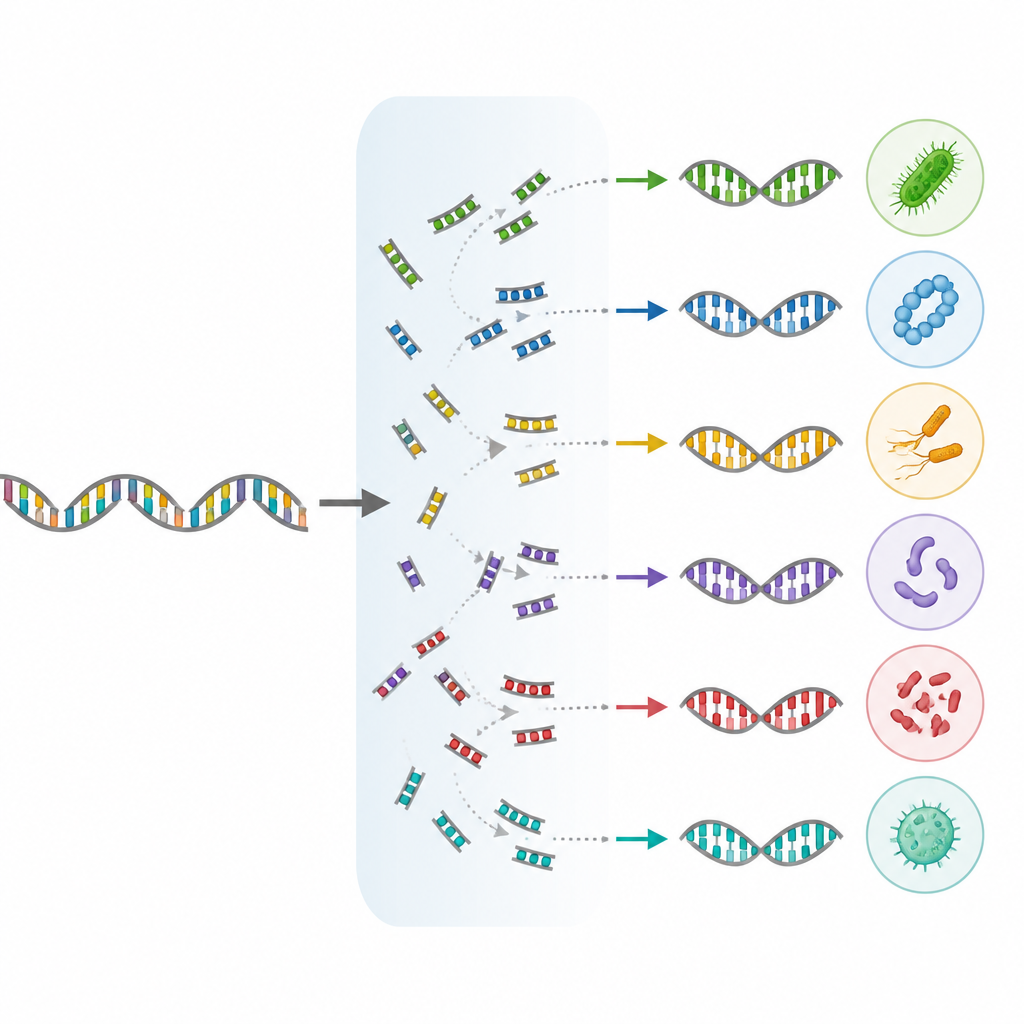
Een grotere en schonere referentiekaart opbouwen
In deze nieuwe release verzamelden de auteurs bijna 1,7 miljoen bacteriële en archaeale genomen uit een openbaar archief en doorzochten deze op complete rRNA-operonsequenties van redelijke lengte. Ze hebben deze ruwe sequenties vervolgens door meerdere rondes van kwaliteitscontroles gehaald. Genomen zonder heldere soortnaam werden verwijderd, exacte duplicaten tussen soorten werden weggehaald en sequenties met te veel onzekere DNA-letters werden gefilterd. Ten slotte werden zeer vergelijkbare sequenties geclusterd en groepen die soorten mengden zorgvuldig geïnspecteerd en opgeschoond, inclusief handmatige controles met sequentievergelijking en fylogenetische boomconstructietools om contaminatie uit te sluiten.
Verwaarloosde takken van de levensboom toevoegen
Een belangrijke vooruitgang in MIrROR release 02 is de opname van archaea, een brede groep microben die gedijen in omgevingen variërend van warmwaterbronnen tot de menselijke darm. De dataset bestrijkt nu meer dan duizend archaeale soorten, waaronder organismen die medisch en industrieel belangrijk zijn. Tegelijkertijd werkten de auteurs de namen en groeperingen van veel microben bij met een moderne genoomgebaseerde taxonomie. Deze herclassificatie trof ongeveer de helft van alle genomen in de dataset en voegde bijna negentienduizend extra bacteriële soorten toe, waaronder zeldzame milieu-microben, klinisch relevante ziekteverwekkers en soorten van belang voor biotechnologie en voedselproductie.
Long-read onderzoeken toepasbaar maken in echte en testgemeenschappen
Om aan te tonen dat de uitgebreide dataset niet alleen groter maar ook nuttiger is, testte het team deze op zowel laboratorium gemaakte als computergesimuleerde microbiële mengsels. Ze vergeleken MIrROR release 02 met eerdere MIrROR-gegevens en met andere veelgebruikte referentiecollecties. In gecontroleerde tests was de nieuwe dataset beter in het nauwkeurig lokaliseren van soorten, inclusief soorten die oudere datasets volledig misten, zoals een bepaalde Prevotella-soort in een darmcommunity-standaard. Wanneer archaeale soorten werden toegevoegd aan een gesimuleerde darmgemeenschap, kon de nieuwe MIrROR-versie ze detecteren en classificeren op zowel genus- als soortniveau, terwijl een veelgebruikte 16S-enkel referentie vaak vage labels produceerde zoals onverklaarde bacteriën en moeite had om lezingen aan de juiste soort toe te wijzen.
Wetenschappers helpen de juiste tools te kiezen
Omdat long-read sequencing afhankelijk is van specifieke DNA-startpunten genaamd primers, onderzochten de auteurs ook verschillende primerparen in computersimulaties om te zien welke zowel bacteriën als archaea het beste over het volledige operon konden vastleggen. Ze bevelen twee primerparen aan die een balans vinden tussen brede dekking en compatibiliteit met long-read platformen. Tegelijk wijzen ze op bekende biologische eigenaardigheden, zoals microben die hun rRNA-genen niet gekoppeld houden of in meerdere iets verschillende kopieën hebben, wat tellingen kan bevoordelen en waarmee rekening moet worden gehouden bij het interpreteren van gemeenschapsdata.
Wat dit betekent voor alledaagse vragen
In simpele termen is MIrROR release 02 een veel grotere, beter georganiseerde adresgids voor microben, gebouwd om te werken met moderne long-read DNA-sequencing. Het stelt wetenschappers in staat gelijkende soorten betrouwbaarder te scheiden, archaea in hun onderzoeken op te nemen en resultaten tussen verschillende studies met meer vertrouwen te vergelijken. Hoewel het niet alle uitdagingen bij het lezen van microbiele gemeenschappen wegneemt, geeft het onderzoekers een scherpere lens om te verkennen hoe microben de menselijke gezondheid, ecosystemen en industriële processen beïnvloeden.
Bronvermelding: Lee, J., Hong, J., Seol, D. et al. MIrROR release 02: Expanded and refined 16S-ITS-23S rRNA operon dataset. Sci Data 13, 714 (2026). https://doi.org/10.1038/s41597-026-06729-y
Trefwoorden: microbioom, rRNA-operon, long-read sequencing, microbiële taxonomie, archaea