Clear Sky Science · fr
Comprendre le « code » languistique sous-jacent qui régit les interactions non covalentes π–π entre protéines et ADN
Comment les protéines lisent l’ADN sans s’y fixer définitivement
Chaque seconde, d’innombrables protéines de nos cellules doivent localiser et lire des « mots » précis dans le « manuel » d’ADN. Elles le font sans se lier ou couper définitivement l’ADN, en s’appuyant sur des attractions fugitives entre molécules. Cet article explore l’une des forces subtiles les plus importantes : un type particulier d’interaction d’empilement entre parties planes et annulaires des protéines et les bases de l’ADN. Les auteurs soutiennent que ces contacts se comportent comme un code simple et répétable qui aide les protéines à reconnaître des séquences d’ADN, et ils expliquent ce code à l’aide d’idées venant de la physique quantique.
Le magnétisme discret des anneaux plans
Tant les bases de l’ADN que plusieurs acides aminés dans les protéines possèdent des structures plates en anneau dont les électrons sont délocalisés sur l’ensemble de l’anneau. Quand deux anneaux de ce type se superposent face à face et légèrement décalés, ils peuvent s’attirer via ce que les chimistes appellent des interactions π–π. Des travaux antérieurs ont montré que ces contacts peuvent être presque aussi forts que des liaisons hydrogène et sont fréquents aux interfaces protéine–ADN. Dans cette étude, les auteurs se concentrent sur les anneaux de type benzène présents dans des acides aminés aromatiques tels que la phénylalanine, la tyrosine et le tryptophane, et sur la manière dont ils s’empilent contre les anneaux des quatre bases de l’ADN. Ils avancent que ces empilements font plus que coller des molécules : ils forment une interaction structurée et directionnelle capable de porter de l’information sur l’identité de la base présente.
Une prise cohérente sur de nombreuses « lettres » de l’ADN
En examinant la géométrie de ces empilements, les auteurs identifient un motif récurrent. Pour les bases d’ADN plus volumineuses (adénine et guanine, dites purines), la configuration la plus stable place l’anneau benzénique de la protéine parallèle à la base de sorte que deux positions spécifiques sur la base (appelées N3 et C2) se trouvent sous deux carbones particuliers (C1 et C2) du benzène. Pour les bases plus petites (thymine et cytosine, dites pyrimidines), les mêmes atomes du benzène s’alignent plutôt au-dessus de deux carbones appelés C5 et C6 dans la base. Dans tous les cas, les anneaux adoptent une disposition parallèle mais décalée horizontalement, semblable à deux pièces qui se recouvrent légèrement. Cet alignement répété suggère une sorte « d’alphabet » structural : l’anneau benzénique reste constant, tandis que chaque base présente son propre motif de zones riches en électrons à ce cadre fixe.
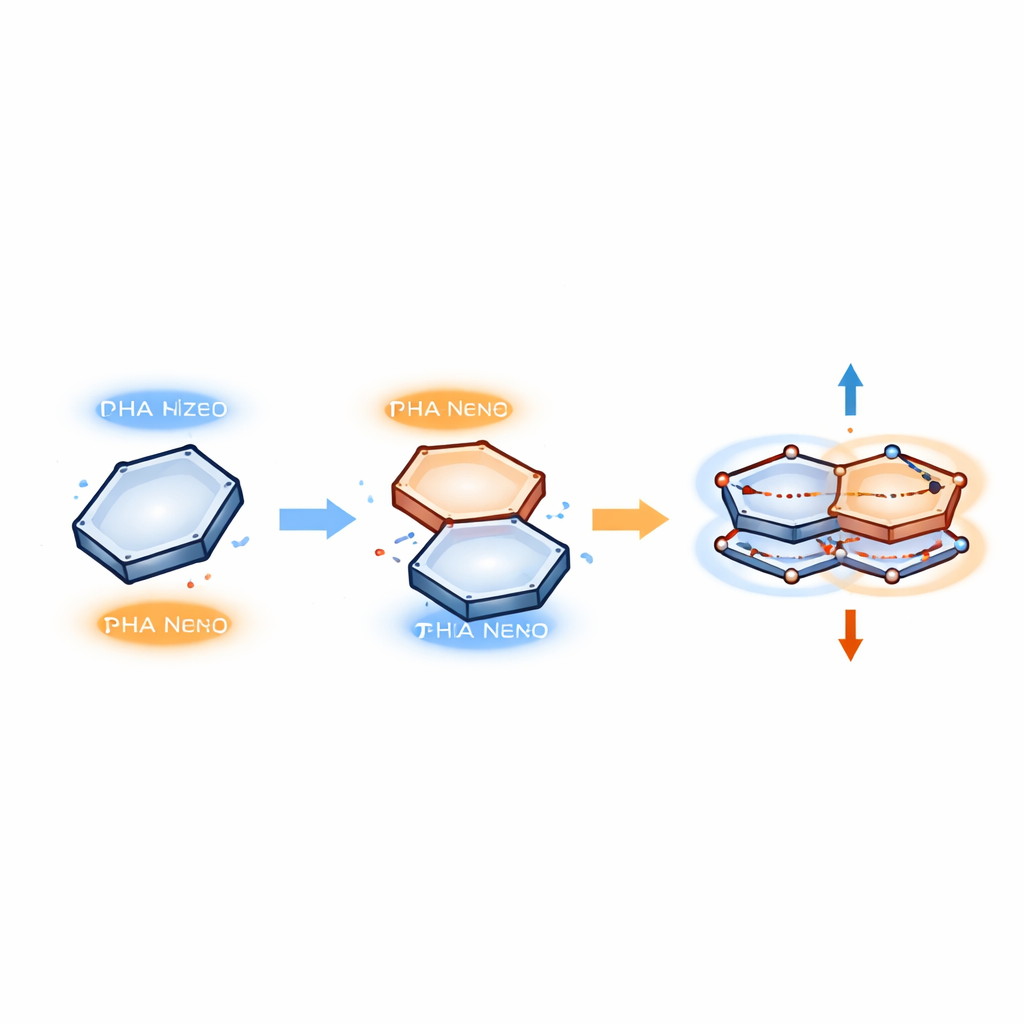
Des paires d’électrons qui oscillent comme de minuscules ressorts
Pour décrire ce qui se passe à l’intérieur de ces empilements, les auteurs utilisent un modèle où les électrons se déplacent par paires corrélées qui oscillent entre les deux anneaux. Plutôt que de former une nouvelle liaison chimique, un électron saute temporairement d’une région occupée d’un anneau vers une région vide (un « trou ») de l’autre, puis revient. Ces mouvements appariés sont traités comme des états quantiques résonants, un peu comme deux masses reliées par un ressort qui vibrent en phase. Dans le modèle, seuls deux ingrédients clés importent : la répulsion entre électrons et leur couplage aux vibrations de la molécule. Lorsque l’anneau benzénique est déplacé de façon adéquate au-dessus d’une base particulière, ces ingrédients se combinent pour créer un motif stable de mouvements appariés qui relie les deux anneaux sans rompre leurs structures d’origine.
Du mouvement quantique à une force mesurable
Parce que ces paires d’électrons se déplacent de manière régulière et oscillatoire, les auteurs peuvent estimer la force qui maintient les anneaux ensemble en utilisant un outil de la mécanique quantique connu sous le nom de théorème de Hellmann–Feynman. Ce théorème relie les changements d’énergie aux forces entre particules, un peu comme étirer un ressort emmagasine de l’énergie et crée une force de rappel. Dans les empilements π–π, l’énergie des paires d’électrons corrélées dépend de la distance entre les anneaux et de l’amplitude des oscillations électroniques. La dérivée de cette énergie par rapport à la distance fournit une force effective qui maintient les anneaux à un décalage et une séparation préférentiels — assez forte pour stabiliser des complexes protéine–ADN, mais assez faible pour rester réversible lorsque le complexe doit se dissocier.
Un code simple pour une reconnaissance souple de l’ADN
Globalement, le travail suggère que les protéines exploitent une conception robuste et réutilisable : un anneau benzénique constant dans l’acide aminé aromatique et une base d’ADN variable qui offre des paysages électroniques différents. L’anneau benzénique fournit le cadre stable nécessaire à la formation de ces paires d’électrons oscillantes, tandis que la base détermine exactement où et avec quelle intensité elles se forment. Cela donne aux protéines une manière non permanente mais spécifique de « sentir » quelle base elles contactent, les aidant à reconnaître des séquences cibles au sein du vaste génome. En termes simples, les interactions π–π permettent aux protéines d’apposer une tête de lecture de forme standard contre différentes « lettres » de l’ADN et d’en percevoir l’identité par un contact finement réglé, à l’échelle quantique.
Citation: Riera Aroche, R., Ortiz García, Y.M., Riera Leal, L. et al. Understanding the underlying language code that governs the π–π non-covalent interactions between proteins and DNA. Sci Rep 16, 14361 (2026). https://doi.org/10.1038/s41598-026-44532-2
Mots-clés: interactions protéine–ADN, acides aminés aromatiques, empilement π–π, reconnaissance de l’ADN, biologie quantique