Clear Sky Science · fr
Des tests systématiques montrent que les grands modèles de langage n’ont pas atteint la précision diagnostique des outils traditionnels d’aide au diagnostic des maladies rares
Pourquoi cela compte pour les patients et les médecins
Lorsqu’une personne souffre d’une maladie rare, obtenir le bon diagnostic peut prendre des années d’incertitude, d’examens répétés et de consultations chez de nombreux spécialistes. Parallèlement, de puissants nouveaux systèmes d’intelligence artificielle appelés grands modèles de langage sont présentés comme des révolutions potentielles pour la médecine. Cette étude pose une question simple mais cruciale : ces nouveaux chatbots d’IA sont‑ils réellement meilleurs pour repérer les maladies génétiques rares que les outils spécialisés déjà utilisés par les médecins, ou leur reste‑t‑il un chemin à parcourir ?
Les maladies rares et le long chemin vers une réponse
Bien que chaque maladie rare touche relativement peu de personnes, il en existe plus de 10 000, et elles concernent ensemble jusqu’à une personne sur douze. Beaucoup de ces patients endurent une « odyssée diagnostique » de cinq à sept ans avant que quelqu’un ne puisse nommer le problème. Pour les affections génétiques, une étape clé consiste à faire correspondre la combinaison de symptômes, les résultats de laboratoire et les données d’imagerie d’une personne aux schémas connus de maladies spécifiques. Des programmes informatiques établis aident déjà à cela en utilisant des vocabulaires standardisés de caractéristiques médicales pour parcourir des milliers de conditions possibles.
Mettre les chatbots et les outils traditionnels à l’épreuve
Les chercheurs ont rassemblé une grande collection de plus de cinq mille cas réels mais anonymisés de patients atteints de maladies génétiques ou chromosomiques confirmées. Chaque cas avait été soigneusement converti en un format structuré codant l’âge, le sexe, les symptômes et les résultats des tests de la personne à l’aide d’un dictionnaire médical commun. À partir de ces dossiers structurés, l’équipe a automatiquement généré de courtes histoires de cas pouvant être soumises à sept modèles de langage différents, incluant des systèmes à usage général et des modèles entraînés spécifiquement sur des textes médicaux. En parallèle, ils ont fourni les mêmes données structurées à Exomiser, un programme d’aide au diagnostic des maladies rares largement utilisé, mais sans lui donner d’informations de séquençage génétique afin que la comparaison soit équitable.
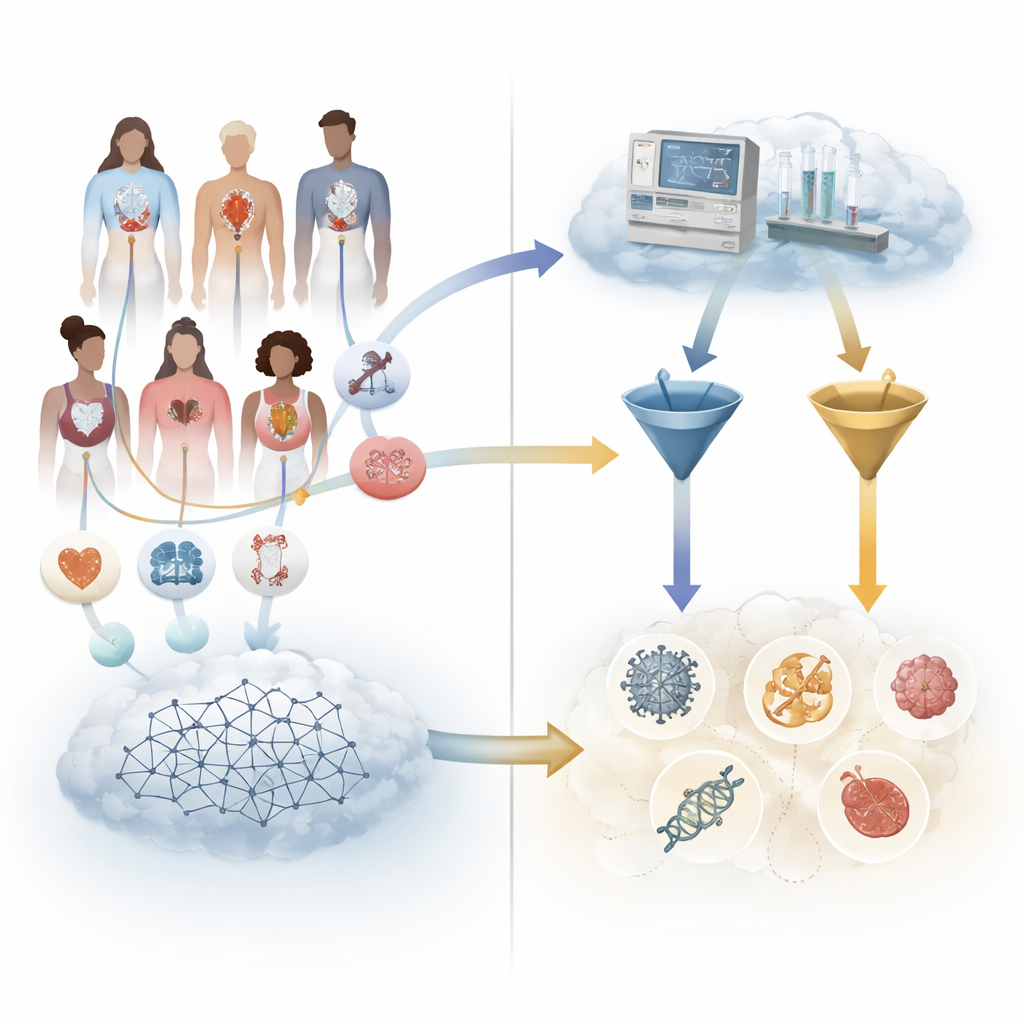
Évaluer qui a trouvé la bonne maladie
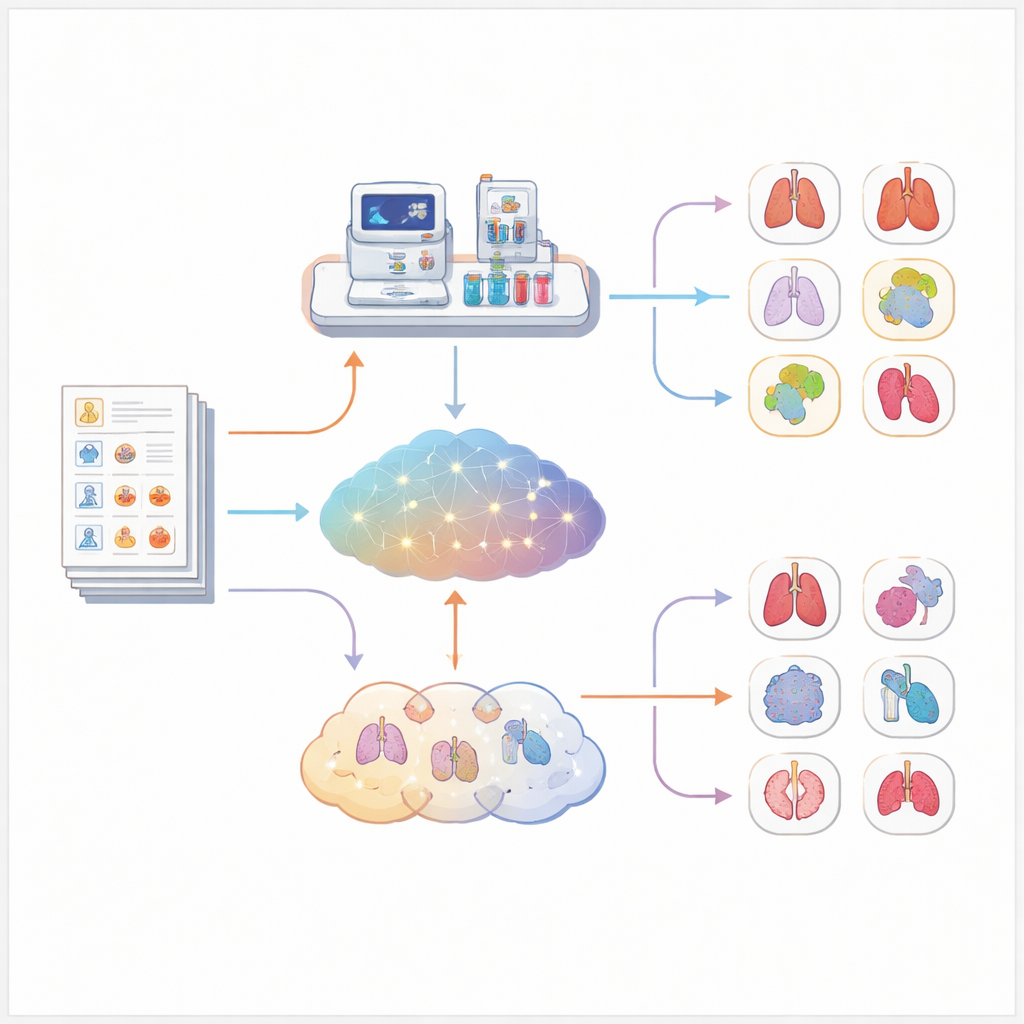
Comparer les réponses des chatbots et des logiciels traditionnels est plus difficile qu’il n’y paraît, car les modèles de langage répondent en texte libre qui peut utiliser des noms de maladies différents ou des niveaux de détail variés. Pour éviter de s’appuyer sur l’opinion humaine quant à savoir si une réponse était « suffisamment proche », l’équipe a cartographié chaque diagnostic suggéré sur un catalogue unifié de maladies. La suggestion d’un modèle était considérée comme correcte si elle correspondait à la maladie exacte, à un nom équivalent ou à une version légèrement plus générale qui incluait clairement la condition réelle. Pour chaque cas, ils ont ensuite mesuré à quel rang la bonne réponse apparaissait dans la liste classée du modèle : première place, parmi les trois premiers, ou quelque part dans le top dix.
Ce que la comparaison directe a montré
Sur les 5 213 cas, Exomiser a clairement surpassé tous les modèles de langage testés. En n’utilisant que les informations symptomatiques, Exomiser a placé le bon diagnostic en première position dans environ un cas sur trois et dans le top dix dans bien plus de la moitié des cas. Le meilleur modèle de langage, un système axé sur le raisonnement, a atteint la première place dans un peu moins d’un quart des cas et le top dix dans un peu plus d’un tiers. D’autres modèles orientés médical ont fait sensiblement pire, et un très grand modèle médical a presque jamais suggéré la bonne maladie. Ces tendances se sont maintenues même lorsque les chercheurs ont examiné séparément les troubles cardiaques, neurologiques ou immunitaires, et lorsqu’ils ont séparé les cas selon le niveau de détail des descriptions symptomatiques.
Ce que cela signifie pour l’avenir de l’IA en diagnostic
Cette étude montre que, malgré leurs capacités linguistiques impressionnantes, les grands modèles de langage actuels ne sont pas encore aussi fiables que les outils spécialisés pour diagnostiquer des maladies génétiques rares à partir des seules descriptions de symptômes. Ils peuvent néanmoins rester utiles en tant qu’assistants — par exemple pour aider les médecins à envisager des possibilités ou à expliquer des affections en termes simples — mais ils ne doivent pas remplacer les logiciels établis lorsque des vies et des réponses longtemps retardées sont en jeu. Les auteurs soutiennent que la voie la plus prometteuse consiste à intégrer les modèles de langage dans des chaînes diagnostiques soigneusement conçues, où ils travaillent aux côtés des outils bioinformatiques de confiance, et non en remplacement.
Citation: Reese, J.T., Chimirri, L., Bridges, Y. et al. Systematic benchmarking demonstrates large language models have not reached the diagnostic accuracy of traditional rare-disease decision support tools. Eur J Hum Genet 34, 498–504 (2026). https://doi.org/10.1038/s41431-026-02054-5
Mots-clés: maladies rares, diagnostic médical, grands modèles de langage, aide à la décision clinique, troubles génétiques