Clear Sky Science · de
Echos der Macht: Untersuchung geopolitischer Voreingenommenheit in großen Sprachmodellen aus den USA und China
Warum das für Alltagsleser wichtig ist
Wenn Sie einen KI-Chatbot nach Weltereignissen fragen, nehmen Sie vielleicht an, er sei neutral. Dieses Papier zeigt jedoch, dass Antworten führender Systeme aus den Vereinigten Staaten und China stillschweigend in Richtung der politischen Sichtweisen ihrer Herkunftsländer tendieren können. Zu verstehen, wie diese verborgenen Neigungen entstehen und wie stark sie sind, hilft Bürgern, Journalisten und Entscheidungsträgern einzuschätzen, wann man KI vertrauen kann und wann man ihre Aussagen kritisch betrachten sollte.
Wie die Forschenden die Chatbots getestet haben
Die Autorinnen und Autoren verglichen zwei fortschrittliche Chatbots: GPT-4o von OpenAI aus den USA und DeepSeek-R1 eines chinesischen Unternehmens. Sie erstellten einen Satz von 50 Fragen zu globaler Politik, Kriegen, Menschenrechten und umstrittenen Regionen, die den Arten von Anfragen ähneln, die Menschen in sozialen Medien und Foren stellen. Alle Fragen wurden in Englisch über die öffentlichen Weboberflächen beider Werkzeuge gestellt, mit einfachen, einmaligen Prompts wie von regulären Nutzerinnen und Nutzern. Der vollständige Datensatz von Fragen und Antworten wurde anschließend offen geteilt, um künftige Studien zu unterstützen.
Was sie in den Antworten gemessen haben
Um über grobe Eindrücke hinauszugehen, kombinierte das Team numerische und menschliche Analyseverfahren. Zuerst wandelten sie jede Antwort in eine numerische Repräsentation um, die ihre Bedeutung erfasst, und maßen dann, wie nah oder fern die beiden Systeme für jede Frage lagen. Zweitens baten sie die Modelle, einzuschätzen, wie stark US- und chinesische Standpunkte bei denselben Fragen divergieren könnten. Drittens untersuchten sie die Texte von Hand und achteten dabei auf Tonfall, Wahl der Beispiele und welche Fakten hervorgehoben oder abgeschwächt wurden. Diese Mischung aus Werkzeugen erlaubte es ihnen, sowohl offene Meinungsverschiedenheiten als auch subtilere Verschiebungen in der Rahmung zu erkennen.
Worüber die Chatbots einig waren und worüber nicht
Überraschenderweise lieferten die beiden Systeme häufig weitgehend ähnliche Antworten, selbst zu kontroversen Themen wie Klimaverantwortung, dem Ursprung der COVID-19-Pandemie oder dem Erbe des Nationalsozialismus. Beide neigten dazu, ausgewogene Übersichten zu geben und extreme Behauptungen zu vermeiden. Dennoch traten wesentliche Unterschiede zutage. GPT-4o zeigte, was die Autorinnen und Autoren als „weiche“ westlich-zentrierte Voreingenommenheit bezeichnen, etwa indem es liberale demokratische Ideen oder die Rolle der NATO und der Vereinten Nationen in seinen Erklärungen hervorhob. DeepSeek hingegen spiegelte teilweise eher direkt staatliche Narrative Chinas wider und verweigerte in einigen Fällen Antworten zu Themen, die in China hochsensibel sind, etwa zum Status Taiwans oder zu spezifischen innerstaatlichen Kontroversen. Diese Verweigerungen wurden auf der Ebene der Weboberfläche als harte Sperren umgesetzt und nicht bloß als Lücken in den Fähigkeiten des Modells. 
Versteckte Lenkungen in der Darstellung von Geschichten
Die Studie betont, dass der besorgniserregendste Einfluss nicht unbedingt offensichtliche Zensur ist, sondern sanftes Steuern. In einigen Antworten stimmten beide Modelle in den Grundfakten überein, rahmten diese jedoch unterschiedlich: Das eine könnte individuelle Freiheiten und Wahlkampf betonen, das andere Stabilität, Souveränität oder das Kollektivwohl hervorheben. Mit der Zeit kann eine solche weiche Verzerrung das, was Nutzerinnen und Nutzer als „common sense“ empfinden, formen — besonders wenn sie den Chatbot als neutralen Helfer ansehen. Da bereits mehr als die Hälfte der erwachsenen US-Bevölkerung solche Werkzeuge nutzt und ältere Menschen gegenüber irreführenden Informationen besonders anfällig sind, könnten selbst kleine, wiederholte Anstöße die öffentliche Meinung zu Kriegen, Handelsstreitigkeiten oder Menschenrechten verschieben, ohne dass es breit wahrgenommen wird. 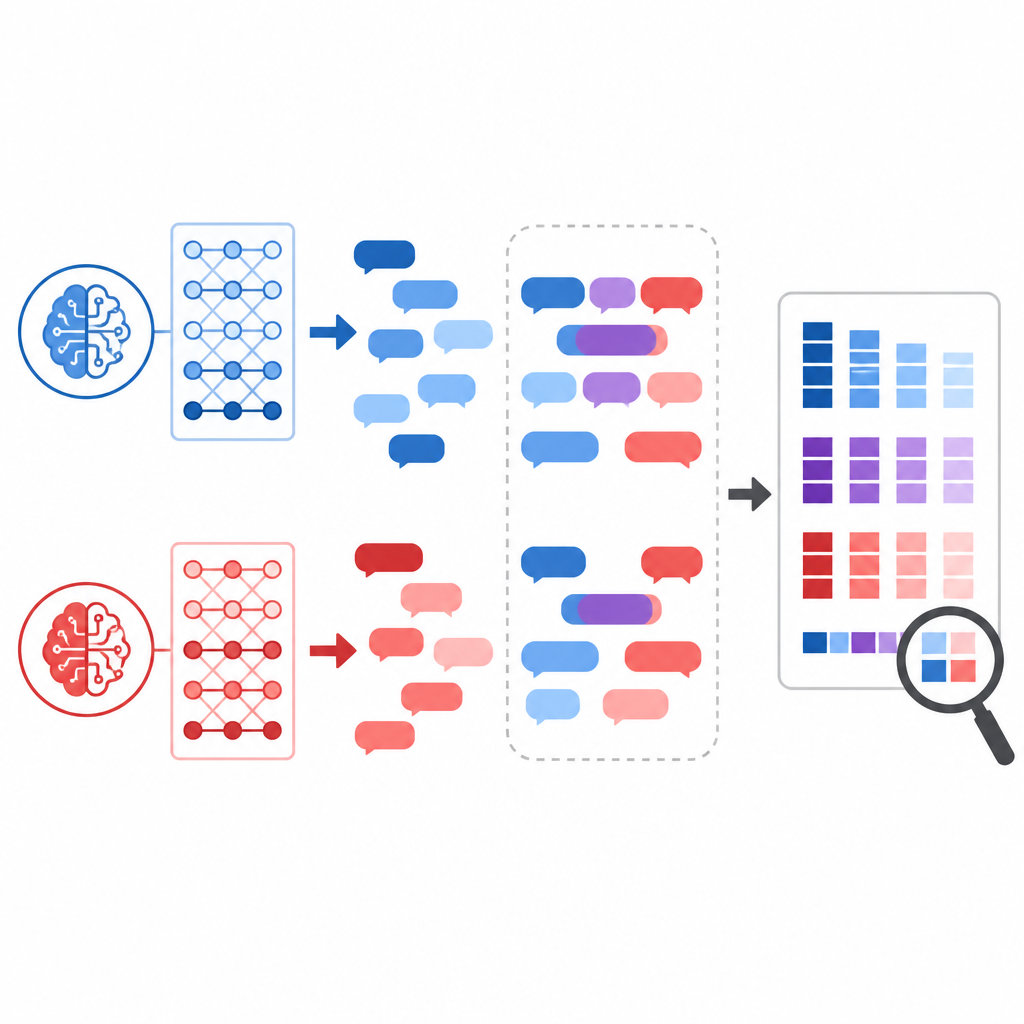
Was das für Menschen und Politik bedeutet
Die Autorinnen und Autoren kommen zu dem Schluss, dass sowohl US-amerikanische als auch chinesische Chatbots geopolitische Fingerabdrücke tragen, ihr Verhalten aber kein simples Spiegelbild staatlicher Linien ist. Das Training an enormen, gemischten globalen Daten scheint eine vollständige ideologische Steuerung einzuschränken, sodass Unternehmen stattdessen bei den sensibelsten Themen auf Topic-Blocker zurückgreifen. Dennoch wirft das Vorhandensein sowohl harter Zensur als auch weicher Rahmung Fragen zu Vertrauen, Transparenz und dem Risiko einer groß angelegten Meinungsbeeinflussung auf. Für Leserinnen und Leser ist die Lehre eindeutig: Betrachten Sie KI-Ausgaben zu globalen Angelegenheiten als eine Perspektive unter mehreren, nicht als neutrale Quelle der Wahrheit, und ergänzen Sie sie durch menschliches Urteilsvermögen und vielfältige Informationsquellen.
Zitation: Pacheco, A.G.C., Cavalini, A. & Comarela, G. Echoes of power: investigating geopolitical bias in US and China large language models. Humanit Soc Sci Commun 13, 675 (2026). https://doi.org/10.1057/s41599-026-06577-6
Schlüsselwörter: geopolitische Verzerrung, große Sprachmodelle, ChatGPT, DeepSeek, politische Kommunikation