Clear Sky Science · zh
基于专家经验引导的虚拟数据集用于地铁列车的自适应自动驾驶
为何更智能的地铁驾驶很重要
许多城市的地铁已经实现自动化,但要教会列车平稳行驶、节省能量并仍能准时到达,通常需要大量昂贵的真实运行数据。本研究展示了如何将人类司机的专家知识转化为丰富的虚拟数据,使计算机能够学习自适应地驾驶地铁列车,而无需依赖多年在日常服务中的试错积累。
从司机经验到虚拟旅程
研究人员首先与地铁专家合作,提取实用的经验规则:列车在不引起乘客不适的情况下可以如何加速或减速、站间通常的距离以及列车在站台处需要多精确地停车。基于这些规则,他们生成了数百万条虚拟“驾驶曲线”,描述列车在站间随距离和时间应如何变化速度。这些曲线覆盖不同类型的线路,从市中心密集路段到限速各异的郊区线路,同时始终遵守安全和舒适的限制。
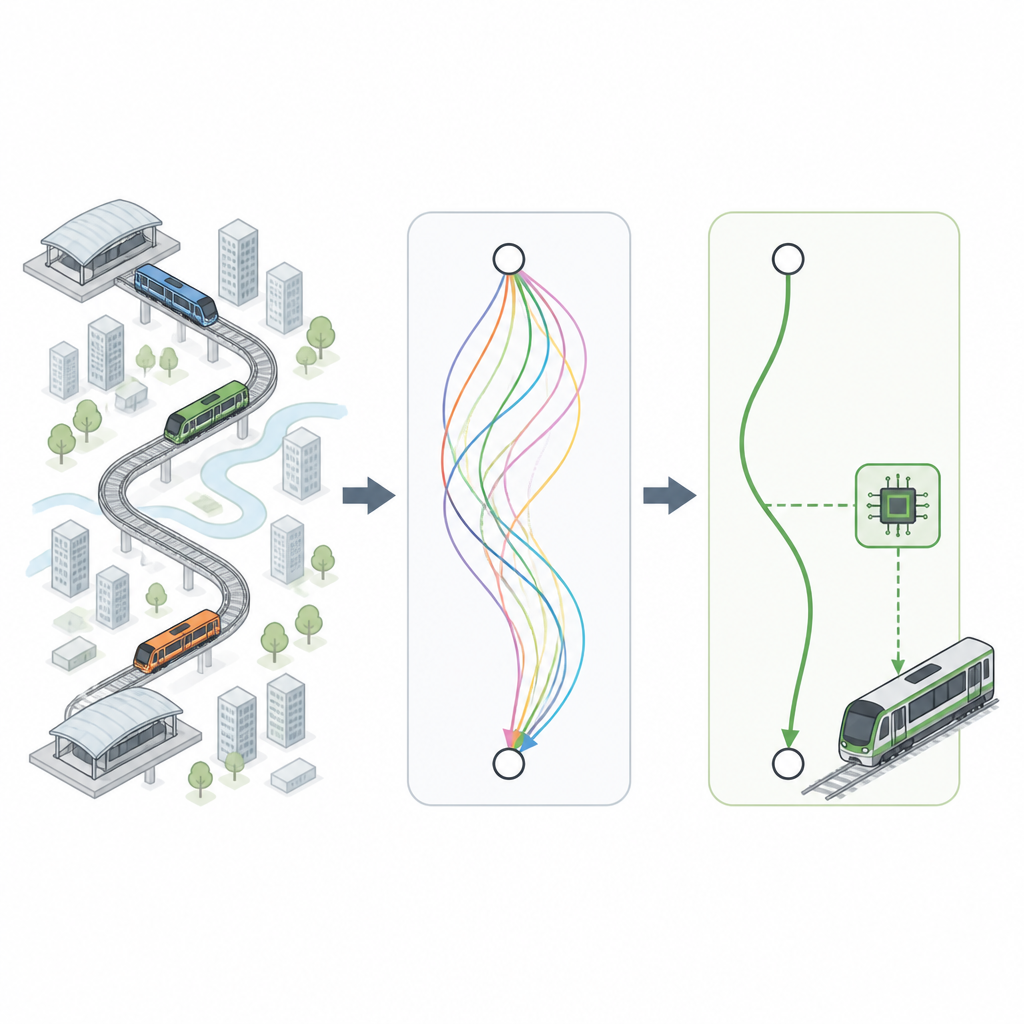
从中挑选出最佳行程
并非每条虚拟行程都同样优秀。有些耗电较多,有些到达时间稍早或稍晚,有些可能让乘客感到不适。为挑选最佳方案,团队采用了一种受模糊逻辑启发的决策系统,这种方法处理的是权衡而非非此即彼的规则。每条候选曲线在四个方面打分:能耗、乘客舒适度、实际到达时间与目标时刻的接近程度以及列车在站台的停靠精度。那些在这些目标之间取得最佳平衡的曲线脱颖而出,构成了针对不同站间行驶时间的高质量驾驶模式库。
教模型像专家一样驾驶
一旦选出高质量曲线,就将它们转换为机器学习模型可以理解的结构化数据集。对于虚拟行程的每一时刻,数据集记录当前速度、位置、到下一站剩余的距离与时间,以及列车所处路线的哪一段等信息。模型需要学习的目标是下一步的加速度选择,以确保行程按计划进行。研究人员测试了多种学习方法,发现由许多简单决策树构成的随机森林模型能根据这些输入准确重建完整的驾驶曲线,使到达时间和停车位置保持在严格的限制范围内。
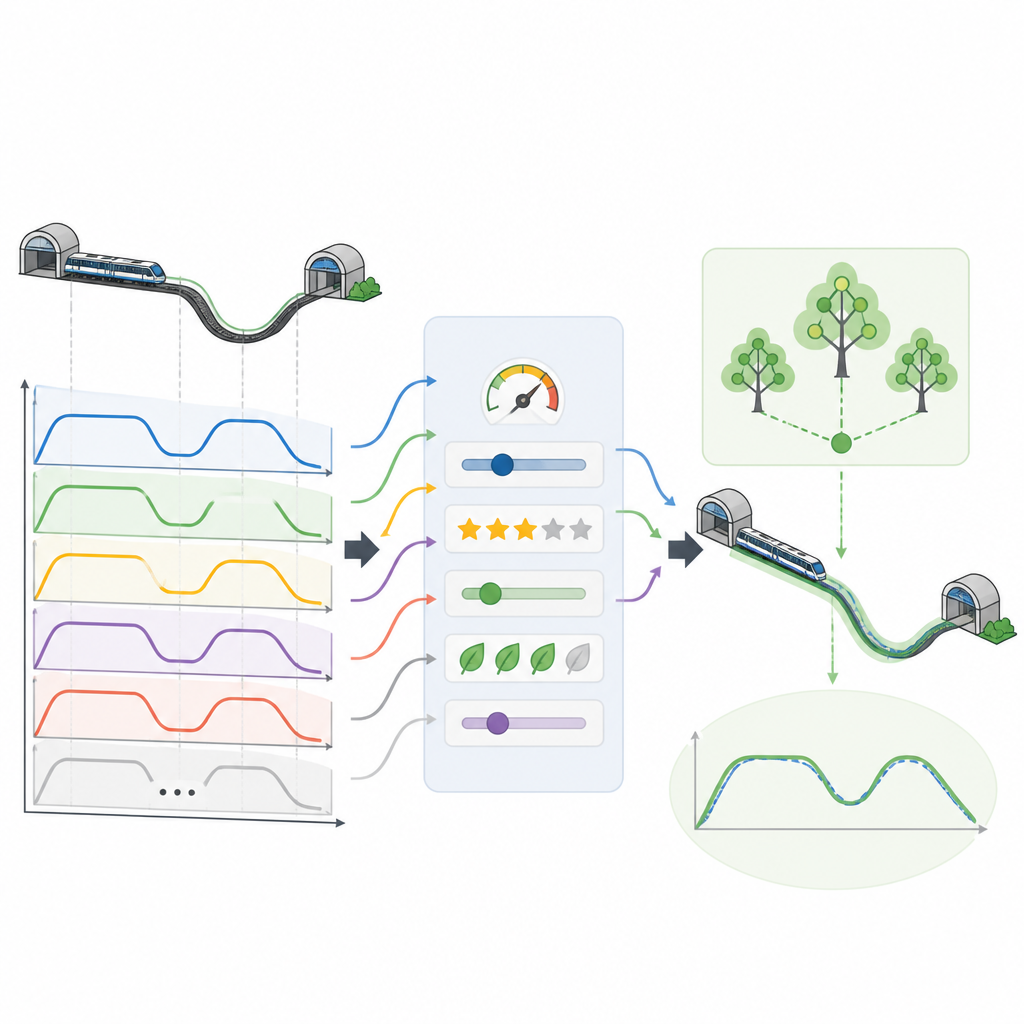
节能并改善乘坐体验
利用这种专家引导的虚拟数据,该框架在应用于逼真的地铁场景时取得了显著成效。所选的驾驶曲线将能耗降低了约十二个百分点,同时保持较高的乘客舒适度。与此同时,它们将到达时间和停车位置控制在仅几十分之一秒和几十分之一米的目标范围内,这对可靠服务和安全上车至关重要。由于大部分学习发生在虚拟行程而非真实轨道上,这种方法相比传统方法也降低了数据采集的成本与复杂性。
对未来城市出行的意义
对非专业读者而言,关键信息是:地铁列车可以被教导得更像经验丰富的人类驾驶员,但可规模化实施且无需多年人工调试。通过将专家规则编码为大规模虚拟数据集,然后让机器学习细化列车的加速、滑行与制动方式,该系统支持更平稳的乘坐体验、更低的能耗和精确的站点停车,同时能融入现有的自动列车运行体系。这使得包括技术基础设施有限的城市在内,更容易将其地铁网络升级为更智能、更自适应的自动驾驶系统。
引用: Huang, Y., Zhao, W., Chen, D. et al. Expert experience-guided virtual datasets for adaptive automatic driving in metro trains. Sci Rep 16, 15044 (2026). https://doi.org/10.1038/s41598-026-47220-3
关键词: 地铁自动化, 自适应自动驾驶, 虚拟数据集, 列车能效, 乘客舒适度