Clear Sky Science · fr
Ensembles de données virtuelles guidés par l’expertise pour une conduite automatique adaptative des rames de métro
Pourquoi une conduite de métro plus intelligente importe
Les rames de métro sont déjà automatisées dans de nombreuses villes, mais leur apprendre à rouler en douceur, économiser l’énergie et arriver à l’heure exige généralement d’énormes quantités de données réelles coûteuses à collecter. Cette étude montre comment le savoir-faire des conducteurs peut être transformé en données virtuelles riches, permettant aux ordinateurs d’apprendre à piloter les rames de façon adaptative sans dépendre d’années d’essais et d’erreurs en service quotidien.
Du savoir-faire du conducteur aux trajets virtuels
Les chercheurs commencent par collaborer avec des spécialistes du métro pour capter des règles pratiques : à quelle vitesse une rame peut accélérer ou ralentir sans incommoder les passagers, quelles sont les distances typiques entre stations, et avec quelle précision la rame doit s’arrêter en station. À partir de ces règles, ils génèrent des millions de « courbes de conduite » virtuelles décrivant comment la vitesse d’une rame doit évoluer en fonction de la distance et du temps entre stations. Ces courbes couvrent différents types de lignes, du centre-ville dense aux axes suburbains avec limites de vitesse variées, tout en respectant systématiquement les contraintes de sécurité et de confort.
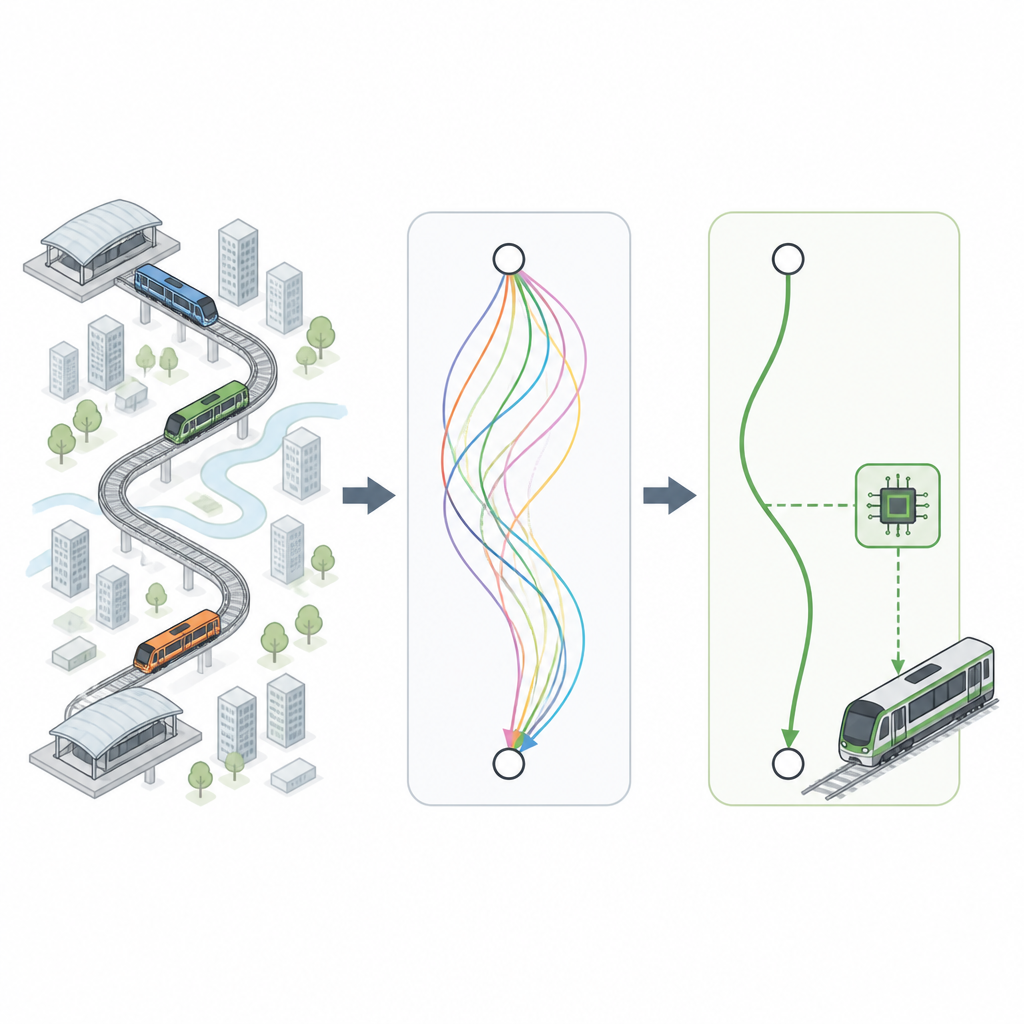
Trier les meilleurs trajets des autres
Tous les trajets virtuels ne se valent pas. Certains consomment plus d’électricité que nécessaire, d’autres arrivent un peu trop tôt ou trop tard, et certains peuvent être moins confortables pour les usagers. Pour retenir les meilleures options, l’équipe applique un système de décision inspiré de la logique floue, qui permet de gérer des compromis plutôt que d’imposer des règles binaires. Chaque courbe candidate est évaluée selon quatre critères : consommation d’énergie, confort des passagers, proximité de l’heure d’arrivée par rapport à l’horaire cible, et précision de l’arrêt en quai. Les courbes qui équilibrent le mieux ces objectifs sont retenues en priorité, constituant une bibliothèque de profils de conduite de haute qualité pour de nombreux temps de parcours interstations.
Apprendre à un modèle à conduire comme un expert
Une fois les courbes de haute qualité sélectionnées, elles sont converties en un jeu de données structuré compréhensible par un modèle d’apprentissage automatique. Pour chaque instant d’un trajet virtuel, le jeu de données enregistre des informations telles que la vitesse actuelle, la position, la distance et le temps restants jusqu’à la station suivante, et la portion de ligne parcourue. La cible à apprendre pour le modèle est le choix d’accélération suivant qui maintiendra le trajet sur la bonne trajectoire. Les chercheurs testent plusieurs méthodes d’apprentissage et constatent qu’un modèle de forêt aléatoire, constitué de nombreux arbres de décision simples, peut reconstruire avec précision des courbes de conduite complètes à partir de ces entrées, en maintenant les temps d’arrivée et les positions d’arrêt dans des marges très étroites.
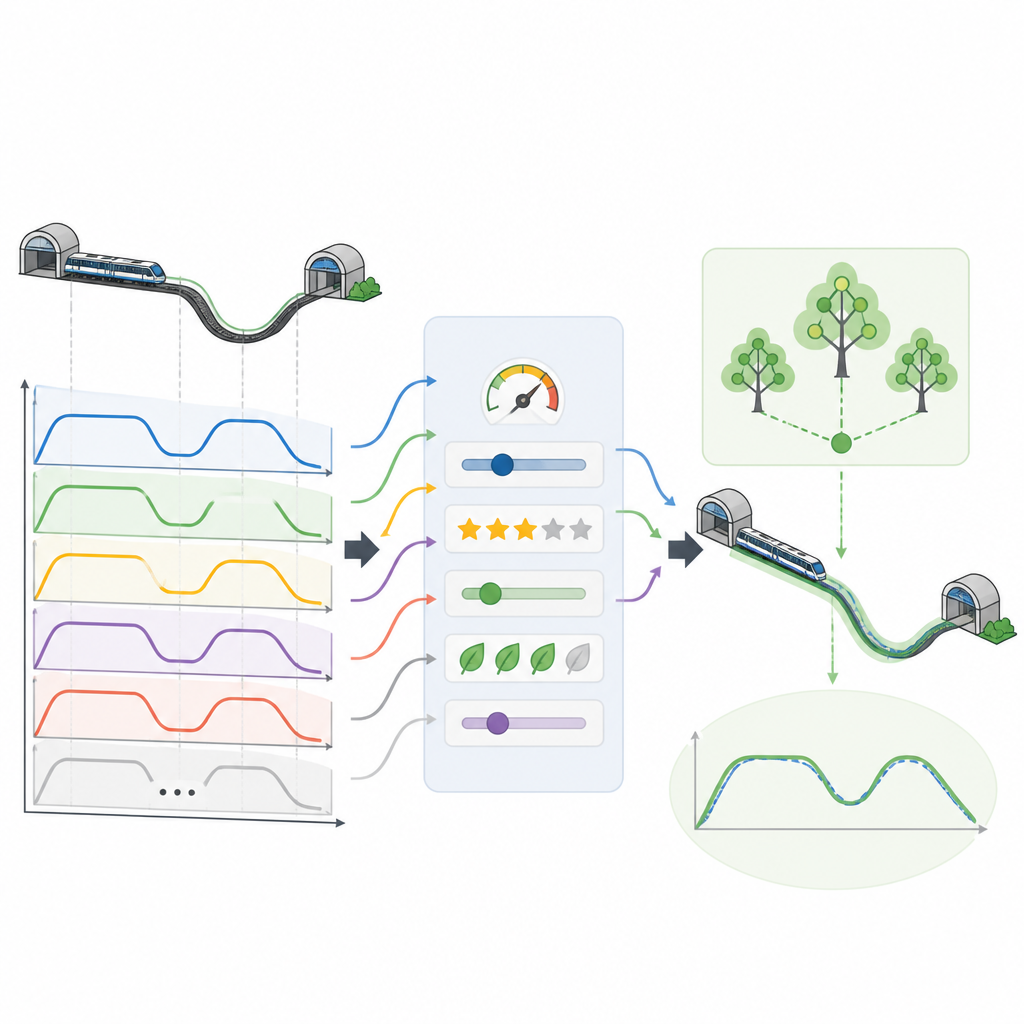
Économiser l’énergie et améliorer le trajet
En s’appuyant sur ces données virtuelles guidées par l’expertise, le cadre proposé obtient des gains significatifs dans des scénarios de métro réalistes. Les courbes de conduite sélectionnées réduisent la consommation d’énergie d’environ douze pour cent tout en maintenant un niveau élevé de confort pour les passagers. Elles conservent en parallèle des temps d’arrivée et des positions d’arrêt à quelques dixièmes de seconde et quelques dixièmes de mètre des cibles, ce qui est crucial pour un service fiable et un embarquement sûr. Parce que l’essentiel de l’apprentissage se déroule sur des trajets virtuels plutôt que sur des voies réelles, l’approche réduit aussi le coût et la complexité de la collecte de données par rapport aux méthodes traditionnelles.
Ce que cela signifie pour les déplacements urbains futurs
Pour le grand public, le message principal est que les rames de métro peuvent être entraînées à conduire davantage comme des conducteurs expérimentés, mais à grande échelle et sans des années d’ajustements manuels. En encodant des règles d’experts dans d’immenses jeux de données virtuels puis en laissant l’apprentissage automatique affiner la façon dont les rames accélèrent, relâchent la traction et freinent, le système favorise des trajets plus fluides, des factures énergétiques plus basses et des arrêts en station précis, tout en s’intégrant aux systèmes d’exploitation automatique existants. Cela facilite la modernisation des réseaux de métro vers une conduite automatique plus intelligente et adaptative, y compris pour les villes disposant d’infrastructures techniques limitées.
Citation: Huang, Y., Zhao, W., Chen, D. et al. Expert experience-guided virtual datasets for adaptive automatic driving in metro trains. Sci Rep 16, 15044 (2026). https://doi.org/10.1038/s41598-026-47220-3
Mots-clés: automatisation du métro, conduite automatique adaptative, jeux de données virtuels, efficacité énergétique des trains, confort des passagers