Clear Sky Science · nl
Door experts geleide virtuele datasets voor adaptief automatisch rijden in metrotreinen
Waarom slimmer metro-rijden ertoe doet
Metrotreinen zijn in veel steden al geautomatiseerd, maar ze leren vloeiend te rijden, energie te besparen en toch op tijd te komen vereist doorgaans enorme hoeveelheden real-world data, die duur zijn om te verzamelen. Deze studie laat zien hoe expertise van menselijke machinisten kan worden omgezet in rijke virtuele data, waardoor computers adaptief kunnen leren rijden zonder afhankelijk te zijn van jarenlange proef-en-fout in de dagelijkse dienst.
Van chauffeurskennis naar virtuele ritten
De onderzoekers beginnen met samenwerken met metrospecialisten om praktische vuistregels vast te leggen: hoe snel treinen mogen optrekken of afremmen zonder passagiers ongemak te bezorgen, hoe ver stations doorgaans uit elkaar liggen, en hoe nauwkeurig treinen op het perron moeten stoppen. Met deze regels genereren ze miljoenen virtuele "rijcurven" die beschrijven hoe de snelheid van een trein over afstand en tijd tussen stations moet veranderen. Deze curven dekken verschillende lijnsoorten, van dichte stadscentra tot voorstedelijke trajecten met wisselende snelheidslimieten, en houden daarbij altijd rekening met veiligheids- en comfortgrenzen.
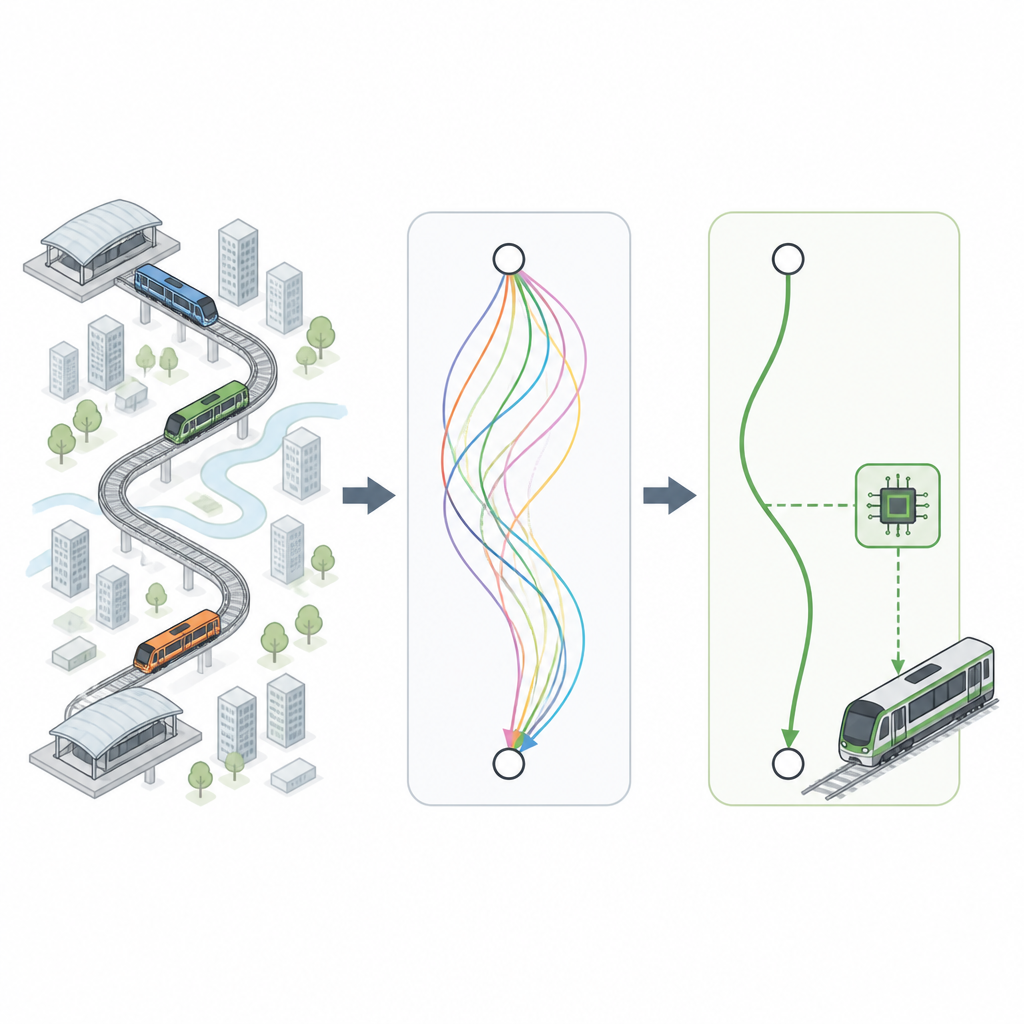
De beste ritten selecteren uit de rest
Niet elke virtuele rit is even goed. Sommige gebruiken meer elektriciteit dan nodig, andere komen net iets te vroeg of te laat aan, en sommige voelen minder comfortabel voor reizigers. Om de beste opties te kiezen past het team een beslissysteem toe dat is geïnspireerd op fuzzy logic, een manier om afwegingen te maken in plaats van strikte ja-of-nee-regels. Elke kandidaat-curve wordt beoordeeld op vier aspecten: energieverbruik, passagierscomfort, hoe dicht de daadwerkelijke aankomsttijd bij het geplande schema ligt, en hoe nauwkeurig de trein bij het perron stopt. Curven die deze doelen het beste in balans brengen stijgen naar de top en vormen een bibliotheek van hoogwaardige rijpatronen voor vele reistijden tussen stations.
Een model leren rijden als een expert
Zodra de topkwaliteitcurven zijn geselecteerd, worden ze omgezet in een gestructureerde dataset die een machine learning-model kan begrijpen. Voor elk moment van een virtuele rit registreert de dataset informatie zoals de huidige snelheid, positie, resterende afstand en tijd naar het volgende station, en welk deel van het traject de trein doorkruist. Het doel dat het model moet leren is de volgende acceleratiekeuze die de rit op koers houdt. De onderzoekers testen meerdere leermethoden en merken dat een random forest-model, opgebouwd uit veel eenvoudige beslisbomen, hele rijcurven nauwkeurig kan reconstrueren op basis van deze inputs, waarbij aankomsttijden en stopposities binnen strakke marges blijven.
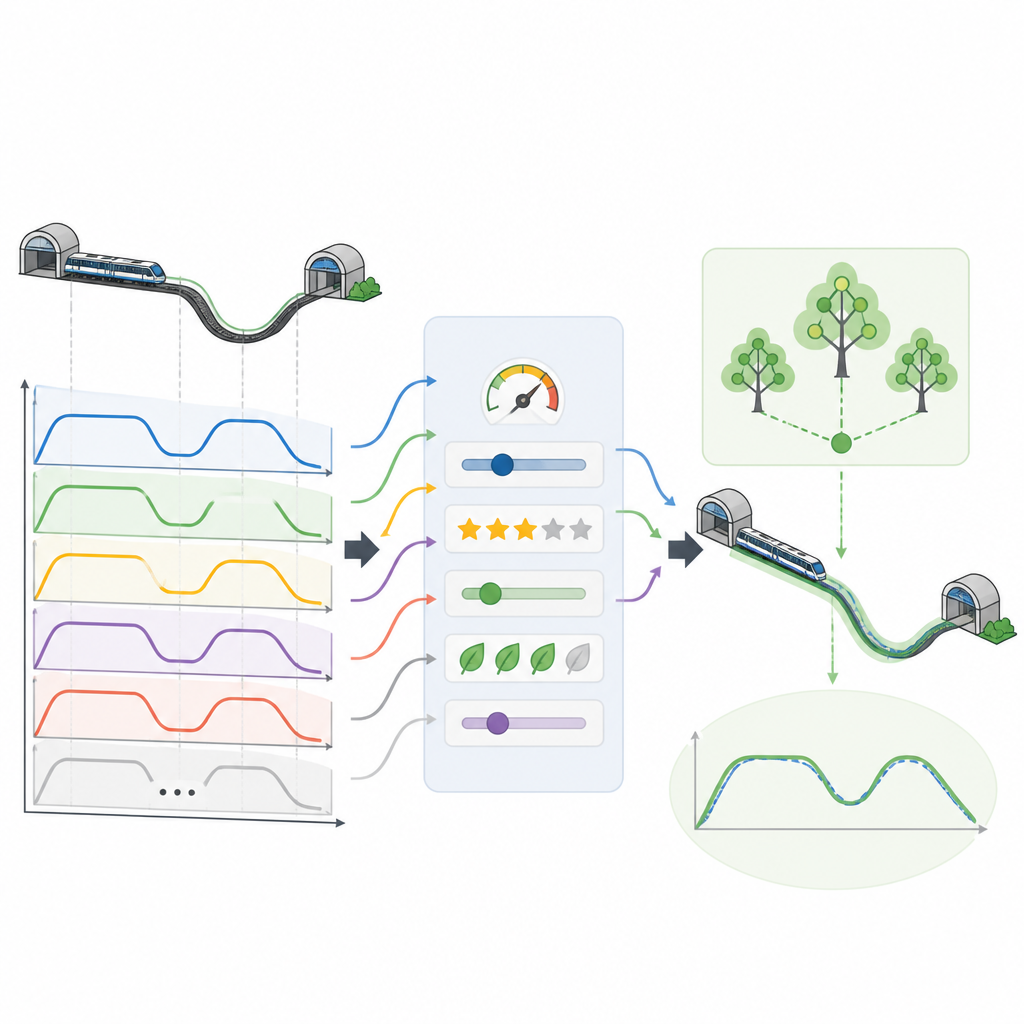
Energie besparen en de rit verbeteren
Met behulp van deze door experts geleide virtuele data behaalt het raamwerk aanzienlijke winst wanneer het op realistische metroscenario's wordt toegepast. De geselecteerde rijcurven verminderen het energieverbruik met ongeveer twaalf procent, terwijl ze een hoog niveau van passagierscomfort behouden. Tegelijkertijd houden ze aankomsttijden en stopposities binnen slechts een paar tienden van een seconde en een paar tienden van een meter van de streefwaarden, wat cruciaal is voor betrouwbare exploitatie en veilig instappen. Omdat het merendeel van het leren plaatsvindt op virtuele ritten in plaats van op echte sporen, vermindert de aanpak ook de kosten en complexiteit van dataverzameling vergeleken met traditionele methoden.
Wat dit betekent voor toekomstig stedelijk vervoer
Voor niet-specialisten is de kernboodschap dat metrotreinen kunnen worden geleerd te rijden zoals ervaren menselijke machinisten, maar dan op schaal en zonder jarenlange handmatige afstelling. Door deskundige regels te coderen in enorme virtuele datasets en vervolgens machine learning te laten verfijnen hoe treinen optrekken, uitrollen en remmen, ondersteunt het systeem vloeiendere ritten, lagere energiekosten en precieze stationstops, terwijl het in bestaande automatische treinbeheersystemen past. Hierdoor wordt het eenvoudiger voor steden, ook die met beperkte technische infrastructuur, om hun metronetwerken te upgraden naar slimmer, adaptiever automatisch rijden.
Bronvermelding: Huang, Y., Zhao, W., Chen, D. et al. Expert experience-guided virtual datasets for adaptive automatic driving in metro trains. Sci Rep 16, 15044 (2026). https://doi.org/10.1038/s41598-026-47220-3
Trefwoorden: metro-automatisering, adaptief automatisch rijden, virtuele datasets, energie-efficiëntie van treinen, passagierscomfort