Clear Sky Science · ja
地下鉄列車の適応型自動運転のための専門家経験に基づく仮想データセット
より賢い地下鉄運転が重要な理由
多くの都市ですでに地下鉄は自動化されていますが、滑らかな走行、エネルギー節約、そして定時到着を同時に達成するには通常大量の実走行データが必要で、それらの収集は高コストです。本研究は、人間の運転士の専門知識を豊かな仮想データに変換することで、日常運行での長年の試行錯誤に頼らずにコンピュータが地下鉄列車の適応的な運転を学べることを示しています。
運転士のノウハウから仮想走行へ
研究者らはまず地下鉄の専門家と協力し、実用的な経験則を抽出します:乗客に不快感を与えない加減速の速さ、駅間の典型的な距離、ホームでの停止精度など。これらのルールを用いて、駅間の距離と時間に応じて列車の速度がどのように変化すべきかを示す数百万の仮想「走行曲線」を生成します。これらの曲線は、都心部の高密度路線から郊外の速度制限が異なる路線まで様々なタイプを網羅しつつ、安全性と快適性の制約を常に満たすよう設計されています。
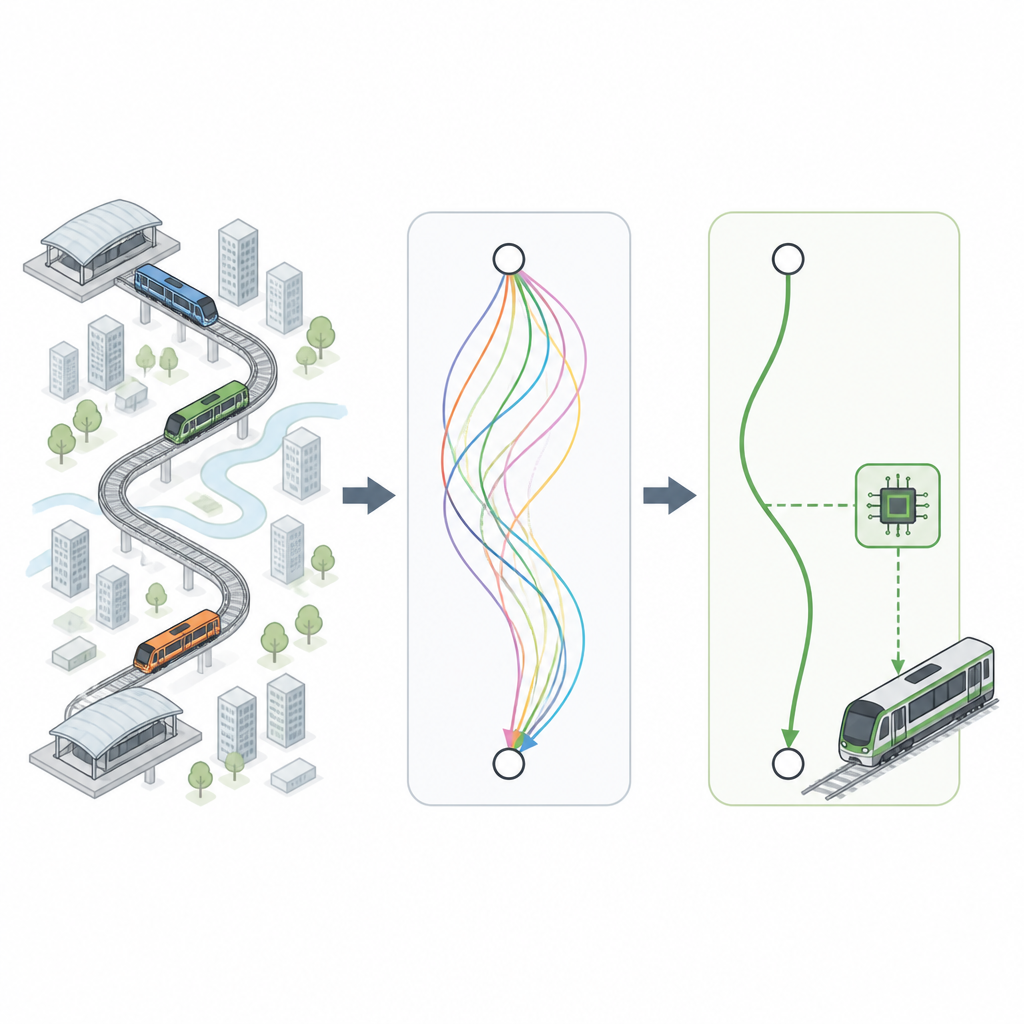
良い走行を選り分ける
すべての仮想走行が同じように優れているわけではありません。電力を余分に使うもの、到着がやや早すぎる・遅すぎるもの、乗客にとって快適さが劣るものなどがあります。最良の選択肢を選ぶために、チームはファジィ論理に触発された意思決定システムを適用します。これは厳密な二択ではなくトレードオフを扱う方法です。各候補曲線は、エネルギー使用量、乗客の快適性、目標時刻への到着の近さ、ホームでの停止精度という4つの観点で評価されます。これらの目標を最もバランスよく満たす曲線が上位に選ばれ、多様な駅間走行時間に対応する高品質な運転パターンのライブラリが構築されます。
専門家のように運転するモデルを教える
上位の高品質曲線が選ばれると、それらは機械学習モデルが扱える構造化データセットに変換されます。仮想走行の各時点で、データセットは現在の速度、位置、次の駅までの残距離と残時間、列車がルートのどの区間にいるかといった情報を記録します。モデルが学ぶべき目標は、走行を軌道に乗せ続けるための次の加速度選択です。研究者らは複数の学習手法を試し、多数の単純な決定木から構成されるランダムフォレストモデルが、これらの入力から走行曲線全体を正確に再現し、到着時刻や停止位置を厳密な範囲内に保てることを見出しました。
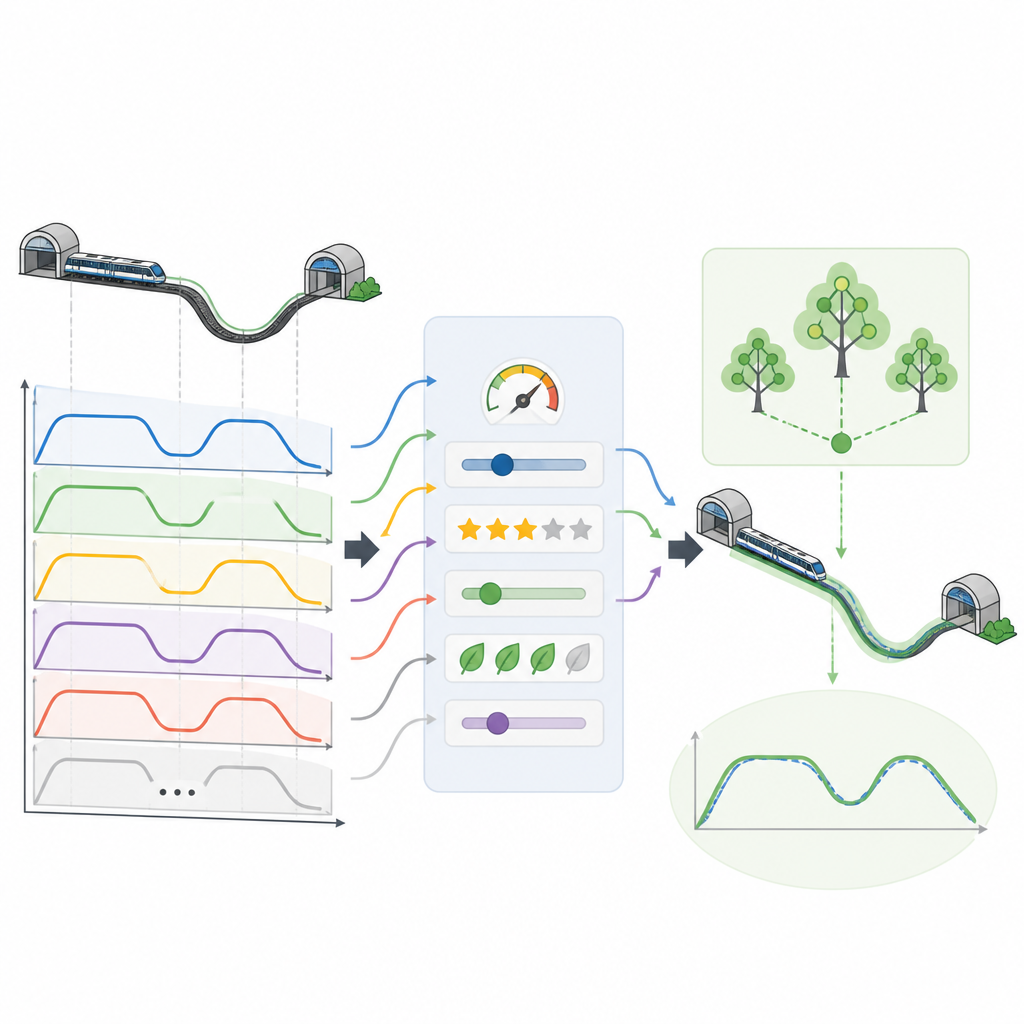
エネルギー節約と乗り心地の改善
この専門家導出の仮想データを用いることで、実際的な地下鉄シナリオに適用した際に目立つ効果が得られます。選択された走行曲線はエネルギー消費を約12%削減しつつ、乗客の快適性を高水準に維持します。同時に、到着時刻や停止位置は目標から数十分の一秒や数十分の一メートルの範囲に収まっており、信頼できる運行と安全な乗降に不可欠な精度が確保されています。学習の大部分が実線上ではなく仮想走行で行われるため、従来の手法と比べてデータ収集のコストと複雑さも軽減されます。
将来の都市交通にとっての意味
非専門家向けの要点は、地下鉄列車は熟練した運転士のように運転することを大規模に学べるが、そのために長年の手作業による調整は不要である、ということです。専門家のルールを巨大な仮想データセットに符号化し、機械学習が列車の加速、惰行、制動の最適化を行うことで、より滑らかな乗り心地、低いエネルギーコスト、精密な停車が可能になり、既存の自動列車運転システムにも組み込みやすくなります。これにより、技術インフラが限られる都市を含め、多くの都市が地下鉄ネットワークをより賢く適応的な自動運転へと更新しやすくなります。
引用: Huang, Y., Zhao, W., Chen, D. et al. Expert experience-guided virtual datasets for adaptive automatic driving in metro trains. Sci Rep 16, 15044 (2026). https://doi.org/10.1038/s41598-026-47220-3
キーワード: 地下鉄自動化, 適応型自動運転, 仮想データセット, 列車のエネルギー効率, 乗客の快適性