Clear Sky Science · it
Dataset virtuali guidati dall’esperienza degli esperti per la guida automatica adattativa nei treni metropolitani
Perché una guida metropolitana più intelligente è importante
I treni metropolitani sono già automatizzati in molte città, ma insegnare loro a guidare in modo fluido, risparmiare energia e arrivare comunque in orario richiede di solito grandi quantità di dati reali, costosi da raccogliere. Questo studio mostra come la conoscenza degli operatori umani possa essere trasformata in ricchi dati virtuali, permettendo ai computer di imparare a guidare i treni metropolitani in modo adattativo senza dipendere da anni di tentativi ed errori nel servizio quotidiano.
Dal know-how del conducente ai viaggi virtuali
I ricercatori iniziano collaborando con specialisti della metropolitana per catturare regole pratiche: con quale rapidità i treni possono accelerare o decelerare senza mettere a disagio i passeggeri, quanto distano normalmente le stazioni e quanto sia preciso l’arresto in banchina. Usando queste regole, generano milioni di “curve di guida” virtuali che descrivono come la velocità del treno dovrebbe cambiare nel tempo e nello spazio tra le stazioni. Queste curve coprono diversi tipi di linee, dai centri cittadini densi alle tratte suburbane con limiti di velocità variabili, rispettando sempre i vincoli di sicurezza e comfort.
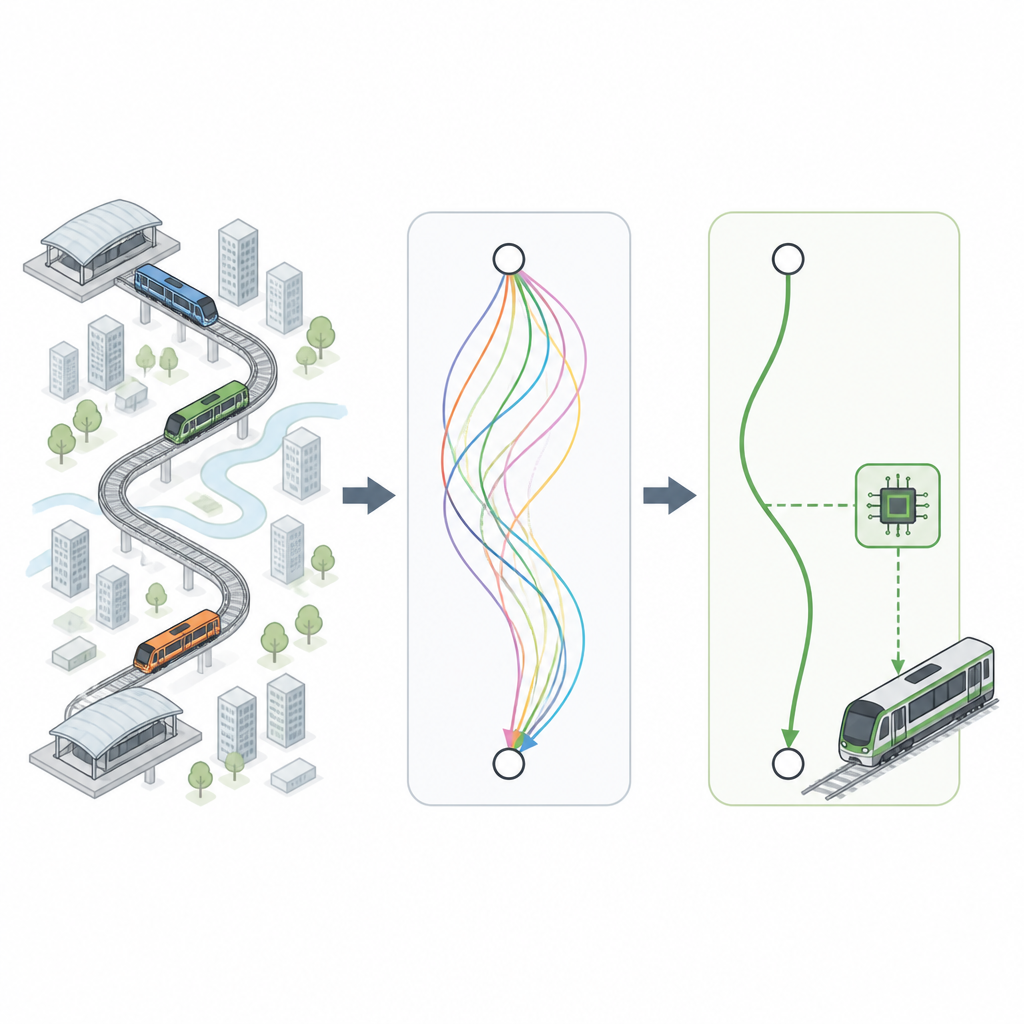
Selezionare le corse migliori
Non tutti i viaggi virtuali sono ugualmente validi. Alcuni consumano più elettricità del necessario, altri arrivano un po’ troppo presto o troppo tardi, e alcuni possono risultare meno confortevoli per i passeggeri. Per scegliere le opzioni migliori, il team applica un sistema decisionale ispirato alla logica fuzzy, un modo di gestire i compromessi anziché regole rigorose sì/no. Ogni curva candidata viene valutata su quattro aspetti: consumo energetico, comfort dei passeggeri, quanto l’orario di arrivo reale si avvicina all’orario target e quanto accuratamente il treno si arresta in banchina. Le curve che bilanciano meglio questi obiettivi emergono come le migliori, fornendo una libreria di pattern di guida di alta qualità per molti tempi di percorrenza stazione-stazione.
Addestrare un modello a guidare come un esperto
Una volta selezionate le curve di massima qualità, esse vengono convertite in un dataset strutturato che un modello di apprendimento automatico può comprendere. Per ogni istante di un viaggio virtuale, il dataset registra informazioni come velocità attuale, posizione, distanza e tempo rimanenti alla stazione successiva e quale tratto del percorso il treno sta percorrendo. L’obiettivo che il modello deve imparare è la scelta di accelerazione successiva che manterrà il viaggio nei parametri desiderati. I ricercatori testano diversi metodi di apprendimento e riscontrano che un modello random forest, costruito da molti semplici alberi decisionali, può ricostruire con precisione intere curve di guida a partire da questi input, mantenendo tempi di arrivo e posizioni di arresto entro limiti ristretti.
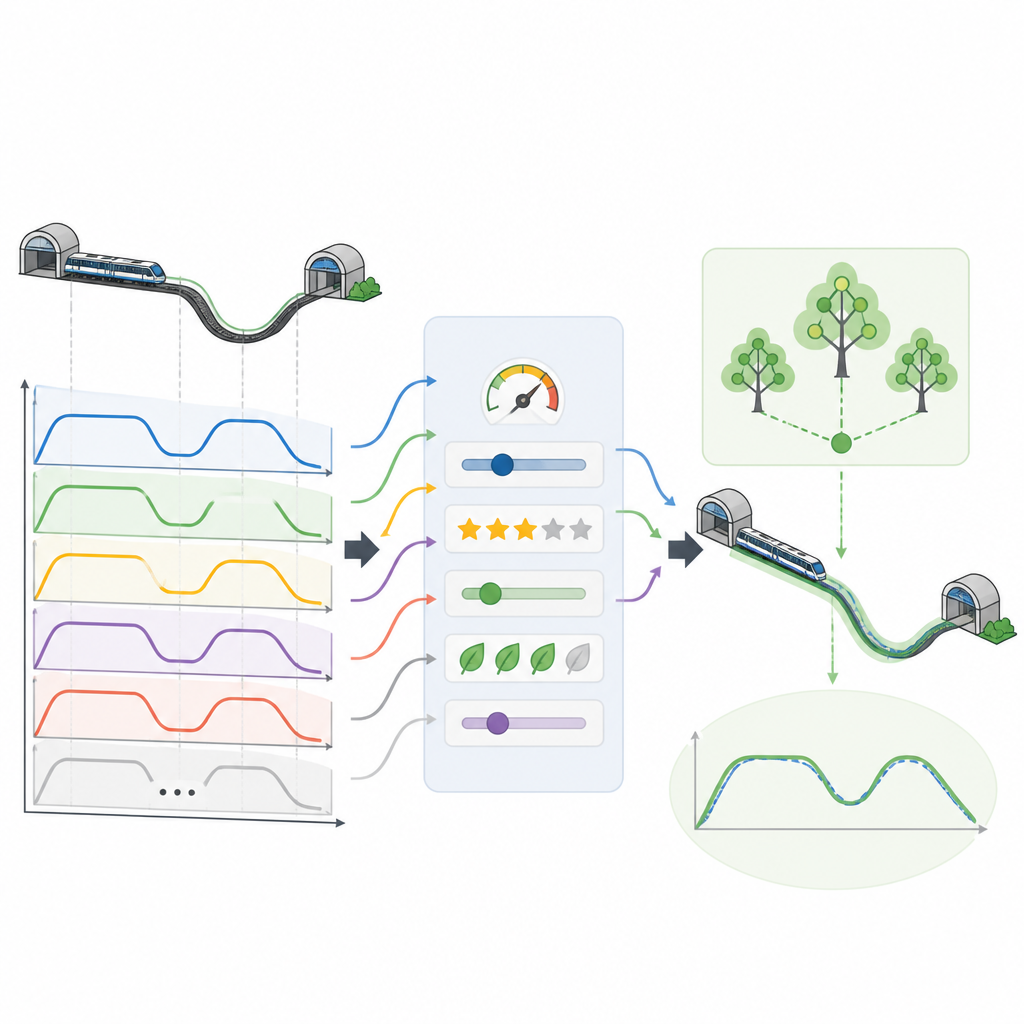
Risparmiare energia e migliorare il viaggio
Utilizzando questi dati virtuali guidati dagli esperti, il framework ottiene guadagni significativi quando applicato a scenari metropolitani realistici. Le curve di guida selezionate riducono il consumo energetico di circa il dodici percento mantenendo un elevato livello di comfort per i passeggeri. Allo stesso tempo, mantengono i tempi di arrivo e le posizioni di arresto entro pochi decimi di secondo e pochi decimi di metro dai target, fattore cruciale per un servizio affidabile e un imbarco sicuro. Poiché la maggior parte dell’apprendimento avviene su viaggi virtuali anziché su rotaie reali, l’approccio riduce anche i costi e la complessità della raccolta dati rispetto ai metodi tradizionali.
Cosa significa per il futuro della mobilità urbana
Per i non specialisti, il messaggio chiave è che i treni metropolitani possono essere addestrati a guidare più come operatori umani esperti, ma su scala e senza anni di messa a punto manuale. Codificando le regole degli esperti in vasti dataset virtuali e lasciando poi che l’apprendimento automatico affini come i treni accelerano, coasting e frenano, il sistema favorisce corse più fluide, bollette energetiche più basse e arresti precisi in stazione, il tutto integrabile negli attuali sistemi di esercizio automatico dei treni. Questo rende più facile per le città, incluse quelle con infrastrutture tecniche limitate, aggiornare le loro reti metropolitane verso una guida automatica più intelligente e adattativa.
Citazione: Huang, Y., Zhao, W., Chen, D. et al. Expert experience-guided virtual datasets for adaptive automatic driving in metro trains. Sci Rep 16, 15044 (2026). https://doi.org/10.1038/s41598-026-47220-3
Parole chiave: automazione metropolitana, guida automatica adattativa, dataset virtuali, efficienza energetica dei treni, comfort dei passeggeri