Clear Sky Science · zh
多模态大型语言模型在区分手机录制视频中癫痫发作与功能性癫痫发作的诊断准确性
为什么你的手机视频可能有助于诊断癫痫发作
当某人突然倒下或开始抽搐时,旁观者现在常做的一件事是:掏出智能手机并按下录制键。这些视频可能成为能救命的线索,帮助医生判断该事件是癫痫发作还是一种外观类似的发作——称为功能性癫痫发作。但专科神经科医生短缺,等待专家审查视频会延迟治疗。该研究探讨现代人工智能,特别是多模态大型语言模型,能否仅凭这些日常手机片段自行判断两者差异。
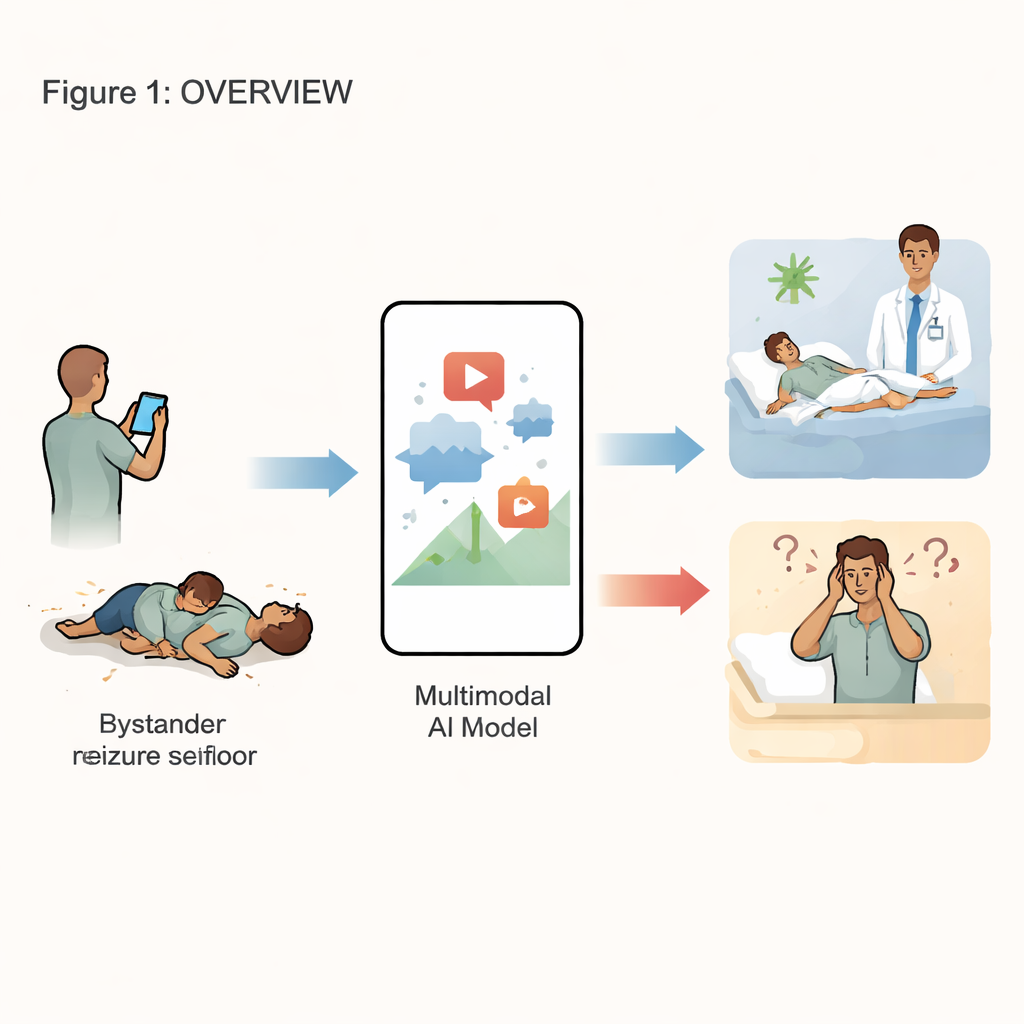
两类外观相似的急症
癫痫发作与功能性癫痫发作对未经训练的观察者而言可能很相似,但它们的成因与治疗大相径庭。癫痫发作源于大脑异常的电活动,通常以药物或手术治疗为主。相比之下,功能性癫痫发作并非由此类脑电放电驱动;它们是真实且令人痛苦的事件,根植于复杂的脑—心相互作用,需要不同的照护,常涉及心理支持。由于发作短暂且令人恐惧,家庭成员往往难以准确描述。事发时录制的视频提供了更忠实的画面,但对这些视频的评估仍依赖于有经验的癫痫专家。
将通用人工智能付诸考验
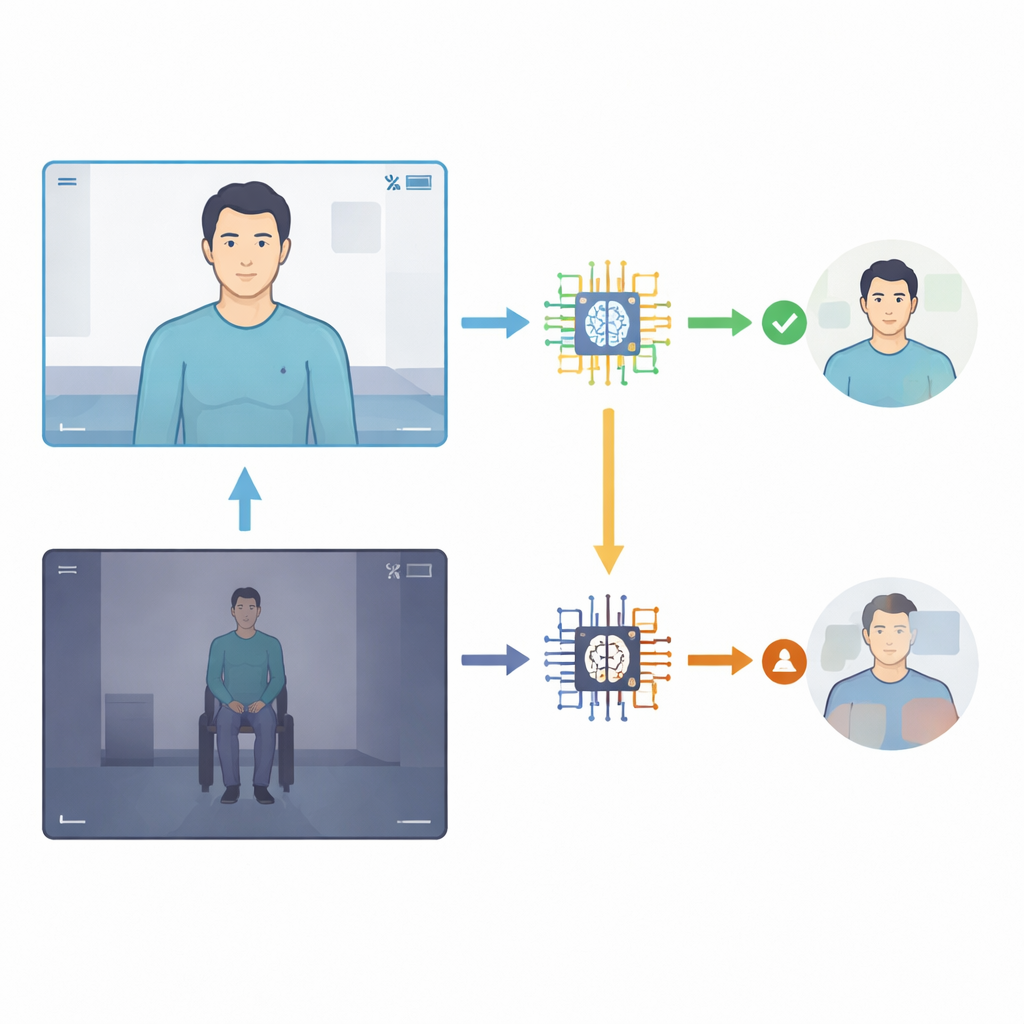
一家主要癫痫中心的研究人员收集了15位成人的24段智能手机视频,这些患者的事件已通过医院视频—脑电(video–EEG)监测做出仔细诊断——这是记录脑电和行为的金标准。其中19段显示的是癫痫发作,5段为功能性发作。研究人员随后在没有任何病史等背景医学信息的情况下,将每段视频分别输入一系列通用人工智能系统的四个版本(Gemini 1.5 Pro、2.0 Flash、2.5 Flash 和 2.5 Pro)。每个模型被问及一个简单问题:该事件是癫痫性还是功能性?人工智能还需在1–10的尺度上表明其置信度。团队将人工智能的答案与医院诊断进行比较,并计算准确率、敏感性(癫痫发作被正确识别的频率)和特异性(功能性发作被正确排除的频率)等常用指标。
人工智能的对与错
较新的人工智能版本比旧版表现更好,但没有一个接近能替代专家。总体诊断准确率从最早模型约三分之一正确上升到两个最新模型略高于一半。最新的系统 Gemini 2.5 Pro 最为均衡:它检测到略多于一半的癫痫发作,并正确排除了大多数但并非全部的功能性发作。早期版本极为谨慎:几乎不会将功能性发作误判为癫痫,但却漏检了绝大多数癫痫发作。值得注意的是,简单地将每个事件都判定为“癫痫”这一朴素策略所得的原始准确率会高于任何模型——但这种做法完全无法区分这两种状况,凸显了该任务的难度。
为什么视频细节如此重要
研究还显示视频的质量与构图对人工智能的表现影响很大。当录制清晰、光线良好且聚焦于上半身或面部时,最新模型在该子集中的正确率约为80–90%。而当画面远距离展示全身或光线较差时,准确率骤降,有时接近于零。发作类型也会影响结果:早期人工智能版本在较微妙、非剧烈抽搐的事件上基本失败,而后期版本在明显抽搐与不那么剧烈的情形之间表现得更为平衡。然而在所有模型中,无论答案对错,置信度评分往往都很高,这意味着人工智能经常“自信地出错”——如果临床医生或患者依赖这些判断,这是令人担忧的特征。
这对患者与医生意味着什么
目前结论很清楚:通用人工智能能在发作视频中识别模式并在缓慢改进,但作为独立诊断工具仍远不可靠。系统仍会漏检许多癫痫发作,难以应对微妙事件,也尚未能够识别何时可能出错。作者认为,未来版本需要在大规模高质量、由专家标注的医疗视频集上训练,改进不确定性表达方式,并与患者病史及脑电记录更紧密地整合。与其说这些工具会取代神经科医生,不如说它们更可能成为更广泛以人为中心的方案的一部分,在该方案中智能手机、专家与精心设计的人工智能协同工作,以加快并提高癫痫发作诊断的速度与准确性。
引用: Patel, A., Vallamchetla, S.K., Safa, A. et al. Diagnostic accuracy of multimodal large language models in differentiating epileptic from functional seizures in smartphone recorded videos. Sci Rep 16, 11719 (2026). https://doi.org/10.1038/s41598-026-46333-z
关键词: 癫痫, 发作视频, 人工智能, 大型语言模型, 医学诊断