Clear Sky Science · nl
Diagnostische nauwkeurigheid van multimodale grote taalmodellen bij het onderscheiden van epileptische en functionele aanvallen in met een smartphone opgenomen video's
Waarom uw telefoonsvideo kan helpen bij het stellen van een aanvalsdiagnose
Wanneer iemand plotseling instort of begint te schudden, halen omstanders tegenwoordig vaak meteen een smartphone tevoorschijn en drukken op opnemen. Deze video's kunnen levensreddende aanwijzingen bevatten en artsen helpen bepalen of het om een epileptische aanval ging of om een gelijkaardige episode die functionele aanval heet. Deskundige neurologen zijn echter schaars, en wachten op een specialist die video's beoordeelt kan de behandeling vertragen. Deze studie gaat na of moderne kunstmatige intelligentie, specifiek multimodale grote taalmodellen, deze alledaagse telefoonbeelden kan bekijken en zelfstandig het verschil kan aangeven.
Twee soorten gelijkende noodgevallen
Epileptische en functionele aanvallen kunnen voor een ongetraind oog op elkaar lijken, maar ze hebben heel verschillende oorzaken en behandelingen. Epileptische aanvallen ontstaan door abnormale elektrische activiteit in de hersenen en worden doorgaans behandeld met medicatie of chirurgie. Functionele aanvallen daarentegen worden niet veroorzaakt door zulke hersenontladingen; het zijn reële en ingrijpende gebeurtenissen geworteld in complexe interacties tussen hersenen en geest, en ze vragen om andere zorg, vaak met psychologische ondersteuning. Omdat de gebeurtenissen kort en schrikaanjagend zijn, vinden families het moeilijk ze nauwkeurig te beschrijven. Video-opnamen die op het moment zelf zijn gemaakt bieden een getrouwer beeld, maar beoordeling ervan hangt nog steeds af van toegang tot ervaren epilepsiespecialisten.
Algemeen‑doel AI op de proef gesteld
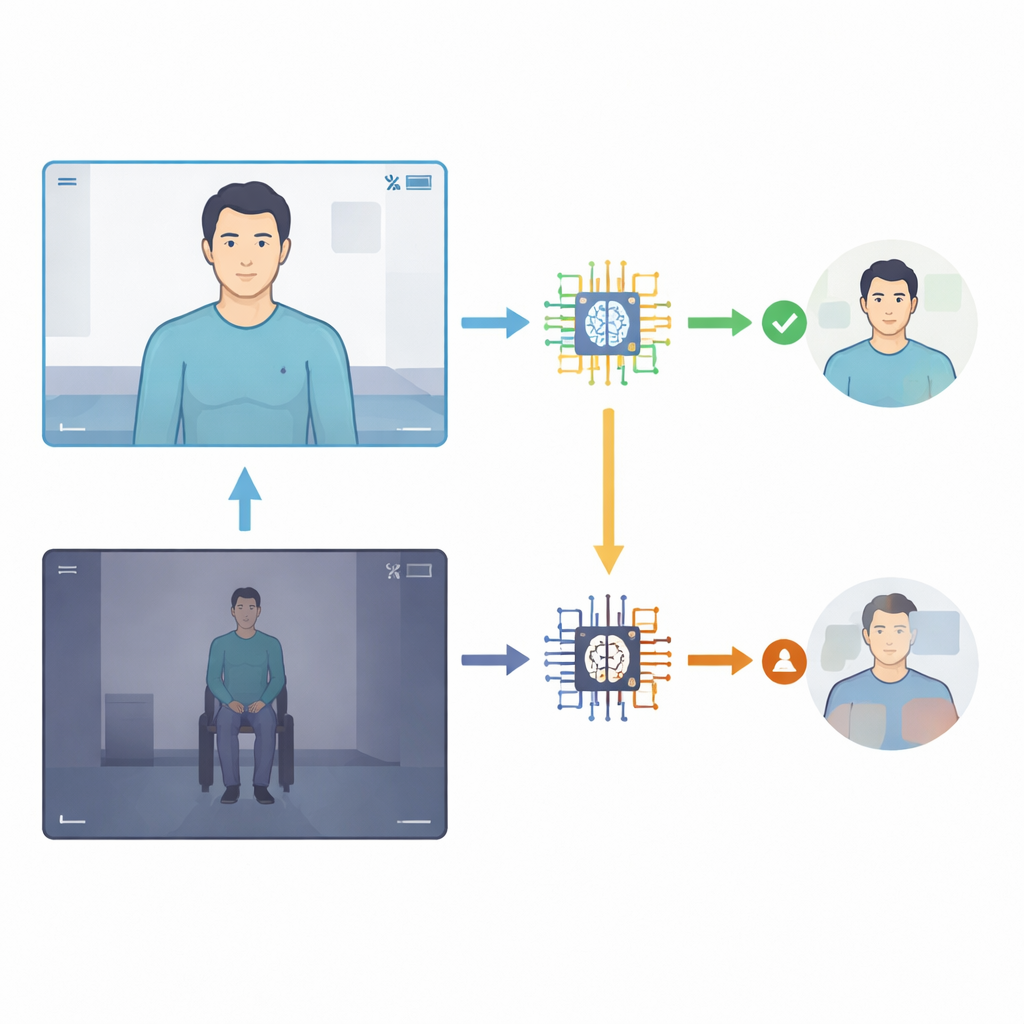
De onderzoekers van een groot epilepsiecentrum verzamelden 24 smartphonevideo's van 15 volwassenen waarvan de gebeurtenissen zorgvuldig waren gediagnosticeerd met ziekenhuis video‑EEG-monitoring, de gouden standaard die zowel hersengolven als gedrag registreert. Negentien clips toonden epileptische aanvallen en vijf toonden functionele aanvallen. Ze voerden vervolgens elke video, zonder enige achtergrondinformatie uit de medische dossiers, in bij vier versies van een familie van algemeen‑doel AI‑systemen (Gemini 1.5 Pro, 2.0 Flash, 2.5 Flash en 2.5 Pro). Elk model kreeg een eenvoudige vraag: was de gebeurtenis epileptisch of functioneel? De AI moest ook op een schaal van 1–10 aangeven hoe zeker het van die inschatting was. Het team vergeleek de antwoorden van de AI met de ziekenhuisdiagnoses en berekende standaardmaten zoals nauwkeurigheid, sensitiviteit (hoe vaak epileptische aanvallen correct werden herkend) en specificiteit (hoe vaak functionele aanvallen correct werden uitgesloten).
Wat de AI goed—en fout—had
Nieuwere versies van de AI presteerden beter dan oudere, maar geen enkele kwam in de buurt van het vervangen van een specialist. De algehele diagnostische nauwkeurigheid steeg van ongeveer een derde correct bij het vroegste model tot net iets boven de helft correct bij de twee recentste modellen. Het meest recente systeem, Gemini 2.5 Pro, was het meest evenwichtig: het detecteerde iets meer dan de helft van de epileptische aanvallen en wees de meeste, maar niet alle, functionele aanvallen correct af. Eerdere versies waren extreem terughoudend: ze labelden bijna nooit functionele aanvallen onterecht als epileptisch, maar misten het overgrote deel van de epileptische aanvallen. Belangrijk is dat een naïeve strategie waarin elke gebeurtenis simpelweg als “epileptisch” zou worden bestempeld, een hogere ruwe nauwkeurigheid had opgeleverd dan elk model—maar volledig had gefaald in het onderscheiden van de twee aandoeningen, wat benadrukt hoe uitdagend deze taak is.
Waarom videodetails zo veel uitmaken
De studie toonde ook aan dat kwaliteit en kadering van de video de AI‑prestaties sterk beïnvloedden. Wanneer opnamen helder waren, goed verlicht en gericht op het bovenlichaam of gezicht, zaten de nieuwste modellen in dat deelbestand in ongeveer 80–90 procent van de gevallen goed. Wanneer het hele lichaam van afstand te zien was, of de verlichting slecht was, daalde de nauwkeurigheid scherp, soms bijna tot nul. Het type aanval maakte ook verschil: vroege AI‑versies faalden praktisch bij subtielere, niet‑schuddende gebeurtenissen, terwijl latere versies iets beter in balans waren tussen duidelijk schuddende en minder dramatische episodes. Toch bleven de confidentiescores over alle modellen heen hoog, of het antwoord nu juist of onjuist was, wat betekent dat de AI vaak “verzekerd fout” was—een zorgwekkende eigenschap als clinici of patiënten op deze oordelen zouden vertrouwen.
Wat dit betekent voor patiënten en artsen
Voorlopig is de boodschap helder: algemeen‑doel AI kan patronen in aanvalsvideo's opmerken en verbetert langzaam, maar is nog lang niet betrouwbaar als zelfstandig diagnostisch instrument. De systemen missen nog veel epileptische aanvallen, hebben moeite met subtiele gebeurtenissen en weten nog niet goed wanneer ze het mogelijk bij het verkeerde eind hebben. De auteurs betogen dat toekomstige versies training zullen nodig hebben op veel grotere verzamelingen van hoogwaardige, door experts gelabelde medische video's, betere manieren om onzekerheid uit te drukken en nauwere integratie met de medische voorgeschiedenis van patiënten en hersengolfregistraties. In plaats van neurologen te vervangen, zullen deze hulpmiddelen waarschijnlijk deel worden van een bredere, mensgerichte aanpak waarin smartphones, specialisten en zorgvuldig ontworpen AI samenwerken om de diagnose van aanvallen te versnellen en te verscherpen.
Bronvermelding: Patel, A., Vallamchetla, S.K., Safa, A. et al. Diagnostic accuracy of multimodal large language models in differentiating epileptic from functional seizures in smartphone recorded videos. Sci Rep 16, 11719 (2026). https://doi.org/10.1038/s41598-026-46333-z
Trefwoorden: epilepsie, aanvalsvideo's, kunstmatige intelligentie, grote taalmodellen, medische diagnose