Clear Sky Science · en
Diagnostic accuracy of multimodal large language models in differentiating epileptic from functional seizures in smartphone recorded videos
Why your phone video might help diagnose a seizure
When someone suddenly collapses or starts shaking, bystanders now often do the same thing: pull out a smartphone and hit record. These videos can be lifesaving clues, helping doctors decide whether the event was an epileptic seizure or a look‑alike episode called a functional seizure. But expert neurologists are in short supply, and waiting for a specialist to review videos can delay treatment. This study asks whether modern artificial intelligence, specifically multimodal large language models, can watch these everyday phone clips and tell the difference on their own.
Two types of look‑alike emergencies
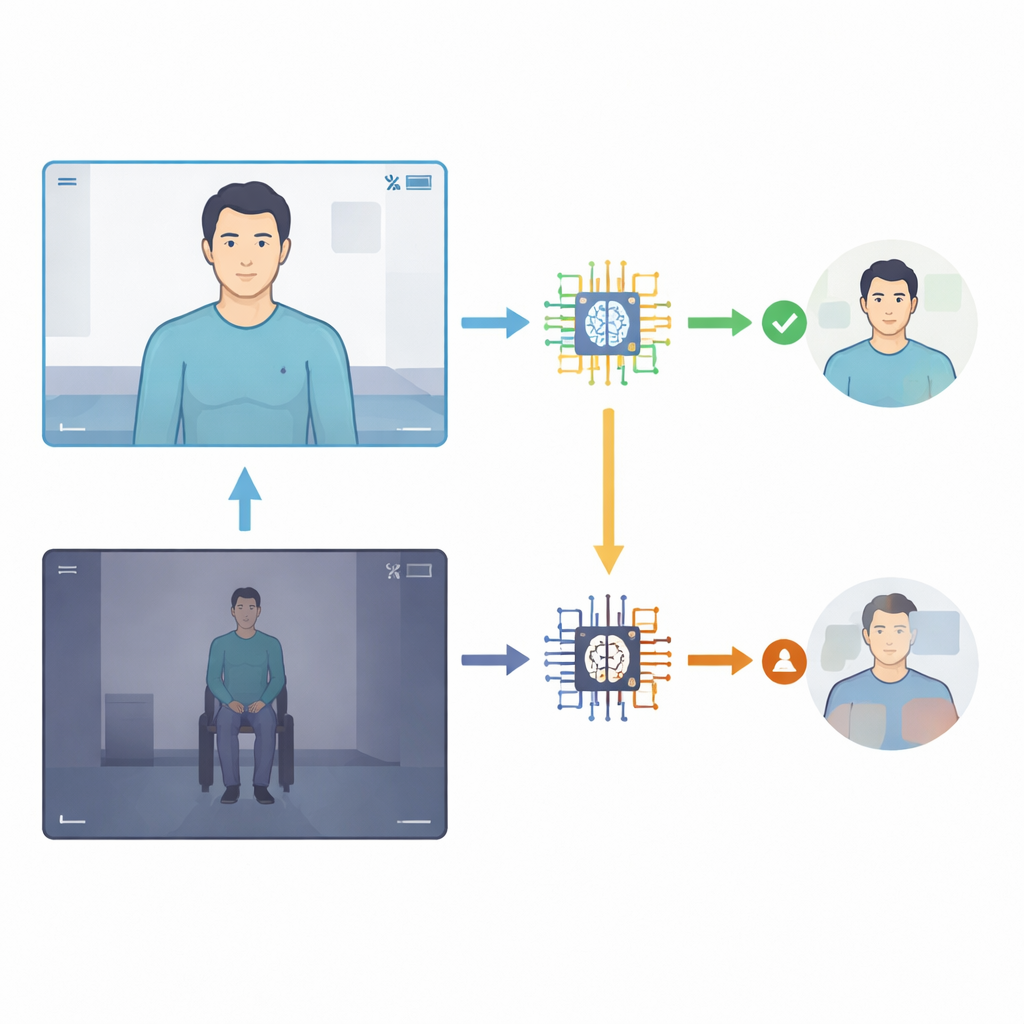
Epileptic and functional seizures can look similar to an untrained eye, yet they have very different causes and treatments. Epileptic seizures arise from abnormal electrical activity in the brain and are usually treated with medicine or surgery. Functional seizures, by contrast, are not driven by such brain discharges; they are real and distressing events rooted in complex brain–mind interactions, and they call for different care, often involving psychological support. Because the events are brief and frightening, families struggle to describe them accurately. Video recordings taken in the moment offer a more faithful picture, but reviewing them still depends on access to skilled epilepsy specialists.
Putting general‑purpose AI to the test
The researchers at a major epilepsy center collected 24 smartphone videos from 15 adults whose events had been carefully diagnosed using hospital video–EEG monitoring, the gold standard that records both brain waves and behavior. Nineteen clips showed epileptic seizures, and five showed functional seizures. They then fed each video, without any background medical information, to four versions of a family of general‑purpose AI systems (Gemini 1.5 Pro, 2.0 Flash, 2.5 Flash, and 2.5 Pro). Each model was asked a simple question: was the event epileptic or functional? The AI also had to state how confident it felt on a 1–10 scale. The team compared the AI’s answers with the hospital diagnoses and calculated standard measures such as accuracy, sensitivity (how often epileptic seizures were correctly spotted), and specificity (how often functional seizures were correctly ruled out).
What the AI got right—and wrong
Newer versions of the AI did better than older ones, but none came close to replacing a specialist. Overall diagnostic accuracy climbed from about one‑third correct in the earliest model to just over half correct in the two most recent models. The latest system, Gemini 2.5 Pro, was the most balanced: it detected a little more than half of the epileptic seizures and correctly rejected most, but not all, functional seizures. Earlier versions were extremely cautious: they almost never mislabeled functional seizures, but they missed the vast majority of epileptic ones. Importantly, a naive strategy of simply calling every event “epileptic” would have produced a higher raw accuracy than any model—yet would completely fail to distinguish between the two conditions, underscoring how challenging this task is.
Why video details matter so much
The study also revealed that the quality and framing of the video strongly influenced AI performance. When recordings were clear, well lit, and focused on the upper body or face, the newest models were correct in roughly 80–90 percent of cases within that subset. When the entire body was shown from a distance, or the lighting was poor, accuracy dropped sharply, sometimes to near zero. The type of seizure also made a difference: early AI versions essentially failed on subtler, non‑shaking events, while later versions were somewhat better balanced between obvious shaking and less dramatic episodes. Yet across all models, confidence scores stayed high whether the answer was right or wrong, meaning the AI was often “confidently wrong”—a worrying trait if clinicians or patients were to rely on these judgments.
What this means for patients and doctors
For now, the message is clear: general‑purpose AI can notice patterns in seizure videos and is slowly improving, but it remains far from trustworthy as a stand‑alone diagnostic tool. The systems still miss many epileptic seizures, struggle with subtle events, and do not yet know when they might be wrong. The authors argue that future versions will need training on much larger collections of high‑quality, expert‑labeled medical videos, better ways of expressing uncertainty, and closer integration with patients’ histories and brain‑wave recordings. Rather than replacing neurologists, these tools are more likely to become part of a broader, human‑centered approach in which smartphones, specialists, and carefully designed AI work together to speed up and sharpen seizure diagnosis.
Citation: Patel, A., Vallamchetla, S.K., Safa, A. et al. Diagnostic accuracy of multimodal large language models in differentiating epileptic from functional seizures in smartphone recorded videos. Sci Rep 16, 11719 (2026). https://doi.org/10.1038/s41598-026-46333-z
Keywords: epilepsy, seizure videos, artificial intelligence, large language models, medical diagnosis