Clear Sky Science · ja
スマートフォンで録画した映像における発作の鑑別における多モーダル大型言語モデルの診断精度
なぜスマホ動画が発作診断に役立つのか
誰かが突然倒れたり痙攣し始めたりすると、周囲の人々は今やスマートフォンを取り出して録画することがよくあります。こうした動画は命を救う手がかりになり得て、医師がその出来事がてんかん発作か、それとも機能性発作と呼ばれる類似の発作かを判断する助けになります。しかし、専門の神経科医は不足しており、専門家の確認を待つことで治療が遅れることがあります。本研究は、現代の人工知能、具体的には多モーダル大型言語モデルが、このような日常的なスマホ映像を単独で解析し、両者を見分けられるかを問います。
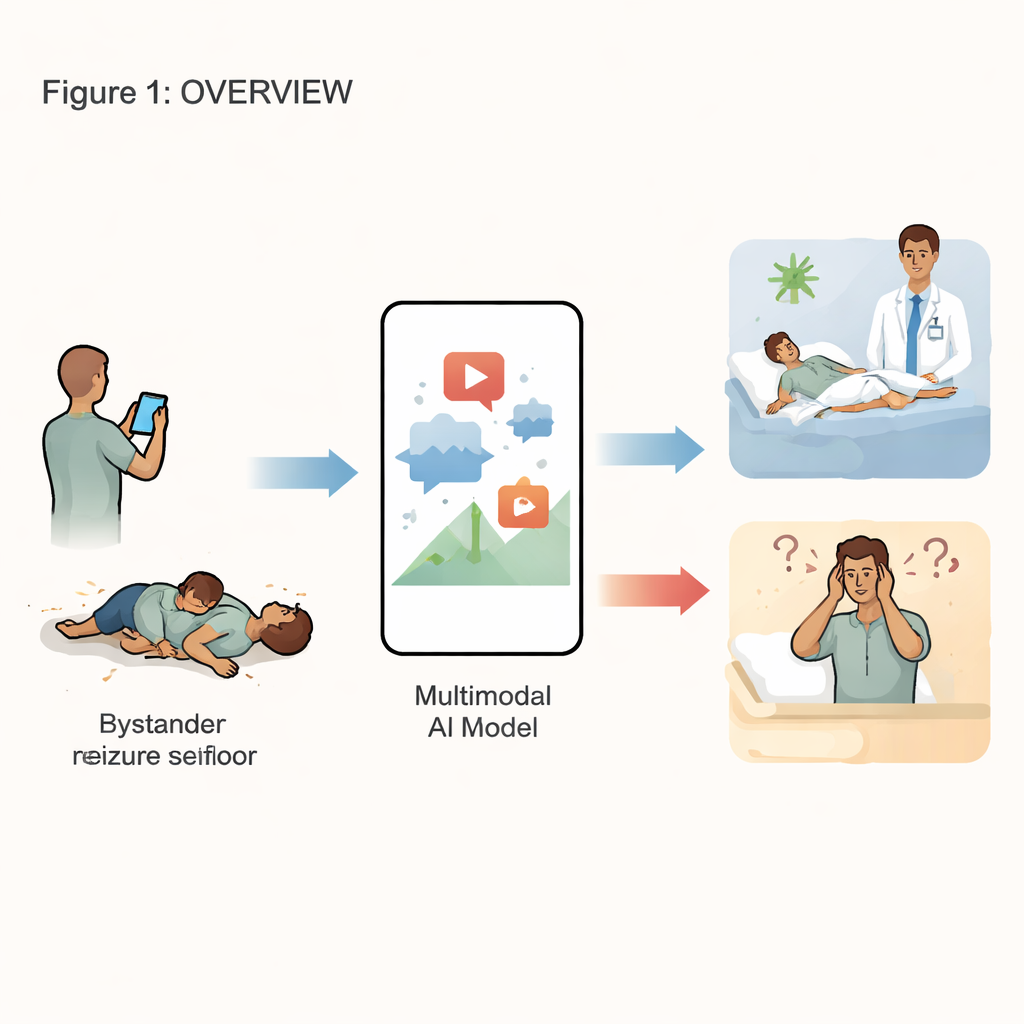
似たように見える二つの緊急事態
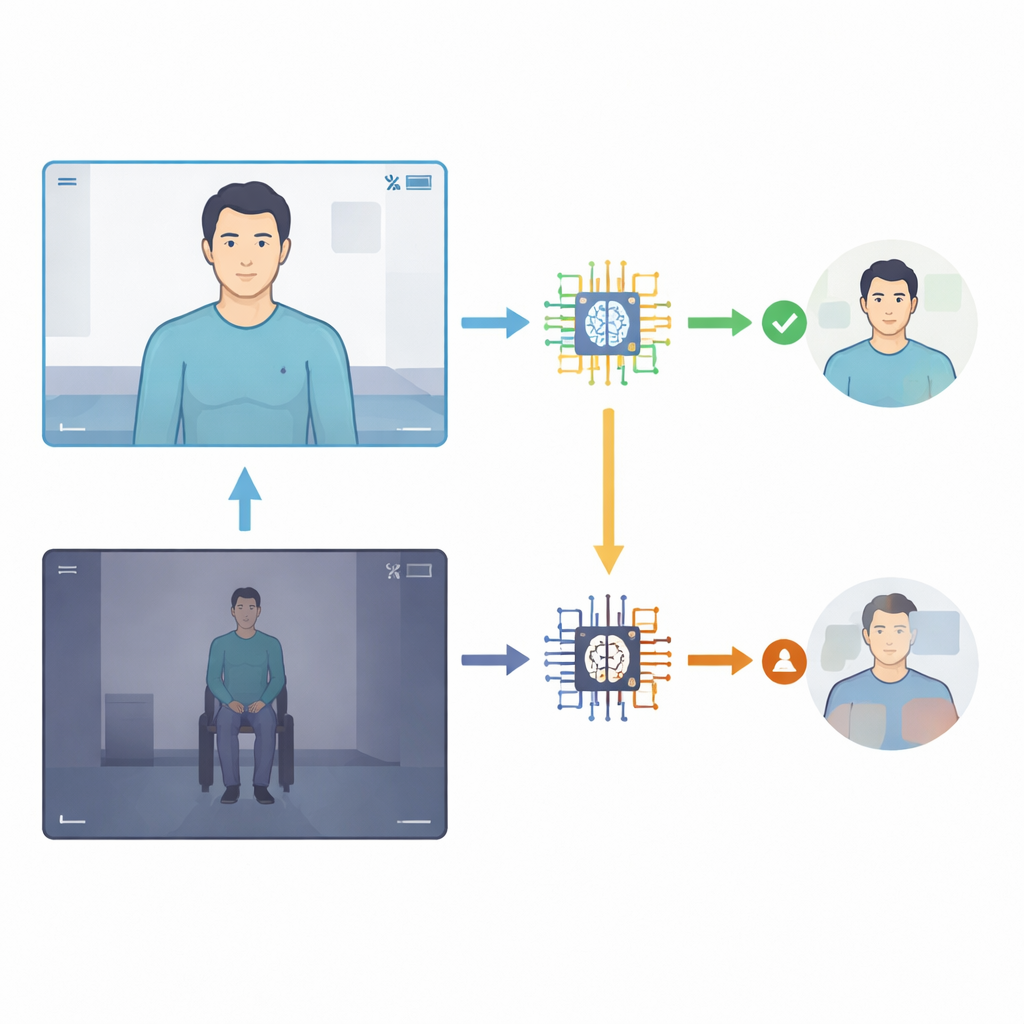
てんかん発作と機能性発作は、訓練を受けていない目には似て見えることがありますが、原因や治療は大きく異なります。てんかん発作は脳内の異常な電気活動に起因し、通常は薬物療法や手術で治療されます。一方、機能性発作はそうした脳波の放電によって引き起こされるわけではなく、複雑な脳と心の相互作用に根ざした実際に苦痛を伴う出来事であり、しばしば心理的支援を含む異なるケアが必要です。出来事は短時間で恐ろしいため、家族が正確に説明するのは難しいことが多い。現場で撮影されたビデオはより忠実な様子を伝えますが、解釈には依然として熟練したてんかん専門医へのアクセスが必要です。
汎用AIを試す
ある主要なてんかんセンターの研究者たちは、入院のビデオ脳波(video–EEG)検査で慎重に診断された15人の成人から、スマートフォンで撮影された24本の動画を収集しました。うち19本はてんかん発作を、5本は機能性発作を示していました。研究者は各動画を、背景の医療情報を一切与えずに、汎用AIシステムの一族の4つのバージョン(Gemini 1.5 Pro、2.0 Flash、2.5 Flash、2.5 Pro)に入力しました。各モデルには単純な質問が投げられました:その出来事はてんかん性か機能性か? また、AIは1〜10の尺度でどれほど自信があるかも示す必要がありました。研究チームはAIの回答を病院の診断と比較し、精度、感度(てんかん発作を正しく検出した頻度)、特異度(機能性発作を正しく除外した頻度)などの標準的な指標を算出しました。
AIが正しく判断した点と誤った点
新しいバージョンほど古いものよりも良好でしたが、どれも専門医に取って代わるには遠く及びませんでした。全体の診断精度は、最も初期のモデルで約3分の1の正答率から、最新の2モデルでやっと半分少しを超える正答率に上がりました。もっともバランスが取れていたのは最新のGemini 2.5 Proで、てんかん発作の半分強を検出し、ほとんどの(ただしすべてではない)機能性発作を正しく棄却しました。初期のバージョンは極めて慎重で、機能性発作を誤分類することはほとんどなかった一方で、てんかん発作の大部分を見逃していました。重要なのは、すべての出来事を単純に「てんかん性」と呼ぶ素朴な戦略は、生の正答率においてどのモデルよりも高い結果を出しただろうが、両者を区別する能力は全くないことから、このタスクがいかに困難かを強調している点です。
なぜ映像の細部がこれほど重要なのか
研究はまた、映像の品質とフレーミングがAIの性能に強く影響することを明らかにしました。記録が鮮明で十分に照明され、上半身や顔に焦点が合っている場合、最新モデルはそのサブセットでおよそ80〜90%の正答率を示しました。全身が遠距離で映っている、あるいは照明が不十分な場合には精度が急落し、時にほぼゼロにまで落ちることもありました。発作のタイプも違いを生みました:初期のAIバージョンは微妙で非痙攣性の発作では事実上失敗していましたが、後のバージョンは明らかな痙攣と比較的地味な発作の間でやや均衡が取れていました。それでも、すべてのモデルに共通して、正誤にかかわらず自信スコアが高いままであるため、AIはしばしば「自信を持って間違う」— これは臨床家や患者がこれらの判断に頼る場合に憂慮すべき特徴です。
患者と医師にとっての意味
現時点での結論は明確です:汎用AIは発作動画の中のパターンを認識することができ、徐々に改善しているものの、独立した診断ツールとしてはまだ信頼に足りません。システムは依然として多くのてんかん発作を見逃し、微妙な発作に苦戦し、自分が誤っている可能性を十分に示せません。著者らは、将来のバージョンには、より大規模で高品質な専門家ラベル付き医療動画での訓練、不確実性を表現するより良い方法、および患者の既往歴や脳波記録とのより緊密な統合が必要だと論じています。これらのツールは神経科医に取って代わるのではなく、スマートフォン、専門家、慎重に設計されたAIが協力して発作診断を迅速かつ精度高くする、人間中心のより広いアプローチの一部となる可能性が高いでしょう。
引用: Patel, A., Vallamchetla, S.K., Safa, A. et al. Diagnostic accuracy of multimodal large language models in differentiating epileptic from functional seizures in smartphone recorded videos. Sci Rep 16, 11719 (2026). https://doi.org/10.1038/s41598-026-46333-z
キーワード: てんかん, 発作動画, 人工知能, 大型言語モデル, 医療診断