Clear Sky Science · zh
在顺序抽样模型框架下的选择引起的偏好改变
为何我们的选择会重塑我们的喜好
想象你在巧克力和橘子之间二选一,而你对两者的喜好相当。奇怪的是,选完之后,你可能会更喜欢所选的零食,同时对被拒绝的那一项减少好感。这一日常现象称为选择引起的偏好改变,几十年来已有大量记录。然而,许多主流的数学决策模型难以解释这种现象。本文展示了当我们允许价值在决策过程中演化时,一类流行的模型——顺序抽样模型——如何自然而然地产生这种偏好位移。
心理学家通常如何看待决策
大量决策研究关注两个选项之间的简单选择。在做出选择之前,人们常会对每个选项打分。经典发现表明,当选项吸引力相近时,选择更慢且更不可预测;当某一选项明显突出或两者都价值很高时,选择更快且更一致。当选项在关键特征上差异很大(例如食物的味道与健康)时,决策也更迅速。这些模式被顺序抽样模型很好地捕捉:该模型设想大脑逐步收集带噪声的证据片段,直到某一选项获得足够支持越过决策阈值。
我们做出决定后喜好为何改变
选择引起的偏好改变超出了这些标准模式。在许多实验中,参与者先对物品评分,随后在成对物品之间做出选择,然后再重新评分。通常所选物品的评分上升,被拒物品的评分下降,两者差距扩大。这种“选项分化”在困难决策中最为明显——当初始评分接近或不确定性较高时——以及在每个选项在不同属性上各有优势的选择中也更强。它也倾向于在人们决定迅速且自信时更大。仅靠测量噪声的简单解释无法完全说明这些与难度、属性差异和反应时的可靠关联。
让价值在审议过程中演化
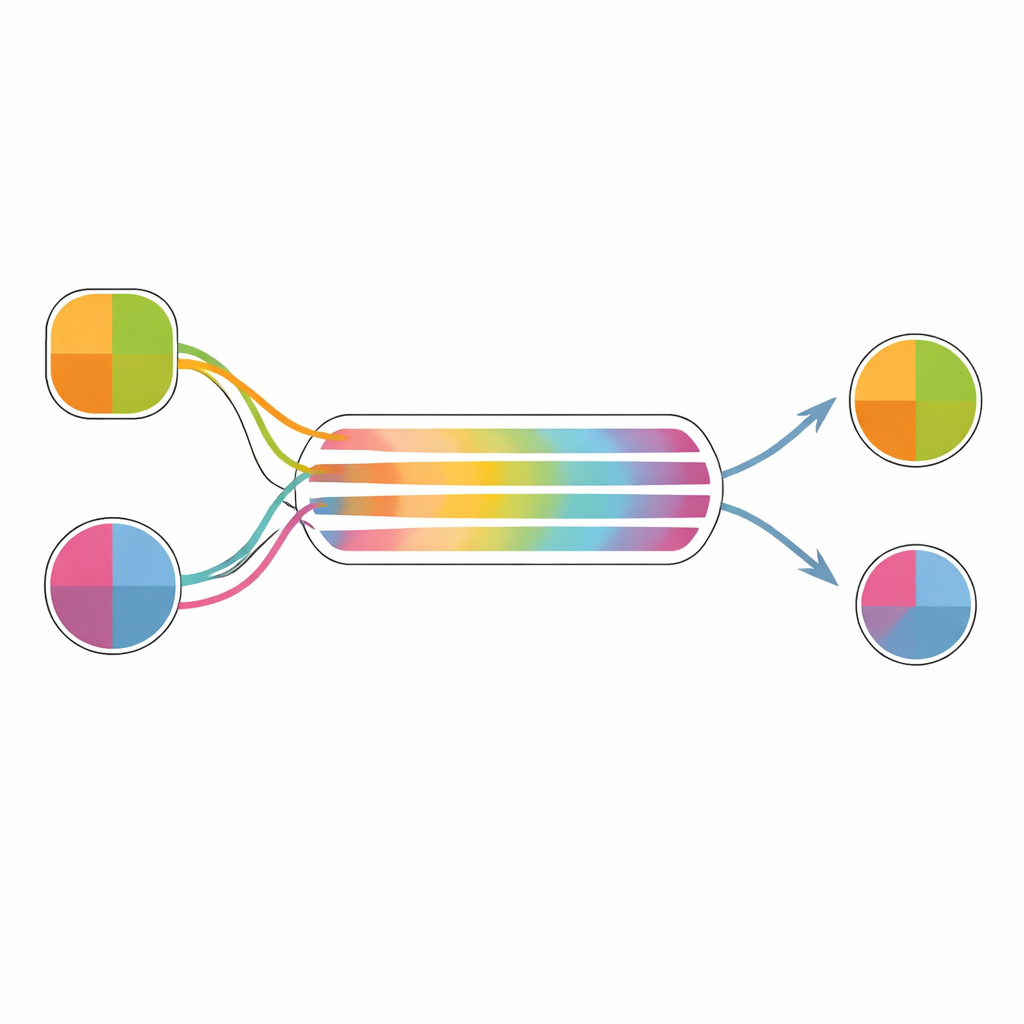
标准的顺序抽样模型假定每个选项在决策期间具有固定的内在价值;模型只是通过累积证据来揭示该价值。在这个假设下,价值本身没有变化的余地。作者对这一点提出挑战,允许证据质量随时间改变。在他们的框架中,早期证据反映粗略的先验印象,而更困难的决策会促使决策者考虑额外的属性或信息,这些在一开始并未被充分权衡。例如,当仅凭美味无法在巧克力和橘子之间做出决定时,人可能开始将健康因素纳入考量,这会使演化中的证据倾向橘子,从而改变两者之间的内部价值差距。
在真实数据上测试不同的决策引擎
为了检验这一想法是否在实践中有效,作者使用早期零食选择实验的真实数据进行了模拟。参与者对食物的总体价值、愉悦度和营养进行了评分,然后做出选择并再次评分。作者对每位参与者的选择和反应时拟合了三种相关的决策模型:将价值视为单一量的基本漂移-扩散模型;分别对愉悦度和营养累积证据的多属性版本;以及一个扩展模型,其中不同属性在不同时间开始影响决策。利用拟合的模型,他们模拟了大量决策,并基于模型“最终”价值差异与初始评分所暗示的差异计算内部偏好改变的度量。
模型揭示了关于改变想法的什么
三种模型变体均再现了偏好分化平均为正且在困难决策中更大的事实。基本模型主要通过噪声实现这一点:当证据漂移缓慢时,随机波动有更多时间将最终价值差异推离初始值。然而,只有显式跟踪不同属性的模型才能模拟经验发现——即当选项在属性组合上差异显著时,偏好分化会增大。这些更丰富的模型也捕捉到了反应更快的决策伴随更大偏好位移的观测联系,反映出更强的有效证据既加速了选择又使内部价值更分化。允许属性在不同时间进入决策过程的模型与数据的定性匹配最为接近。
这对日常选择意味着什么
对非专业读者来说,主要信息是我们并非在选择时简单地发现固定的偏好;我们在选择行为中会主动精炼并有时重塑偏好。通过用多个演化中的证据流丰富这一成熟的决策框架,这项工作表明,我们在选择后对所选对象的吸引力可以从支配我们决策速度和可靠性的同一基本过程中产生。换言之,大脑逐步权衡不同属性的过程不仅决定了哪个选项胜出,也有助于形成我们随后讲述给自己关于喜好的故事。
引用: Lee, D.G., Pezzulo, G. Choice-induced preference change under a sequential sampling model framework. Sci Rep 16, 14455 (2026). https://doi.org/10.1038/s41598-026-44610-5
关键词: 决策, 偏好改变, 漂移扩散模型, 基于价值的选择, 认知建模