Clear Sky Science · ja
逐次サンプリングモデルの枠組みにおける選択誘発的嗜好変化
なぜ私たちの選択は好みを変えるのか
チョコレートバーと同じくらい好きなオレンジのどちらかを選ぶ場面を想像してください。不思議なことに、選んだ方をますます好むようになり、選ばなかった方をより嫌うようになることがあります。この日常的な現象は「選択誘発的嗜好変化」として何十年も記録されてきました。しかし多くの主要な意思決定モデルはそれを説明するのに苦労してきました。本論文は、逐次サンプリングモデルと呼ばれる一般的なモデル群が、意思決定の過程で価値が変化することを許すと、こうした嗜好の変化を自然に生み出せることを示します。
心理学者が通常考える意思決定像
意思決定の多くの研究は二者択一の簡単な選択を扱います。選択前に、人々はしばしば各選択肢にどれだけ好感を抱くか評価します。古典的な知見では、選択肢の魅力が似ていると選択は遅く予測しにくくなり、いずれかが明確に優れているか両方が高評価ならばより速く一貫した選択が行われます。食品では味と健康性のような重要な属性で差が大きいと選択は速くなります。こうしたパターンは、脳がノイズのある証拠を徐々に集め、いずれかの選択肢の支持が閾値を越えるまで蓄積する、という逐次サンプリングモデルによってよく説明されてきました。
決めた後に好みが変わるとき
選択誘発的嗜好変化はこれらの標準的なパターンを超えます。多くの実験では、項目を評価し、ペアで選択を行い、再び評価するという手順が取られます。典型的には、選ばれた項目の評価は上がり、拒否された項目の評価は下がり、それらの差は広がります。この「選択肢の拡がり」は、もともとの評価が近かったり不確実性が高い「難しい」決定で最も強く、各選択肢が異なる属性で強みを持つ場合にも大きくなります。また、人が素早く決め自信を感じる場合により大きくなる傾向があります。測定ノイズだけを根拠にした単純な説明では、難易度、属性、反応時間といったこれらの安定した関連性を完全には説明できません。
熟考の間に価値を変化させる
標準的な逐次サンプリングモデルは、各選択肢に決定中に固定された基礎的価値があると仮定し、モデルはただその価値を明らかにするだけだと考えます。この仮定の下では、価値自体が変わる余地はありません。著者たちはこれに異議を唱え、証拠の質が時間とともに変わり得ることを許しました。この枠組みでは、初期の証拠は粗い事前印象を反映し、困難な決定では意思決定者が開始時に十分に考慮していなかった追加の属性や情報を検討するようになります。たとえば、味だけではチョコとオレンジのどちらかを決められないとき、人は健康面を考慮し始め、それが時間とともに証拠をオレンジ寄りに傾け、二者間の内部的な価値差を変化させるかもしれません。
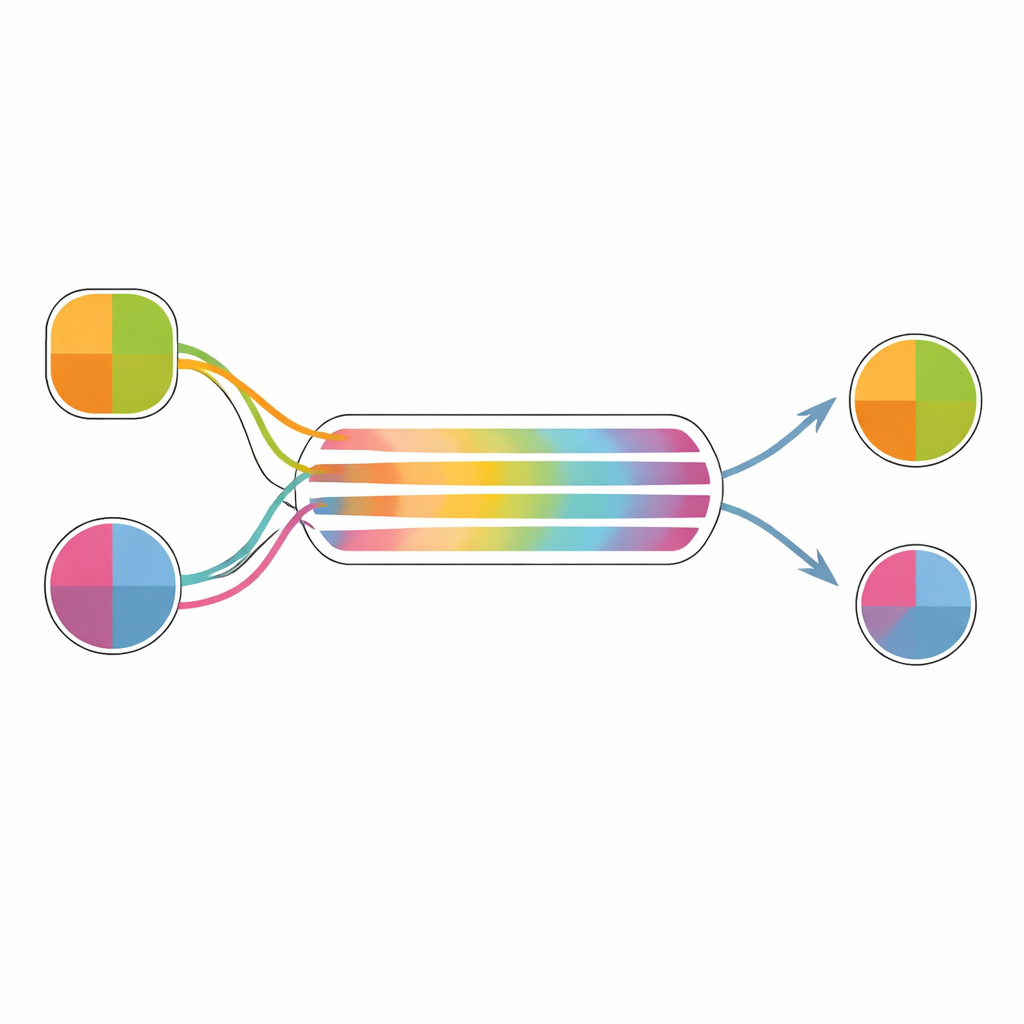
実データで異なる意思決定メカニズムを検証する
この考えが実際に機能するかを確認するため、著者たちは過去のスナック選択実験の実データを用いて選択をシミュレートしました。参加者は食品を総合的な価値と快楽性および栄養性で評価し、選択を行い、再評価しました。著者たちは各参加者の選択と反応時間に対して三つの関連モデルを当てはめました:価値を単一の量として扱う基本的なドリフト–拡散モデル、快楽と栄養を別々に蓄積する多属性バージョン、そして異なる属性が異なる時間で意思決定に影響を与え始める拡張モデルです。フィットしたモデルを使って多数の決定をシミュレートし、モデルの「最終的な」価値差が初期評価からどれだけずれているかに基づいた内部的な嗜好変化の指標を算出しました。
心の変化についてモデルが示すこと
三つのモデル変種はいずれも、平均して選択肢の拡がりが正であり、難しい決定でより大きくなるという事実を再現しました。基本モデルは主にノイズを通じてこれを達成しました:証拠のドリフトが遅いとき、ランダムな変動が最終的な価値差を初期から押し離す時間が長くなります。しかし、選択肢が属性の組み合わせで強く異なるときに嗜好の拡がりが増すという実証的所見を模倣できたのは、別々の属性を明示的に追跡するモデルだけでした。これらのより豊かなモデルは、より強い有効証拠が選択を速めると同時に内部的価値をさらに離れさせるという、速い決定と大きな嗜好変化の観察された関連も捉えました。属性が異なる時点で意思決定に入り始めることを許すことが、データへの質的に最も近い一致をもたらしました。
日常の選択にとっての意味
専門外の読者にとっての主なメッセージは、選ぶときに単に固定された嗜好を発見しているわけではなく、選択の行為の最中にそれを能動的に精練し時に書き換えている、ということです。よく確立された意思決定の枠組みを、複数の進化する証拠の流れで豊かにすることで、本研究は、選択後に私たちが選んだものに引かれる現象が、どれだけ速くどれだけ確実に決めるかを支配する同じ基本的過程から生じ得ることを示しました。言い換えれば、さまざまな属性を心が徐々に秤にかけることが、どの選択肢が勝つかを決めるだけでなく、後に自分が何を好むかについて語る物語をも形作っているのです。
引用: Lee, D.G., Pezzulo, G. Choice-induced preference change under a sequential sampling model framework. Sci Rep 16, 14455 (2026). https://doi.org/10.1038/s41598-026-44610-5
キーワード: 意思決定, 嗜好の変化, ドリフト拡散モデル, 価値に基づく選択, 認知モデリング