Clear Sky Science · nl
Keuze-geïnduceerde voorkeursverandering binnen een framework van sequentiële monstername-modellen
Waarom onze keuzes bepalen wat we leuk vinden
Stel je voor dat je moet kiezen tussen een chocoladereep en een sinaasappel die je even graag lust. Vreemd genoeg kun je, nadat je er één hebt gekozen, de gekozen snack aantrekkelijker gaan vinden en de afgewezen juist minder. Deze alledaagse eigenaardigheid, bekend als keuze-geïnduceerde voorkeursverandering, is al tientallen jaren gedocumenteerd. Toch konden veel vooraanstaande wiskundige modellen van besluitvorming het niet goed verklaren. Dit artikel laat zien hoe een populaire klasse modellen, sequentiële monstername-modellen genoemd, deze voorkeursverschuiving op natuurlijke wijze kunnen voortbrengen zodra we toestaan dat waardes tijdens het besluit zelf evolueren.
Hoe psychologen doorgaans over beslissingen denken
Veel onderzoek naar besluitvorming richt zich op eenvoudige keuzes tussen twee opties. Voordat ze kiezen, geven mensen vaak aan hoezeer ze elke optie waarderen. Klassieke bevindingen laten zien dat keuzes trager en minder voorspelbaar zijn wanneer opties vergelijkbaar aantrekkelijk zijn, en sneller en consistenter wanneer één optie duidelijk uitsteekt of wanneer beide opties hoog gewaardeerd worden. Keuzes zijn ook sneller wanneer de opties sterk verschillen op kernattributen, zoals smaak versus gezondheid bij voeding. Deze patronen zijn zeer goed vastgelegd door sequentiële monstername-modellen, die zich voorstellen dat de hersenen geleidelijk ruisachtige bewijsstukken verzamelen totdat één optie genoeg ondersteuning heeft om een besluitdrempel te overschrijden.
Wanneer voorkeuren veranderen nadat we beslissen
Keuze-geïnduceerde voorkeursverandering gaat verder dan deze standaardpatronen. In veel experimenten beoordelen mensen items, maken keuzes tussen paren en beoordelen de items daarna opnieuw. Typisch stijgt de waardering van het gekozen item, daalt die van het afgewezen item, en wordt de kloof tussen hen groter. Deze “spreiding van alternatieven” is het sterkst bij moeilijke beslissingen—wanneer de initiële beoordelingen dicht bij elkaar lagen of minder zeker waren—en bij keuzes waarbij elke optie sterk scoort op verschillende attributen. Het is ook vaak groter wanneer mensen snel beslissen en zich zelfverzekerd voelen. Eenvoudige verklaringen die louter op meetruis zijn gebaseerd, kunnen deze betrouwbare verbanden met moeilijkheid, attributen en reactietijden niet volledig verklaren.
Waardes laten evolueren tijdens beraad
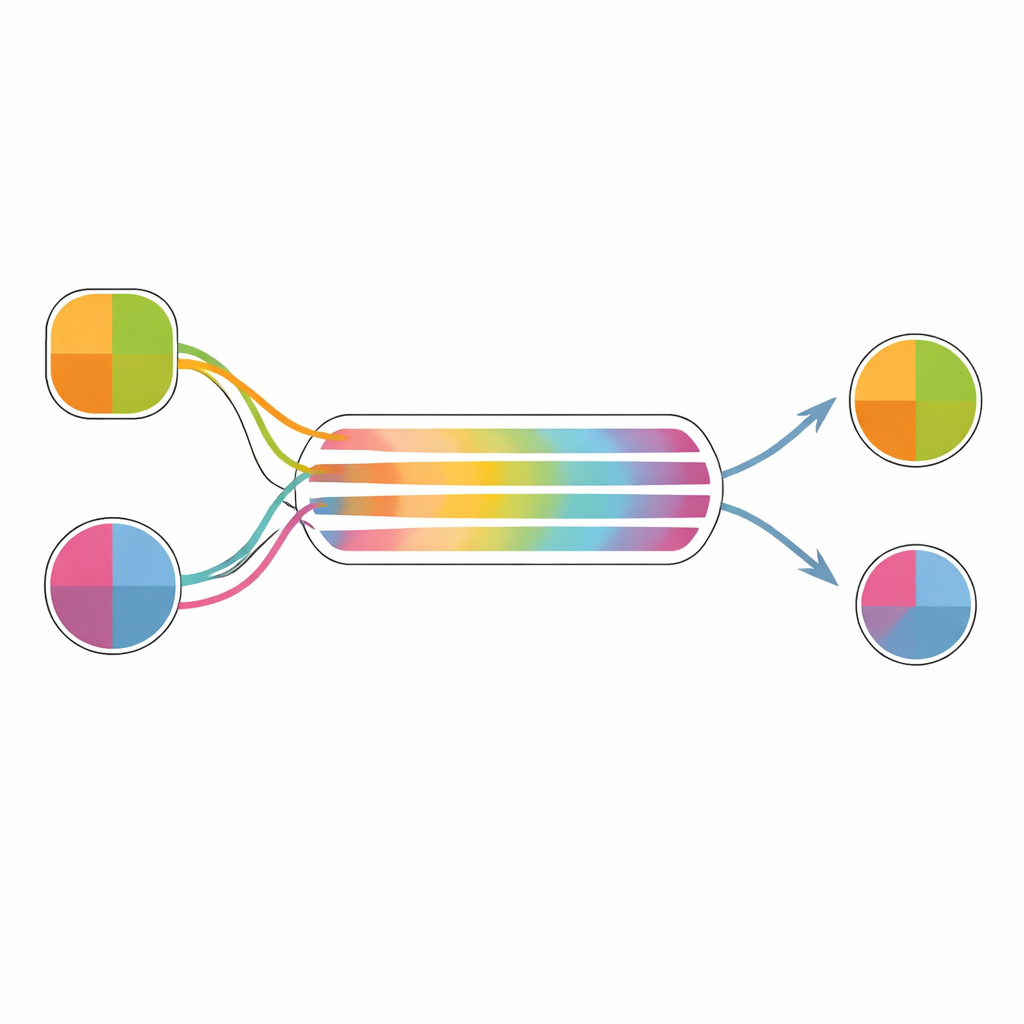
Standaard sequentiële monstername-modellen veronderstellen dat elke optie tijdens een beslissing een vaste onderliggende waarde heeft; het model onthult deze waarde slechts door bewijs op te accumuleren. Onder deze aanname is er geen ruimte voor verschuivende waardes zelf. De auteurs dagen dit uit door toe te staan dat de kwaliteit van het bewijs in de tijd verandert. In hun raamwerk weerspiegelt vroeg bewijs ruwe eerdere indrukken, terwijl moeilijkere beslissingen de besluitvormer ertoe aanzetten extra attributen of informatie te overwegen die aanvankelijk niet volledig waren meegewogen. Bijvoorbeeld: als alleen smaak niet kan beslissen tussen chocolade en een sinaasappel, kan iemand beginnen gezondheid mee te rekenen, waardoor het evoluerende bewijs in het voordeel van de sinaasappel kantelt en de interne waardekloof tussen de twee snacks verandert.
Verschillende besluitmotoren testen op echte data
Om te zien of dit idee in de praktijk werkt, simuleerden de auteurs keuzes met echte data uit eerdere snack-keuze-experimenten. Deelnemers hadden voedingsmiddelen beoordeeld op algemene waarde en op plezier en voeding, maakten daarna keuzes en beoordeelden opnieuw. De auteurs pasten drie verwante beslismodellen toe op ieders keuzes en reactietijden: een basis drift–diffusiemodel dat waarde als één enkele grootheid behandelt; een multi-attribuutversie die bewijs afzonderlijk accumuleert voor plezier en voeding; en een uitgebreid model waarin verschillende attributen op verschillende tijden beginnen mee te wegen in de beslissing. Met de gefitte modellen simuleerden ze vele beslissingen en berekenden ze een interne maat voor voorkeursverandering op basis van hoeveel het model’s “definitieve” waardeverchil afweek van dat wat uit de initiële beoordelingen bleek.
Wat de modellen onthullen over veranderende keuzes
Alle drie modelvarianten reproduceerden het feit dat preferentspreiding gemiddeld positief is en groter voor moeilijke beslissingen. Het basismodel verkreeg dit voornamelijk via ruis: wanneer bewijs langzaam drift, hebben toevallige fluctuaties meer tijd om het uiteindelijke waardeverchil weg te duwen van het initiële. Echter, alleen de modellen die expliciet afzonderlijke attributen bijhielden konden het empirische resultaat nabootsen dat preferentspreiding toeneemt wanneer de opties sterk verschillen in hun mix van attributen. Deze rijkere modellen vingen ook het waargenomen verband tussen snellere beslissingen en grotere voorkeursverschuivingen, wat weerspiegelt dat sterker effectief bewijs zowel keuzes versnelt als interne waardes verder uit elkaar drijft. Toestaan dat attributen op verschillende tijden in de beslissing toetreden gaf de meest overeenkomende kwalitatieve match met de data.
Wat dit betekent voor alledaagse keuzes
Voor niet-specialisten is de belangrijkste boodschap dat we niet simpelweg vaste voorkeuren ontdekken wanneer we kiezen; we verfijnen en herscheppen ze soms actief tijdens het kiezen zelf. Door een goed gevestigde besliskader te verrijken met meerdere evoluerende bewijsstromen, toont dit werk dat onze aantrekkingskracht tot wat we gekozen hebben na de keuze kan voortkomen uit hetzelfde basale proces dat bepaalt hoe snel en betrouwbaar we beslissen. Met andere woorden: het geleidelijk afwegen van verschillende attributen door de geest bepaalt niet alleen welke optie wint, het helpt ook het verhaal te schrijven dat we ons later vertellen over wat we graag hebben.
Bronvermelding: Lee, D.G., Pezzulo, G. Choice-induced preference change under a sequential sampling model framework. Sci Rep 16, 14455 (2026). https://doi.org/10.1038/s41598-026-44610-5
Trefwoorden: besluitvorming, voorkeursverandering, drift-diffusiemodel, waarde-gebaseerde keuze, cognitieve modellering