Clear Sky Science · zh
PoseConv3D 算法在拉拉队训练动作识别中的应用
为高速运动提供更智能的训练指导
如今的拉拉队已远不只是场边助威;它是一项对体能与技巧要求极高的杂技性团体运动,时间和姿势上的细微失误就可能导致精彩动作变成危险坠落。然而大多数训练仍依赖教练的肉眼和慢速视频回放。本文介绍了一种人工智能系统,能逐帧观看拉拉队表演、理解运动员的身体姿态,并自动识别所做动作及其难度,从而为更安全、更精确、更个性化的训练打开了可能性。
为什么拉拉队姿态识别尤其具有挑战性
许多运动和日常活动已被计算机视觉研究过,但拉拉队将现有方法推到了极限。运动员每秒多次旋转、在空中翻腾,并构成多人体金字塔,身体重叠遮挡了相机视角。空间上看似相似的动作——例如手臂挥动与高踢——可能主要在节奏上不同,而标准算法往往忽视节奏。因此,常见的动作识别系统会误判关键关节位置、在团体特技中丢失个体追踪,并混淆具有相似运动轨迹的动作,导致在真实训练场景中准确率低且反馈不可靠。
将视频转为干净的数字骨架
该新系统基于一种基于姿态的三维卷积网络 PoseConv3D,处理的不是原始像素而是从视频中提取的简化“火柴人”骨架。首要创新是一个动态校正步骤,用于清理这些骨架。当底层姿态检测器对某个关节不确定时——例如旋转时模糊的手腕——系统会利用平滑曲线预测其随时间的最可能轨迹,这些曲线遵循相邻帧的运动。该方法将关节位置的抖动和漂移减少了超过 40%,使学习算法在快速旋转和空中特技过渡期间能更清晰地捕捉到运动员身体的真实运动。
同时观察细节与大尺度团队模式
骨架清理后,系统以多尺度同时分析运动。一条处理分支聚焦于快速的细微动作,如手腕的瞬间甩动或脚踝的蹬地;另一条分支则观察更广泛的模式,比如腿部的扫弧或多人抬举时的整体上升。通过融合这些视角,模型更好地理解小幅调整如何影响团队层面的编队。基于中佛罗里达大学专门构建的数据集进行的测试——该数据集包含 500 多个高分辨率训练和比赛片段,并对动作与难度进行了精细标注——表明这种多尺度方法显著提升了对复杂、高度协同特技的识别能力。
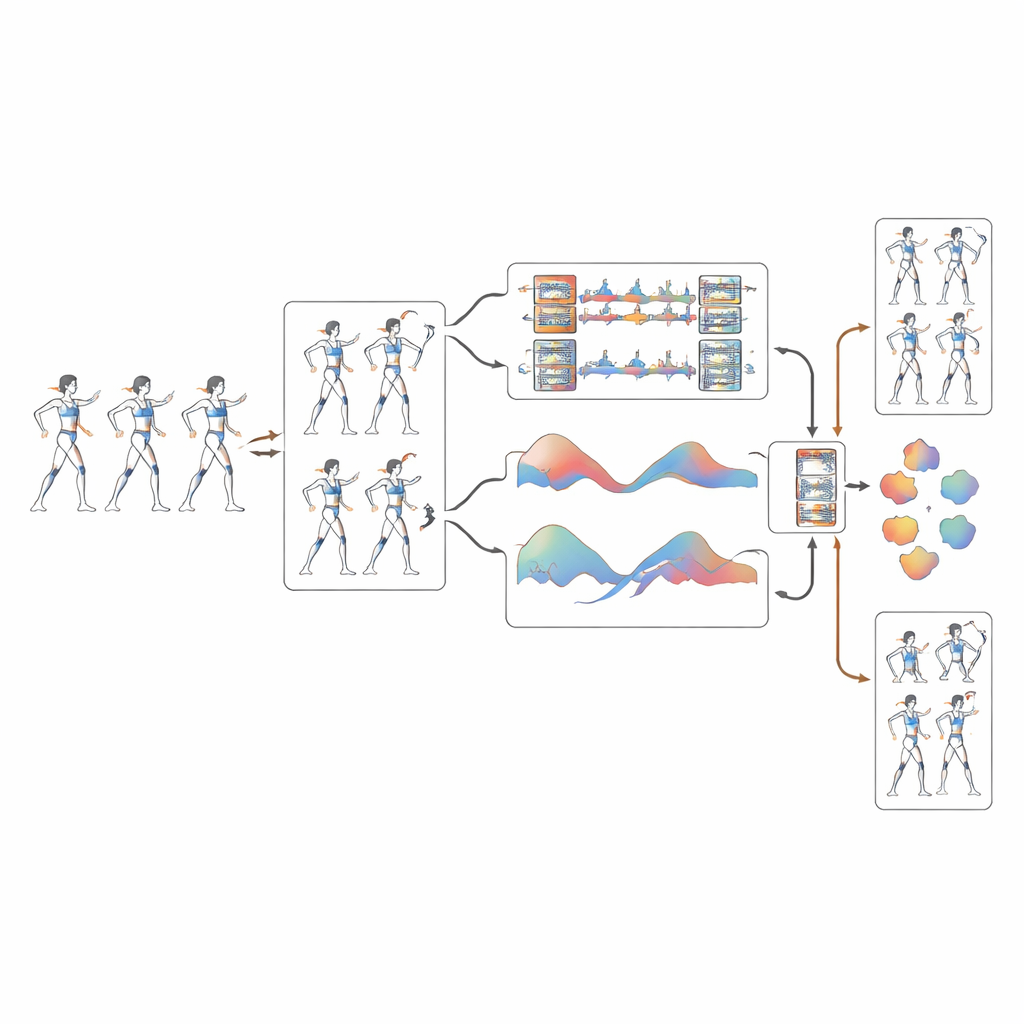
教会系统“听”节拍
这项工作的一个突出特点是算法不仅观察运动员在空间中的动作,还学习他们在何时移动。研究者计算每个关节在帧间的速度变化,并将这些变化转化为节奏模式,类似于将音乐转换为节拍频谱。一个特殊的注意力模块会突出那些与关键节奏特征相匹配的动作时刻。这使系统能够可靠地区分那些轨迹几乎相同但节奏不同的动作,将波浪状动作与同步踢腿的混淆率从大约每六次中有一次,降低到每百次中只有几次。
从识别到实时训练伙伴
在流水线的末端,系统同时输出两项信息:执行的拉拉队动作类型以及与比赛规则一致的难度估计。系统以近 90 帧每秒的速度运行,远超实时反馈所需的速度。总体准确率约为 93%,明显优于若干最先进方法。对于运动员和教练而言,这意味着一个能在动作发生时自动标记时机错误的挥动、不稳定的着地或团队同步缺口的助手,同时还能跟踪对越来越高难度技能的进步——为数据驱动、更安全、更精细的拉拉队训练迈出了一大步。
引用: Li, Q. Application of PoseConv3D algorithm in cheerleading training action recognition. Sci Rep 16, 12265 (2026). https://doi.org/10.1038/s41598-026-43019-4
关键词: 拉拉队, 动作识别, 姿态估计, 体育分析, 深度学习