Clear Sky Science · fr
Application de l’algorithme PoseConv3D à la reconnaissance des actions dans l’entraînement de cheerleading
Un entraînement plus intelligent pour un sport à haute vitesse
Le cheerleading n’est plus aujourd’hui une simple animation de bord de terrain ; c’est un sport d’équipe acrobatique exigeant où de petites erreurs de synchronisation ou de posture peuvent faire la différence entre une figure propre et une chute dangereuse. Pourtant, l’encadrement repose encore majoritairement sur l’œil humain et les ralentis vidéo. Cet article présente un système d’intelligence artificielle capable d’analyser les routines de cheerleading image par image, d’interpréter la position des corps et de reconnaître automatiquement à la fois quel mouvement est exécuté et son niveau de difficulté, ouvrant la voie à un entraînement plus sûr, plus précis et plus personnalisé.
Pourquoi le cheerleading constitue un défi particulier
De nombreux sports et activités quotidiennes ont déjà été étudiés par vision par ordinateur, mais le cheerleading met les méthodes existantes à l’épreuve. Les athlètes tournent plusieurs fois par seconde, effectuent des saltos en l’air et construisent des pyramides à plusieurs personnes où les corps se superposent et masquent la vue de la caméra. Des mouvements qui semblent similaires spatialement — comme des ondulations de bras et des coups de pied hauts — peuvent surtout se distinguer par leur rythme, un aspect que les algorithmes classiques négligent en grande partie. En conséquence, les systèmes courants de reconnaissance d’action estiment mal des positions articulaires clés, perdent le suivi des individus lors de figures de groupe et confondent des mouvements partageant des trajectoires semblables, entraînant une faible précision et des retours peu fiables dans les gymnases réels.
Transformer les vidéos en squelettes numériques propres
Le nouveau système s’appuie sur un réseau de convolution 3D basé sur la pose, appelé PoseConv3D, qui travaille non pas sur les pixels bruts mais sur des squelettes « en bâton » simplifiés extraits des vidéos. La première innovation est une étape de correction dynamique qui nettoie ces squelettes. Lorsque le détecteur de pose sous-jacent est incertain au sujet d’une articulation — par exemple un poignet flou pendant une rotation — le système prédit sa trajectoire la plus probable dans le temps en utilisant des courbes lisses qui respectent le mouvement des images voisines. Cela réduit le tremblement et la dérive des positions articulaires de plus de 40 %, offrant à l’algorithme d’apprentissage une image beaucoup plus claire de la manière dont le corps de chaque athlète se déplace réellement lors des rotations rapides et des transitions aériennes.
Voir à la fois les petits détails et les grands schémas d’équipe
Une fois les squelettes nettoyés, le système analyse le mouvement à plusieurs échelles simultanément. Une branche de traitement se concentre sur les détails fins tels qu’un rapide coup de poignet ou l’impulsion d’une cheville, tandis qu’une autre examine des motifs plus larges comme l’arc balayé d’une jambe ou la montée coordonnée de plusieurs athlètes lors d’un élevage. En fusionnant ces perspectives, le modèle comprend mieux comment de petits ajustements contribuent à des formations d’équipe à grande échelle. Des tests sur un jeu de données de cheerleading dédié de l’Université de Central Florida — plus de 500 clips haute définition d’entraînement et de compétition avec des mouvements et niveaux de difficulté soigneusement annotés — montrent que cette approche multi-échelle améliore notablement la reconnaissance de figures complexes et fortement coordonnées.
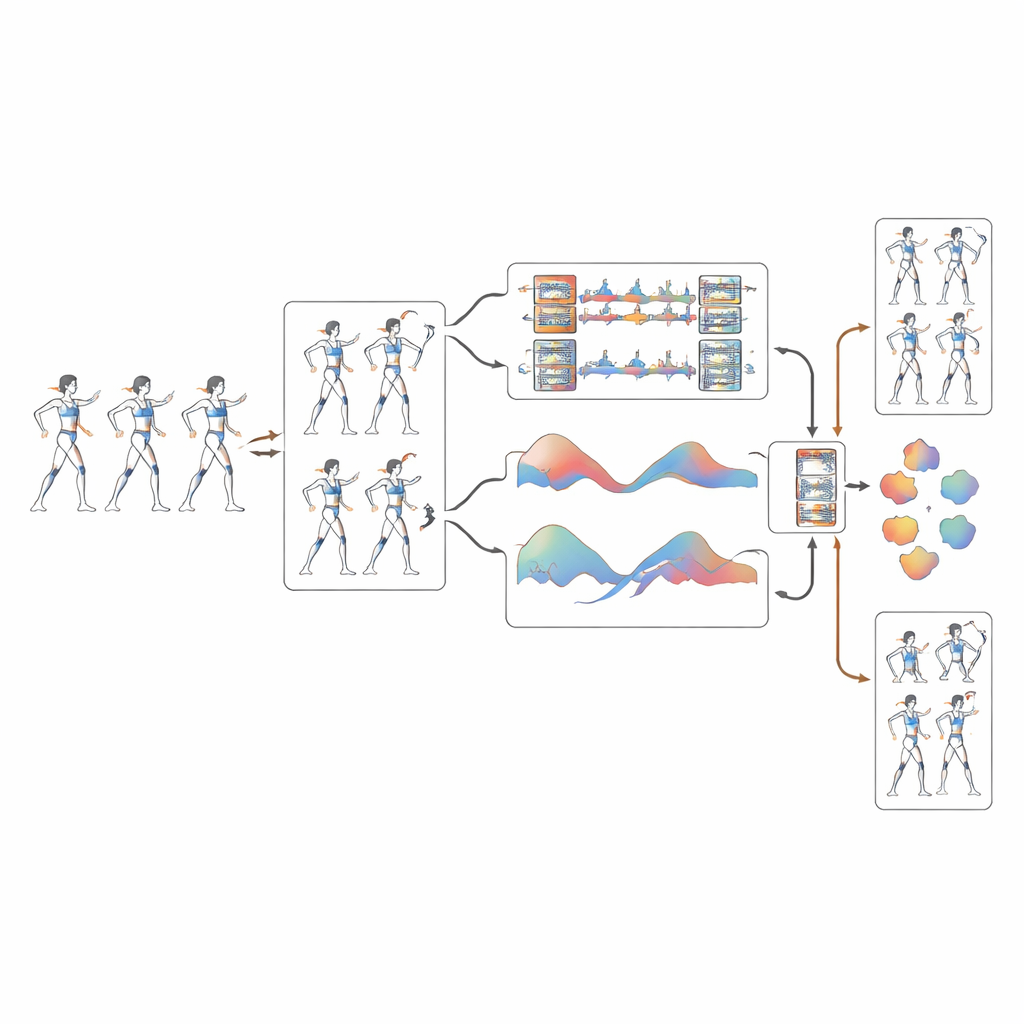
Apprendre au système à percevoir le tempo
Une caractéristique marquante de ce travail est que l’algorithme n’apprend pas seulement comment les athlètes se déplacent dans l’espace ; il apprend aussi quand ils se déplacent. Les chercheurs calculent la vitesse à laquelle chaque articulation se déplace d’une image à l’autre et transforment ces variations en motifs rythmiques, un peu comme convertir de la musique en spectre de temps forts. Un module d’attention spécifique met ensuite en valeur les instants de la séquence de mouvement qui correspondent à des signatures rythmiques clés. Cela permet au système de distinguer de manière fiable des actions qui tracent des trajectoires presque identiques mais se déroulent à des tempos différents, réduisant la confusion entre mouvements ondulatoires et coups de pied synchronisés d’environ une tentative sur six à seulement quelques-unes sur cent.
De la reconnaissance à un partenaire d’entraînement en temps réel
En sortie du pipeline, le système produit simultanément deux informations : le type de figure de cheerleading exécutée et un score de difficulté estimé conforme aux règles de compétition. Fonctionnant à près de 90 images par seconde, il dépasse largement la vitesse requise pour un retour en temps réel. La précision globale atteint environ 93 %, surpassant plusieurs méthodes de pointe de manière significative. Pour les athlètes et les entraîneurs, cela signifie un assistant automatisé capable de signaler des ondulations mal synchronisées, des atterrissages instables ou des lacunes dans la synchronisation d’équipe au moment où elles se produisent, tout en suivant la progression sur des compétences de difficulté croissante — un pas important vers un entraînement de cheerleading plus sûr, plus précis et guidé par les données.
Citation: Li, Q. Application of PoseConv3D algorithm in cheerleading training action recognition. Sci Rep 16, 12265 (2026). https://doi.org/10.1038/s41598-026-43019-4
Mots-clés: cheerleading, reconnaissance d’action, estimation de pose, analyse sportive, apprentissage profond