Clear Sky Science · sv
Tillämpning av PoseConv3D-algoritmen för igenkänning av rörelser i cheerleadingträning
Smartare coaching för en snabbfotad sport
Cheerleading är idag mycket mer än hejarramsor vid sidlinjen; det är en krävande akrobatisk lagsport där små misstag i timing eller hållning kan vara skillnaden mellan ett snyggt stunt och ett farligt fall. Ändå förlitar sig de flesta tränare fortfarande på blotta ögat och långsamma videogenomgångar. Denna artikel presenterar ett artificiellt intelligenssystem som kan granska cheerleadingrutiner bildruta för bildruta, förstå utövarnas kroppsställningar och automatiskt känna igen både vilken rörelse som utförs och hur svår den är — vilket öppnar dörren för säkrare, mer precis och mer individanpassad träning.
Varför cheerleading utgör en särskild utmaning
Många sporter och vardagliga aktiviteter har redan studerats med datorseende, men cheerleading pressar befintliga metoder till sina gränser. Utövare snurrar flera varv per sekund, kastas genom luften och bygger flerpersoonspyramider där kroppar överlappar och skymmer kameran. Rörelser som ser lika ut i rummet — som armvågor och höga sparkar — kan främst skilja sig i rytm, något standardalgoritmer i stort sett ignorerar. Som en följd misstar vanliga aktionsigenkänningssystem nyckelleden, tappar spår av individer i gruppstunts och förväxlar rörelser med liknande banor, vilket leder till låg noggrannhet och opålitlig återkoppling i verkliga träningslokaler.
Att förvandla video till rena digitala skelett
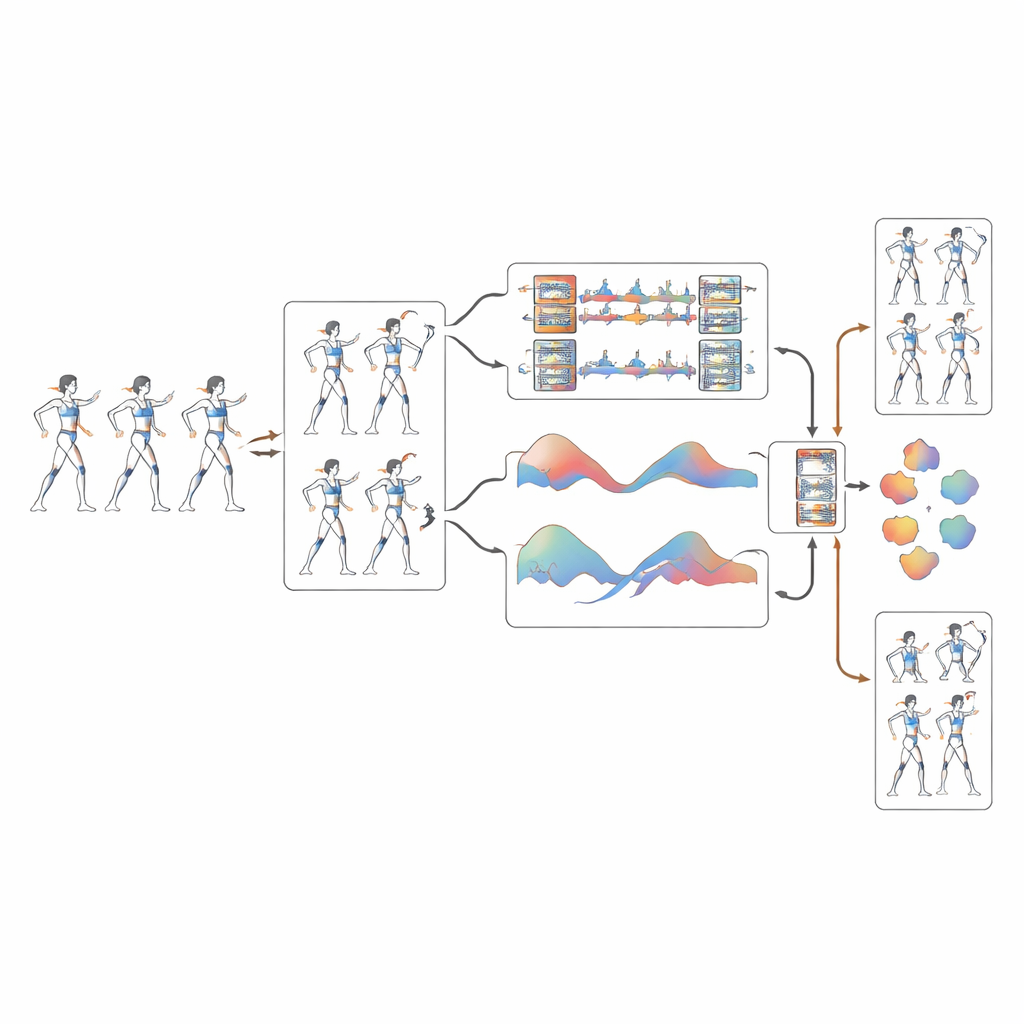
Det nya systemet bygger på ett pose‑baserat 3D‑konvolutionsnät kallat PoseConv3D, som inte arbetar med råa pixlar utan med förenklade “käppfigurer” — skelett som extraheras ur video. Den första nyheten är ett dynamiskt korrigeringssteg som rensar upp dessa skelett. När den underliggande pose‑detektorn är osäker på ett led — till exempel en handled som blir suddig under en snurr — förutspår systemet dess mest sannolika bana över tid med hjälp av släta kurvor som respekterar hur närliggande bildrutor rör sig. Detta minskar skakningar och drift i ledpositioner med mer än 40 %, vilket ger inlärningsalgoritmen en mycket klarare bild av hur varje utövares kropp verkligen rör sig under snabba rotationer och lufttransitioner.
Att se både små detaljer och stora lagmönster
När skeletten är rensade analyserar systemet rörelsen i flera skalor samtidigt. En bearbetningsgren fokuserar på fina detaljer som en snabb handledsryckning eller frånskjut med fotleden, medan en annan ser bredare mönster som ett bens svepande bågbanor eller den koordinerade uppresningen av flera utövare i en lyft. Genom att förena dessa vyer förstår modellen bättre hur små justeringar bidrar till stora, lagnivåformationer. Tester på en dedikerad datamängd från University of Central Florida för cheerleading — över 500 högupplösta tränings- och tävlingsklipp med noggrant märkta rörelser och svårighetsgrader — visar att detta flerskaliga angreppssätt markant förbättrar igenkänningen av komplexa, starkt koordinerade stunt.
Lära systemet att höra takten
En framträdande aspekt av arbetet är att algoritmen inte bara ser hur utövarna rör sig i rummet; den lär sig också när de rör sig. Forskarna beräknar hur snabbt varje led förflyttar sig från bildruta till bildruta och transformerar dessa förändringar till rytmmönster, ungefär som att omvandla musik till ett spektrum av slag. En särskild attention‑modul framhäver sedan ögonblick i rörelsessekvensen som matchar viktiga rytmiska signaturer. Detta gör att systemet pålitligt kan skilja åt handlingar som följer nästan identiska banor men utvecklas i olika tempo, och minskar förväxlingen mellan vågliknande rörelser och synkroniserade sparkar från ungefär en av sex försök till bara ett par av hundra.
Från igenkänning till en realtids träningspartner
I slutet av pipeline:n producerar systemet två utdata samtidigt: vilken typ av cheerleadingrörelse som utförs och en uppskattad svårighetspoäng som ligger i linje med tävlingsregler. Med en bearbetningstakt på nästan 90 bildrutor per sekund överträffar det lätt den hastighet som krävs för realtidsåterkoppling. Den totala noggrannheten når cirka 93 %, vilket slår flera toppmoderna metoder med god marginal. För utövare och tränare innebär detta en automatiserad assistent som kan flagga fel-tajmade vågor, ostabila landningar eller brister i lagets synkronisering när de händer, samtidigt som den spårar framsteg i allt svårare färdigheter — ett kraftfullt steg mot datadriven, säkrare och mer finjusterad cheerleadingträning.
Citering: Li, Q. Application of PoseConv3D algorithm in cheerleading training action recognition. Sci Rep 16, 12265 (2026). https://doi.org/10.1038/s41598-026-43019-4
Nyckelord: cheerleading, aktionsigenkänning, pose-estimering, sporteanalys, djupt lärande