Clear Sky Science · it
Applicazione dell'algoritmo PoseConv3D nel riconoscimento dei movimenti per l'allenamento di cheerleading
Coaching più intelligente per uno sport in rapido movimento
Oggi il cheerleading è molto più che entusiasmo da bordo campo; è uno sport di squadra acrobatico e impegnativo in cui piccoli errori di tempismo o postura possono fare la differenza tra una figura pulita e una caduta pericolosa. Eppure la maggior parte dell'allenamento si basa ancora sull'occhio nudo e su replay video rallentati. Questo articolo presenta un sistema di intelligenza artificiale in grado di analizzare le routine di cheerleading fotogramma per fotogramma, interpretare le posizioni del corpo degli atleti e riconoscere automaticamente sia quale movimento viene eseguito sia quanto è difficile, aprendo la strada ad allenamenti più sicuri, precisi e personalizzati.
Perché il cheerleading rappresenta una sfida particolare
Molti sport e attività quotidiane sono già stati studiati con la visione artificiale, ma il cheerleading spinge i metodi esistenti ai loro limiti. Gli atleti ruotano più volte al secondo, volteggiano in aria e costruiscono piramidi a più persone dove i corpi si sovrappongono e oscurano la vista della camera. Movimenti che sembrano simili nello spazio — come onde con le braccia e calci alti — possono differire principalmente nel ritmo, aspetto che gli algoritmi standard in gran parte ignorano. Di conseguenza, i comuni sistemi di riconoscimento delle azioni interpretano male posizioni chiave delle articolazioni, perdono il tracciamento degli individui nelle acrobazie di gruppo e confondono mosse che condividono traiettorie simili, portando a bassa accuratezza e feedback inaffidabili nelle palestre di allenamento reali.
Trasformare i video in scheletri digitali puliti
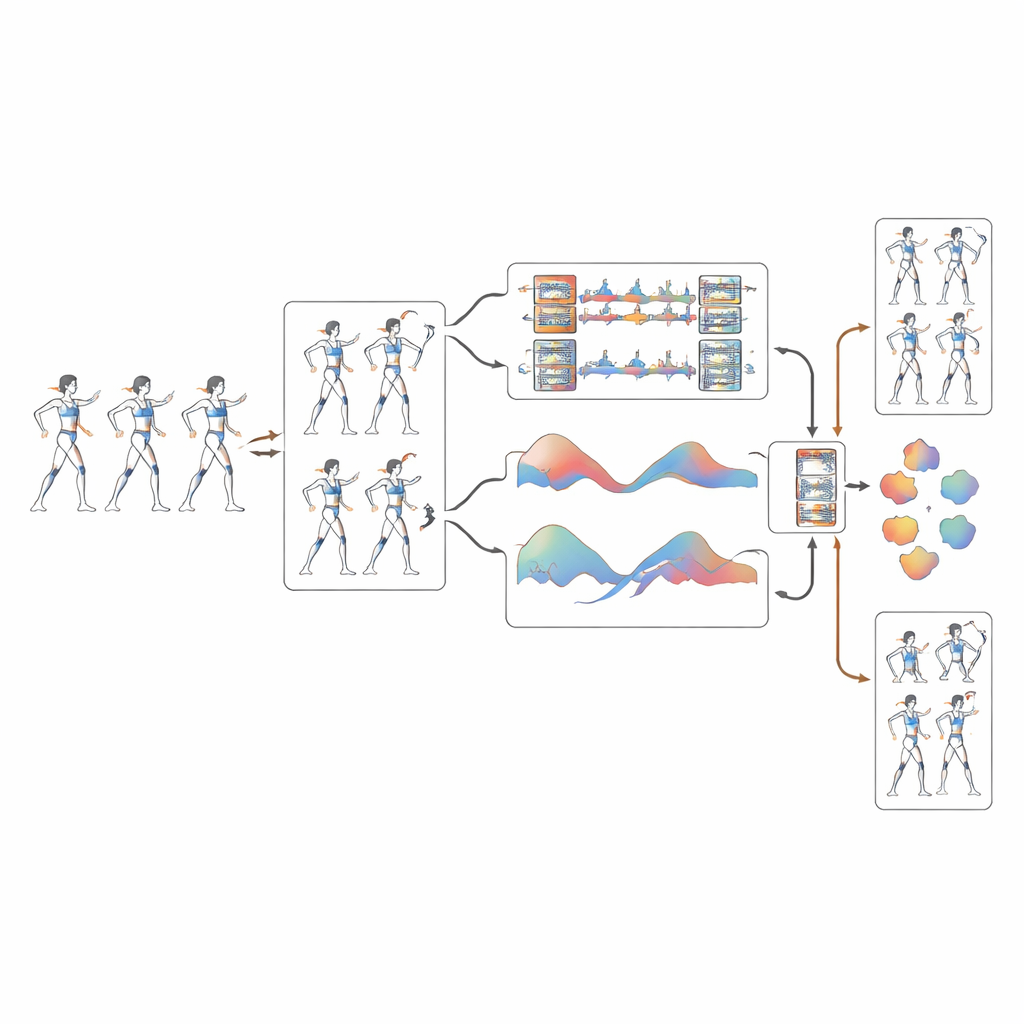
Il nuovo sistema si basa su una rete convoluzionale 3D guidata dalla posa chiamata PoseConv3D, che opera non sui pixel grezzi ma su scheletri semplificati a “battito” estratti dal video. La prima innovazione è una fase di correzione dinamica che ripulisce questi scheletri. Quando il rilevatore di pose sottostante è incerto su un’articolazione — per esempio un polso che sfoca durante una rotazione — il sistema ne predice il percorso più probabile nel tempo usando curve morbide che rispettano il movimento dei fotogrammi vicini. Questo riduce il tremolio e lo scorrimento delle posizioni delle articolazioni di oltre il 40%, offrendo all'algoritmo di apprendimento un quadro molto più chiaro di come il corpo di ciascun atleta si muove realmente durante rotazioni rapide e transizioni aeree.
Vedere sia i dettagli minuti che i grandi schemi di squadra
Una volta ripuliti gli scheletri, il sistema analizza il movimento su più scale contemporaneamente. Un ramo di elaborazione si concentra sui dettagli minuti come un rapido colpo di polso o una spinta del piede, mentre un altro osserva schemi più ampi come l'arco ampio di una gamba o la sollevazione coordinata di più atleti in un sollevamento. Fondondo queste prospettive, il modello comprende meglio come piccoli aggiustamenti contribuiscano a formazioni ampie a livello di squadra. I test su un dataset dedicato di cheerleading dell'University of Central Florida — oltre 500 clip di allenamento e competizione in alta definizione con mosse e livelli di difficoltà accuratamente etichettati — mostrano che questo approccio multi-scala migliora notevolmente il riconoscimento di acrobazie complesse e altamente coordinate.
Insegnare al sistema a sentire il ritmo
Una caratteristica distintiva del lavoro è che l'algoritmo non si limita a osservare come gli atleti si muovono nello spazio; impara anche quando si muovono. I ricercatori calcolano la velocità con cui ogni articolazione si sposta da un fotogramma all'altro e trasformano questi cambiamenti in pattern ritmici, molto simili a trasformare la musica in uno spettro di battiti. Un modulo di attenzione speciale evidenzia quindi i momenti nella sequenza di movimento che corrispondono a firme ritmiche chiave. Questo permette al sistema di distinguere in modo affidabile azioni che tracciano percorsi quasi identici ma si svolgono a tempi differenti, riducendo drasticamente la confusione tra movimenti ondulatori e calci sincronizzati da circa una volta ogni sei tentativi a poche volte ogni cento.
Dal riconoscimento al partner d'allenamento in tempo reale
Alla fine della pipeline, il sistema produce contemporaneamente due output: il tipo di movimento di cheerleading eseguito e un punteggio di difficoltà stimato in linea con le regole di gara. Funzionando a quasi 90 fotogrammi al secondo, supera comodamente la velocità richiesta per un feedback in tempo reale. L'accuratezza complessiva raggiunge circa il 93%, superando diversi metodi all'avanguardia con ampi margini. Per atleti e allenatori, ciò significa un assistente automatico in grado di segnalare onde fuori tempo, atterraggi instabili o lacune nella sincronizzazione di squadra mentre avvengono, oltre a monitorare i progressi su abilità sempre più difficili — offrendo un passo importante verso un allenamento del cheerleading più guidato dai dati, sicuro e finemente calibrato.
Citazione: Li, Q. Application of PoseConv3D algorithm in cheerleading training action recognition. Sci Rep 16, 12265 (2026). https://doi.org/10.1038/s41598-026-43019-4
Parole chiave: cheerleading, riconoscimento delle azioni, stima della posa, analisi dello sport, deep learning