Clear Sky Science · de
Anwendung des PoseConv3D-Algorithmus zur Erkennung von Bewegungen im Cheerleading-Training
Intelligenteres Coaching für eine rasant dynamische Sportart
Cheerleading ist heute weit mehr als bloße Seitenlinien‑Begeisterung; es ist ein anspruchsvoller akrobatischer Teamsport, bei dem kleine Fehler in Timing oder Körperhaltung den Unterschied zwischen einem sauberen Stunt und einem gefährlichen Sturz bedeuten können. Dennoch beruht das Coaching in vielen Fällen noch auf dem bloßen Auge und langsamen Video‑Wiederholungen. Diese Arbeit stellt ein System der künstlichen Intelligenz vor, das Cheerleading‑Routinen Bild für Bild analysieren, die Körperpositionen der Athleten erfassen und automatisch sowohl die ausgeführte Bewegung als auch deren Schwierigkeit erkennen kann – und damit den Weg zu sichererem, präziserem und individuelleren Training eröffnet.
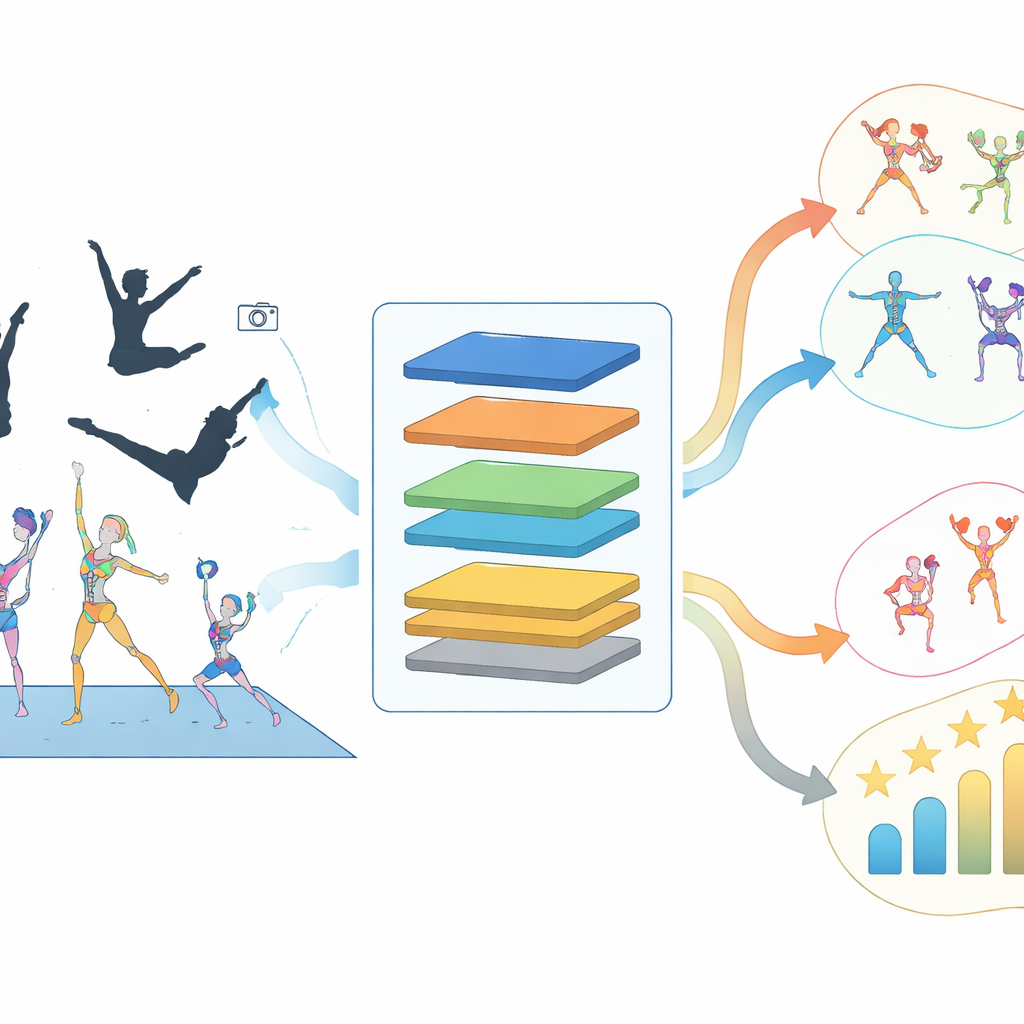
Warum Cheerleading eine besondere Herausforderung darstellt
Viele Sportarten und Alltagsaktivitäten wurden bereits mit Computer Vision untersucht, doch Cheerleading fordert bestehende Methoden bis an ihre Grenzen. Athleten drehen sich mehrfach pro Sekunde, rotieren durch die Luft und bauen mehrpersonige Pyramiden, bei denen Körper überlappen und die Kamerasicht blockiert wird. Bewegungen, die im Raum ähnlich aussehen – etwa Armwellen und hohe Tritte – unterscheiden sich häufig vor allem im Rhythmus, etwas, das Standardalgorithmen weitgehend ignorieren. In der Folge lesen gängige Action‑Recognition‑Systeme wichtige Gelenkpositionen falsch, verlieren Personen bei Gruppenstunts aus dem Blick und verwechseln Bewegungen mit ähnlichen Bahnen, was in Trainingshallen zu geringer Genauigkeit und unzuverlässigem Feedback führt.
Vom Video zu sauberen digitalen Skeletten
Das neue System baut auf einem pose‑basierten 3D‑Faltungsnetz namens PoseConv3D auf, das nicht auf Rohpixeln, sondern auf vereinfachten „Strichmännchen“‑Skeletten arbeitet, die aus Video extrahiert werden. Die erste Innovation ist ein dynamischer Korrekturschritt, der diese Skelette bereinigt. Wenn der zugrunde liegende Pose‑Detektor bei einem Gelenk unsicher ist – etwa ein während einer Drehung verwischendes Handgelenk – sagt das System dessen wahrscheinlichsten Verlauf über die Zeit voraus, indem es glatte Kurven nutzt, die die Bewegung benachbarter Frames berücksichtigen. Dadurch werden Zittern und Drift der Gelenkpositionen um mehr als 40 % reduziert, sodass der Lernalgorithmus ein deutlich klareres Bild davon erhält, wie sich der Körper eines Athleten bei schnellen Rotationen und Luftwechseln tatsächlich bewegt.
Kleine Details und große Teammuster gleichzeitig sehen
Sobald die Skelette bereinigt sind, analysiert das System die Bewegung gleichzeitig auf mehreren Skalen. Ein Verarbeitungszweig konzentriert sich auf feine Details wie einen schnellen Handgelenkschwung oder das Abstoßen mit dem Fußknöchel, während ein anderer breitere Muster betrachtet, etwa die geschwungene Bahn eines Beins oder das koordinierte Aufrichten mehrerer Athleten bei einem Lift. Durch das Verschmelzen dieser Perspektiven versteht das Modell besser, wie kleine Anpassungen zu großen, teambezogenen Formationen beitragen. Tests an einem speziell erstellten Cheerleading‑Datensatz der University of Central Florida – über 500 hochauflösende Trainings‑ und Wettkampfclips mit sorgfältig beschrifteten Bewegungen und Schwierigkeitsgraden – zeigen, dass dieser Multi‑Scale‑Ansatz die Erkennung komplexer, hochgradig koordinierter Stunts deutlich verbessert.
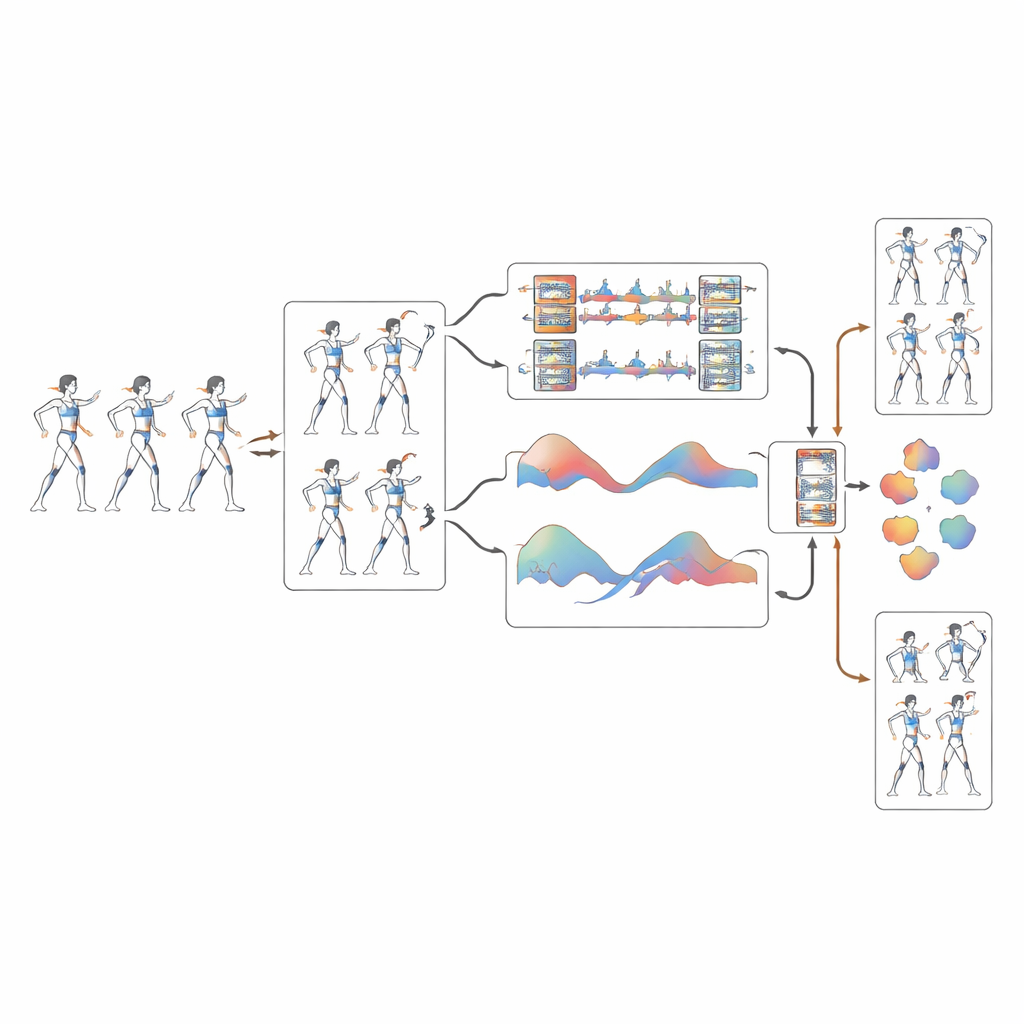
Dem System das Rhythmusgefühl beibringen
Ein hervorstechendes Merkmal der Arbeit ist, dass der Algorithmus nicht nur beobachtet, wie sich Athleten im Raum bewegen; er lernt auch, wann sie sich bewegen. Die Forschenden berechnen, wie schnell sich jedes Gelenk von Frame zu Frame bewegt, und wandeln diese Veränderungen in Rhythmus‑Muster um, ähnlich wie man Musik in ein Beat‑Spektrum überführt. Ein spezielles Aufmerksamkeitsmodul hebt dann Momentaufnahmen in der Bewegungssequenz hervor, die mit charakteristischen rhythmischen Signaturen übereinstimmen. Dadurch kann das System zuverlässig zwischen Aktionen unterscheiden, die nahezu identische Bahnen beschreiben, sich aber in unterschiedlichem Tempo entfalten, und reduziert die Verwechslungsrate zwischen wellenartigen Bewegungen und synchronisierten Tritten von etwa einem von sechs Fällen auf nur wenige von hundert.
Von der Erkennung zum Echtzeit‑Trainingspartner
Am Ende der Pipeline liefert das System zwei Ausgaben gleichzeitig: die Art des ausgeführten Cheerleading‑Moves und eine geschätzte Schwierigkeitspunktzahl, die mit Wettkampfregeln übereinstimmt. Mit einer Verarbeitungsgeschwindigkeit von nahezu 90 Frames pro Sekunde übertrifft es bequem die Anforderungen für Echtzeit‑Feedback. Die Gesamtgenauigkeit liegt bei etwa 93 % und übertrifft mehrere aktuelle Spitzenmethoden deutlich. Für Athleten und Trainer bedeutet das einen automatisierten Assistenten, der fehlgetimte Wellen, instabile Landungen oder Lücken in der Team‑Synchronisation sofort markieren kann und zugleich den Fortschritt bei zunehmend schwierigen Fähigkeiten verfolgt – ein kräftiger Schritt hin zu datengestütztem, sichererem und präziser abgestimmtem Cheerleading‑Training.
Zitation: Li, Q. Application of PoseConv3D algorithm in cheerleading training action recognition. Sci Rep 16, 12265 (2026). https://doi.org/10.1038/s41598-026-43019-4
Schlüsselwörter: Cheerleading, Bewegungserkennung, Pose-Schätzung, Sportanalytik, Deep Learning