Clear Sky Science · zh
用于医学药物评论中自动论证与注释抽取的 QRNN-GRU 框架
为什么在线药物故事很重要
每天都有成千上万的人发布关于他们所服用药物的个人经历——药效如何、出现了哪些副作用、生活是否真的有所改善。在这片嘈杂的评论流中隐藏着对医生、患者和监管者来说极具价值的洞见。问题在于这些评论通常杂乱、情绪化,并且充斥着专业医学术语。本文提出了一种新的人工智能(AI)系统,旨在阅读此类药物评论并自动提取有关益处与危害的结构化论证,将分散的轶事转化为有组织的证据。
从零散意见到清晰论证
人们在书写药物体验时,往往在不自觉中提出论点。一位家长可能声称某种药物改善了孩子的病情,并给出具体理由或例子作为支持。论证挖掘是尝试在文本中检测这些构件——主张、支持理由(称为前提)以及无关句子的研究领域。在医学评论中,这比在学校作文或正式辩论中更难,因为语言更口语化、句子常不完整,且症状或副作用的描述方式多种多样。作者专注于这种艰难的医学场景,在这里更好的工具可以更可靠地总结药物的真实世界使用体验。
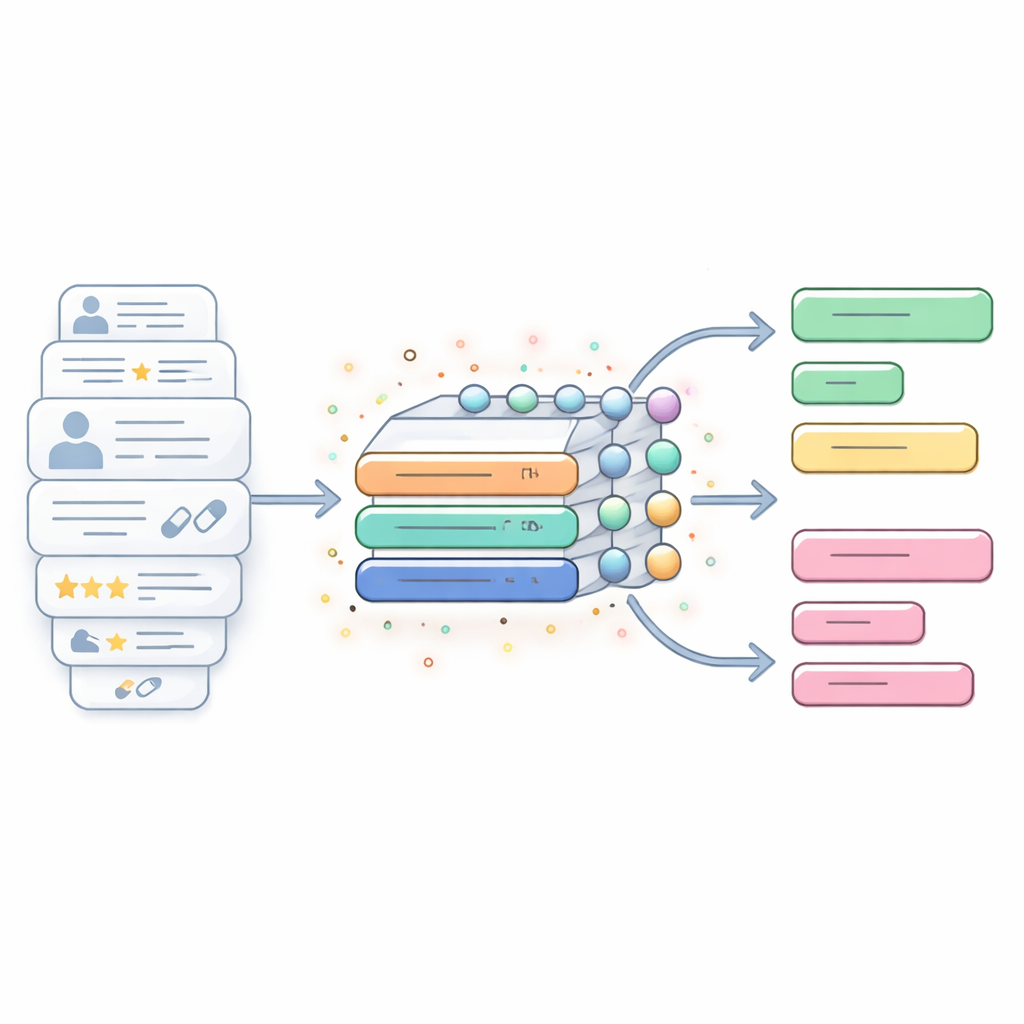
为长且噪声多的文本打造的混合 AI 引擎
研究引入了一种混合 AI 模型,将两种序列处理技术结合起来:准循环神经网络(QRNN)和门控循环单元(GRU)。简单来说,QRNN 部分像一个快速扫描器,寻找文本中的短程局部模式——例如表扬、抱怨或副作用的短语——而 GRU 部分像一个细心的倾听者,跟踪这些模式在评论较长段落中的发展。二者协同旨在平衡速度与深度:该系统能够处理冗长、混乱的药物故事,而不会变得过慢或在跨句的重要上下文上丢失信息。
让数字“萤火虫”为系统调参
设计这样的 AI 模型涉及许多选择:层数、学习速度以及为防止在数据特性上过拟合而采取的正则化强度。作者没有手工微调这些设定,而是采用了一种受萤火虫行为启发的优化方法。在该方法中,许多候选配置会根据其表现“闪烁”,表现更好的配置会吸引其他配置,逐步将搜索引导到高性能的组合。基于萤火虫的优化器对 QRNN–GRU 系统进行了微调,使其能在大量用户评论上高效学习,同时在训练过程中保持稳定性。
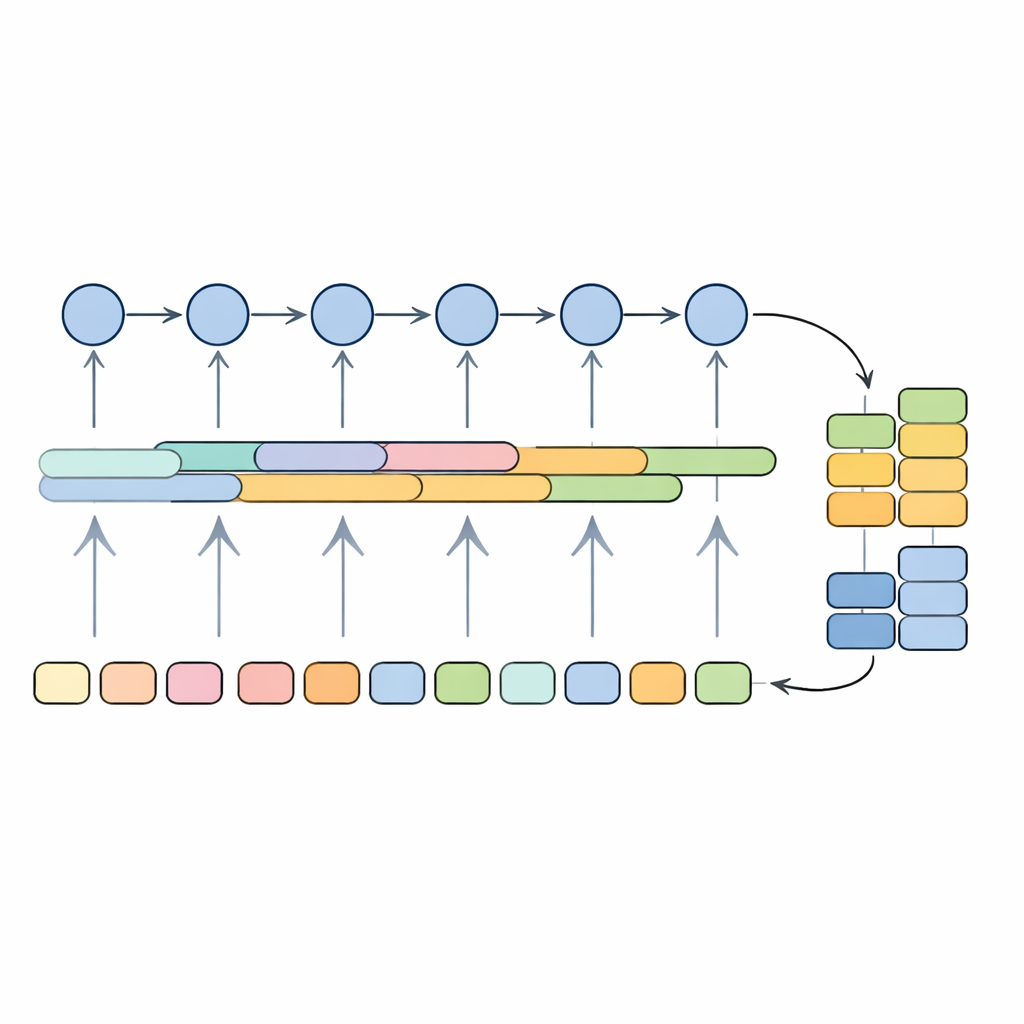
在医学文本上检验模型
研究人员在一个大型公开药物评论数据集上训练并评估了他们的系统,该数据集通过半自动注释过程将句子标注为主张、前提或非论证句。混合模型在准确性和覆盖率的平衡指标(F1 分数)上达到了约 89%,总体准确率约为 91%,优于支持向量机、朴素贝叶斯、随机森林以及单一深度学习模型(如纯卷积网络、LSTM 或单独使用的 GRU)等更传统的方法。与一种类似 BERT 的广泛使用的变换器模型相比,它在预测时也消耗显著更少的计算资源和内存。为了测试该方法在药物评论以外的泛化能力,作者还将其应用于一个医学研究摘要的基准数据集,发现其性能仍与为该任务设计的最先进系统具有竞争力。
对患者与医学的意义
通俗地说,这项工作表明可以自动将日常药物评论转化为关于人们所主张内容及其理由的结构化图谱。通过结合快速的局部扫描器(QRNN)、具上下文意识的倾听者(GRU)以及高效的调优策略(萤火虫优化),该系统能够筛选大量混乱的医学文本,并可靠地区分有关疗效和副作用的有意义论证与背景闲聊。这最终可能帮助患者看到他人经验的更清晰摘要,帮助临床医生发现潜在的利害模式,并支持研究人员追踪药物在受控临床试验之外的表现。作者指出,他们的模型目前仍主要关注句子层面的模式且仅限于医学文本,但他们认为这是朝着能够解读人们健康故事的更丰富、更高效工具迈出的有希望的一步。
引用: Altameem, E., Alnuem, M. & Albassam, S. QRNN-GRU framework for automatic argument and annotation extraction in medical drug reviews. Sci Rep 16, 13581 (2026). https://doi.org/10.1038/s41598-026-41379-5
关键词: 论证挖掘, 药物评论, 医学文本分析, 神经网络, 患者体验