Clear Sky Science · nl
QRNN-GRU-kader voor automatische extractie van argumenten en annotaties in medische medicijnbeoordelingen
Waarom online medicijnverhalen ertoe doen
Elke dag plaatsen duizenden mensen persoonlijke verhalen over de medicijnen die ze gebruiken—hoe goed ze werken, welke bijwerkingen optreden en of het leven er echt beter van wordt. Verborgen in deze lawaaierige stroom reacties ligt een goudmijn aan inzicht voor artsen, patiënten en toezichthouders. De uitdaging is dat deze recensies rommelig, emotioneel en vol gespecialiseerde medische termen zijn. Dit artikel presenteert een nieuw systeem voor kunstmatige intelligentie (AI) dat zulke medicijnbeoordelingen kan lezen en automatisch goed gestructureerde argumenten over voordelen en nadelen kan herkennen, waardoor verspreide anekdotes worden omgezet in georganiseerde bewijzen.
Van verspreide meningen naar heldere argumenten
Wanneer mensen over medicijnen schrijven, formuleren ze vaak argumenten zonder zich daar bewust van te zijn. Een ouder kan bijvoorbeeld stellen dat een medicijn de aandoening van hun kind heeft verbeterd en vervolgens specifieke redenen of voorbeelden geven als onderbouwing. Argument mining is het onderzoeksveld dat probeert deze bouwstenen—stelligen, ondersteunende redenen (premissen genoemd) en irrelevante zinnen—in tekst te detecteren. In medische recensies is dit lastiger dan in schoolopstellen of formele debatten omdat de taal informeel is, zinnen onvolledig zijn en symptomen of bijwerkingen op veel verschillende manieren worden beschreven. De auteurs richten zich specifiek op deze moeilijke medische context, waar betere hulpmiddelen kunnen helpen de ervaringen uit de echte wereld met geneesmiddelen betrouwbaarder samen te vatten.
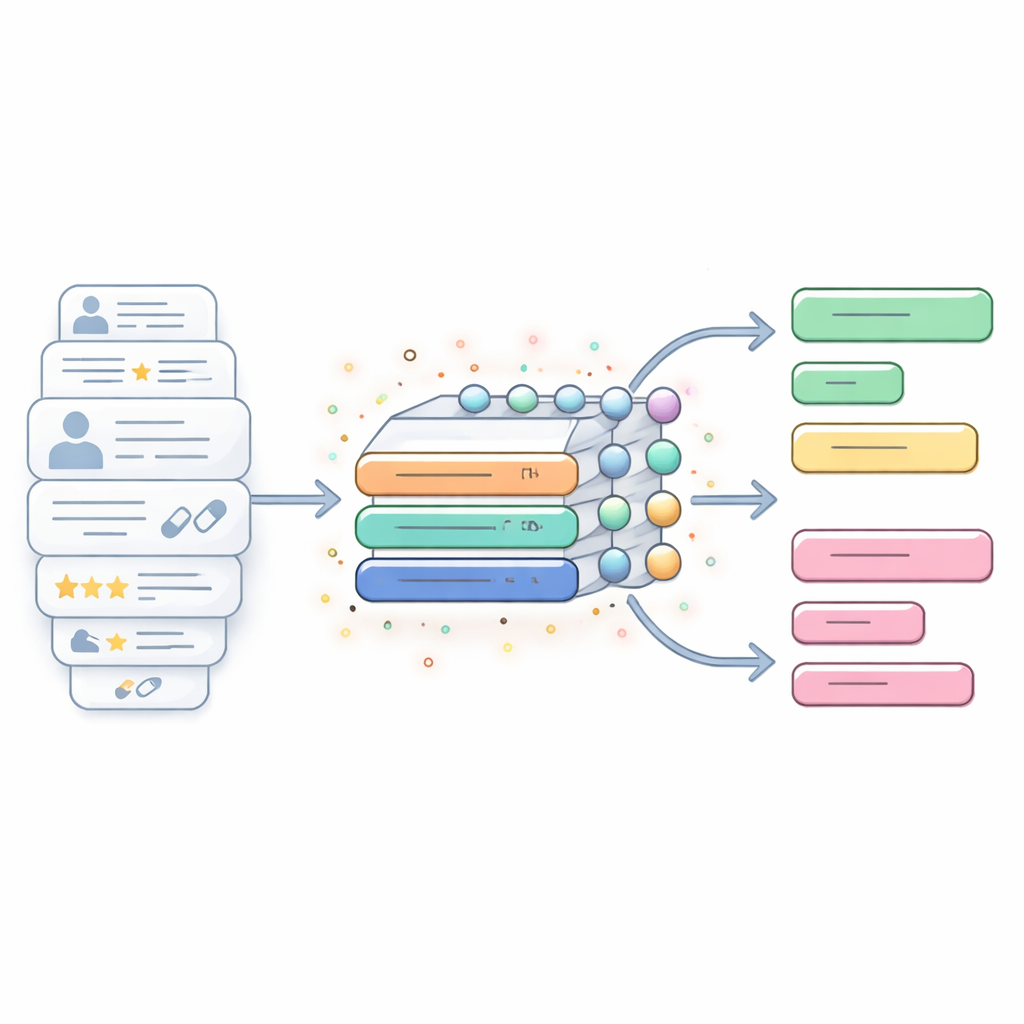
Een hybride AI-motor gebouwd voor lange en rumoerige tekst
De studie introduceert een hybride AI-model dat twee volgordeverwerkende technieken combineert: quasi-recurrente neurale netwerken (QRNN's) en gated recurrent units (GRU's). In gewone woorden fungeert het QRNN-gedeelte als een snelle scanner die zoekt naar korte lokale patronen in tekst—zinnen of woordgroepen die lof, klachten of bijwerkingen aangeven—terwijl het GRU-gedeelte werkt als een zorgvuldige luisteraar die bijhoudt hoe deze patronen zich ontvouwen over langere delen van een beoordeling. Samen streven ze naar een balans tussen snelheid en diepgang: het systeem kan lange, rommelige medicijnverhalen verwerken zonder te traag te worden of belangrijke context die zich over meerdere zinnen uitbreidt, te verliezen.
Het systeem afstemmen met digitale "vuurvliegjes"
Het ontwerpen van zo’n AI-model omvat veel keuzes: hoeveel lagen het moet hebben, hoe snel het moet leren en hoe sterk het geregulariseerd moet worden om overfitting aan eigenaardigheden in de data te voorkomen. In plaats van deze instellingen met de hand af te stemmen, gebruiken de auteurs een optimalisatiemethode geïnspireerd op het gedrag van vuurvliegjes. Bij deze benadering "knipperen" veel kandidaatconfiguraties afhankelijk van hoe goed ze presteren, en trekken betere configuraties anderen aan, waardoor de zoekrichting geleidelijk naar een goed presterende combinatie wordt gestuurd. Deze vuurvlieg-gebaseerde optimizer stemt het QRNN–GRU-systeem fijn af zodat het efficiënt leert van grote verzamelingen gebruikersrecensies en tegelijk stabiel blijft tijdens het trainen.
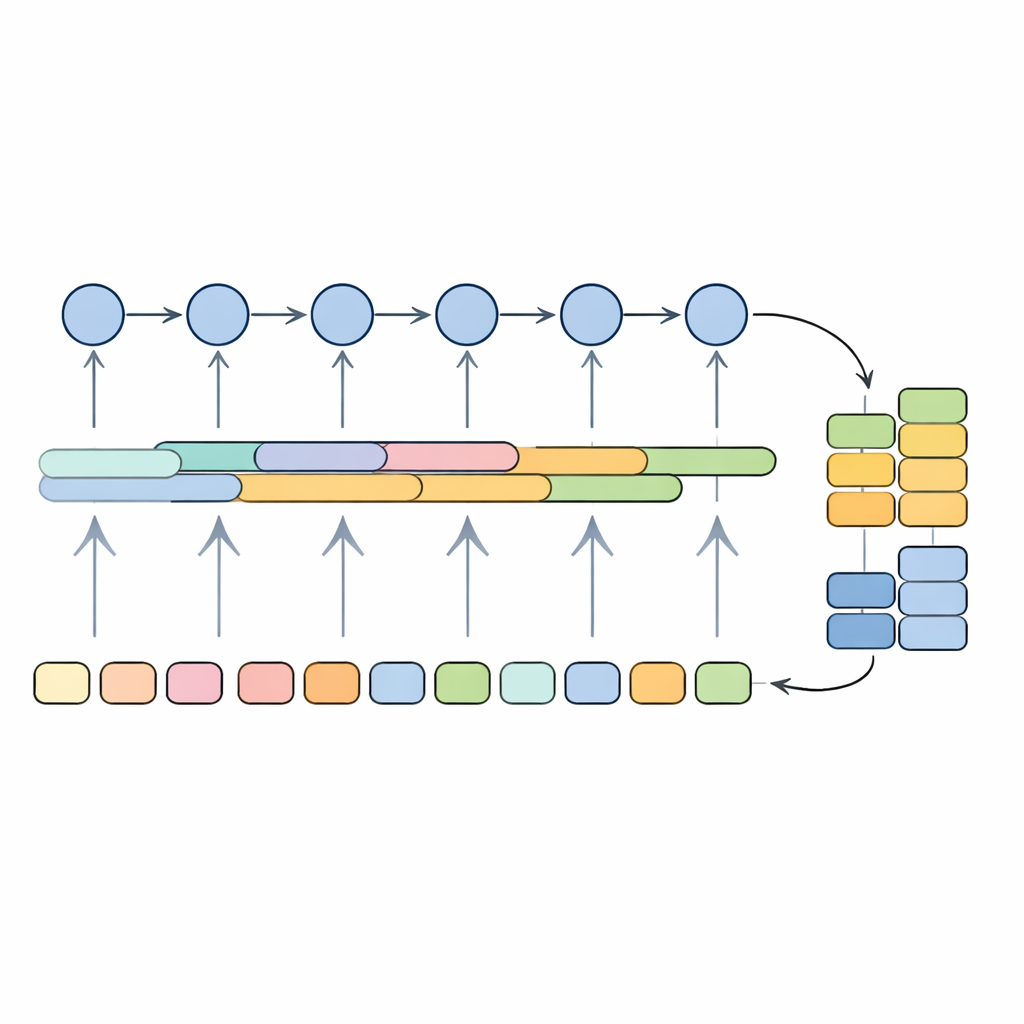
Het model testen op medische teksten
De onderzoekers trainden en evalueerden hun systeem op een grote openbare dataset met medicijnbeoordelingen, waarbij zinnen semi-automatisch waren gelabeld als stelligen, premissen of niet-argumenten. Het hybride model behaalde ongeveer 89 procent op een gebalanceerde maat voor nauwkeurigheid en dekking (de F1-score) en rond de 91 procent algehele nauwkeurigheid, waarmee het beter presteerde dan meer traditionele methoden zoals support vector machines, naïeve Bayes, random forests en afzonderlijke diepgaande modellen zoals gewone convolutionele netwerken, LSTM's of enkelvoudige GRU's. Het vergeleek ook gunstig met een veelgebruikt transformermodel vergelijkbaar met BERT, terwijl het aanzienlijk minder rekencapaciteit en geheugen vereist tijdens voorspellingen. Om te testen of de aanpak generaliseert buiten medicijnbeoordelingen, pasten de auteurs het ook toe op een benchmark van medische onderzoeksabstracts en ontdekten dat het concurrerend bleef met state-of-the-art systemen die voor die taak zijn ontworpen.
Wat dit betekent voor patiënten en de geneeskunde
In eenvoudige bewoordingen laat dit werk zien dat het mogelijk is om alledaagse medicijnrecensies automatisch om te zetten in gestructureerde overzichten van wat mensen beweren en waarom ze die beweringen doen. Door een snelle lokale scanner (QRNN), een contextbewuste luisteraar (GRU) en een efficiënte afstemmingsstrategie (vuurvliegoptimalisatie) te combineren, kan het systeem grote hoeveelheden rommelige medische tekst doorzoeken en op betrouwbare wijze betekenisvolle argumenten over effectiviteit en bijwerkingen scheiden van achtergrondrumoer. Dit kan patiënten uiteindelijk helpen om duidelijkere samenvattingen van andermans ervaringen te zien, clinici ondersteunen bij het signaleren van opkomende patronen van voordeel of schade en onderzoekers helpen die volgen hoe geneesmiddelen presteren buiten gecontroleerde klinische onderzoeken. De auteurs merken op dat hun model zich nog vooral richt op zinsniveaupatronen en op medische teksten, maar zien het als een veelbelovende stap naar rijkere, efficiëntere hulpmiddelen die zin geven aan de verhalen die mensen over hun gezondheid vertellen.
Bronvermelding: Altameem, E., Alnuem, M. & Albassam, S. QRNN-GRU framework for automatic argument and annotation extraction in medical drug reviews. Sci Rep 16, 13581 (2026). https://doi.org/10.1038/s41598-026-41379-5
Trefwoorden: argument mining, medicijnbeoordelingen, analyse van medische tekst, neurale netwerken, patiëntervaring