Clear Sky Science · fr
Cadre QRNN-GRU pour l’extraction automatique d’arguments et d’annotations dans les avis médicaux sur les médicaments
Pourquoi les témoignages en ligne sur les médicaments comptent
Chaque jour, des milliers de personnes publient des récits personnels sur les médicaments qu’elles prennent — leur efficacité, les effets secondaires observés et si la vie s’améliore réellement. Cachée dans ce flux bruyant de commentaires se trouve une mine d’informations précieuses pour les médecins, les patients et les autorités sanitaires. Le problème est que ces avis sont désordonnés, émotionnels et riches en termes médicaux spécialisés. Cet article présente un nouveau système d’intelligence artificielle (IA) conçu pour lire ces avis et extraire automatiquement des arguments bien structurés sur les bénéfices et les préjudices, transformant des anecdotes éparses en preuves organisées.
D’opinions dispersées à des arguments clairs
Lorsque les gens écrivent au sujet des médicaments, ils formulent souvent des arguments sans en avoir conscience. Un parent peut affirmer qu’un médicament a aidé l’état de son enfant puis fournir des raisons ou des exemples précis en soutien. L’extraction d’arguments est le domaine de recherche qui tente de détecter ces éléments — les affirmations, les raisons de soutien (appelées prémisses) et les phrases non pertinentes — dans un texte. Dans les avis médicaux, c’est plus difficile que dans des rédactions scolaires ou des débats formels parce que le langage est informel, les phrases sont incomplètes et les symptômes ou effets indésirables sont décrits de multiples façons. Les auteurs se concentrent spécifiquement sur ce contexte médical exigeant, où de meilleurs outils pourraient permettre de résumer plus fiablement les expériences réelles avec les médicaments.
Un moteur IA hybride conçu pour les textes longs et bruyants
L’étude introduit un modèle IA hybride qui combine deux techniques de traitement de séquences : les réseaux neuronaux quasi-récurrents (QRNN) et les unités récurrentes à portes (GRU). En termes simples, la partie QRNN agit comme un scanner rapide qui repère de courts motifs locaux dans le texte — des expressions signalant des louanges, des plaintes ou des effets secondaires — tandis que la partie GRU fait office d’auditeur attentif qui suit la manière dont ces motifs se déploient sur de longues portions d’un avis. Ensemble, ils cherchent à équilibrer vitesse et profondeur : le système peut gérer des récits de médicaments longs et désordonnés sans devenir trop lent ni perdre le contexte important étalé sur plusieurs phrases.
Laisser des « luciole numériques » régler le système
Concevoir un tel modèle AI implique de nombreux choix : combien de couches, à quelle vitesse il doit apprendre et quelle intensité de régularisation pour éviter le surapprentissage sur des particularités des données. Plutôt que d’ajuster ces paramètres manuellement, les auteurs utilisent une méthode d’optimisation inspirée du comportement des lucioles. Dans cette approche, de nombreuses configurations candidates « clignotent » selon leur performance, et les meilleures attirent les autres, orientant progressivement la recherche vers une combinaison performante. Cet optimiseur basé sur les lucioles affine le système QRNN–GRU pour qu’il apprenne efficacement à partir de grandes collections d’avis d’utilisateurs tout en restant stable durant l’entraînement.
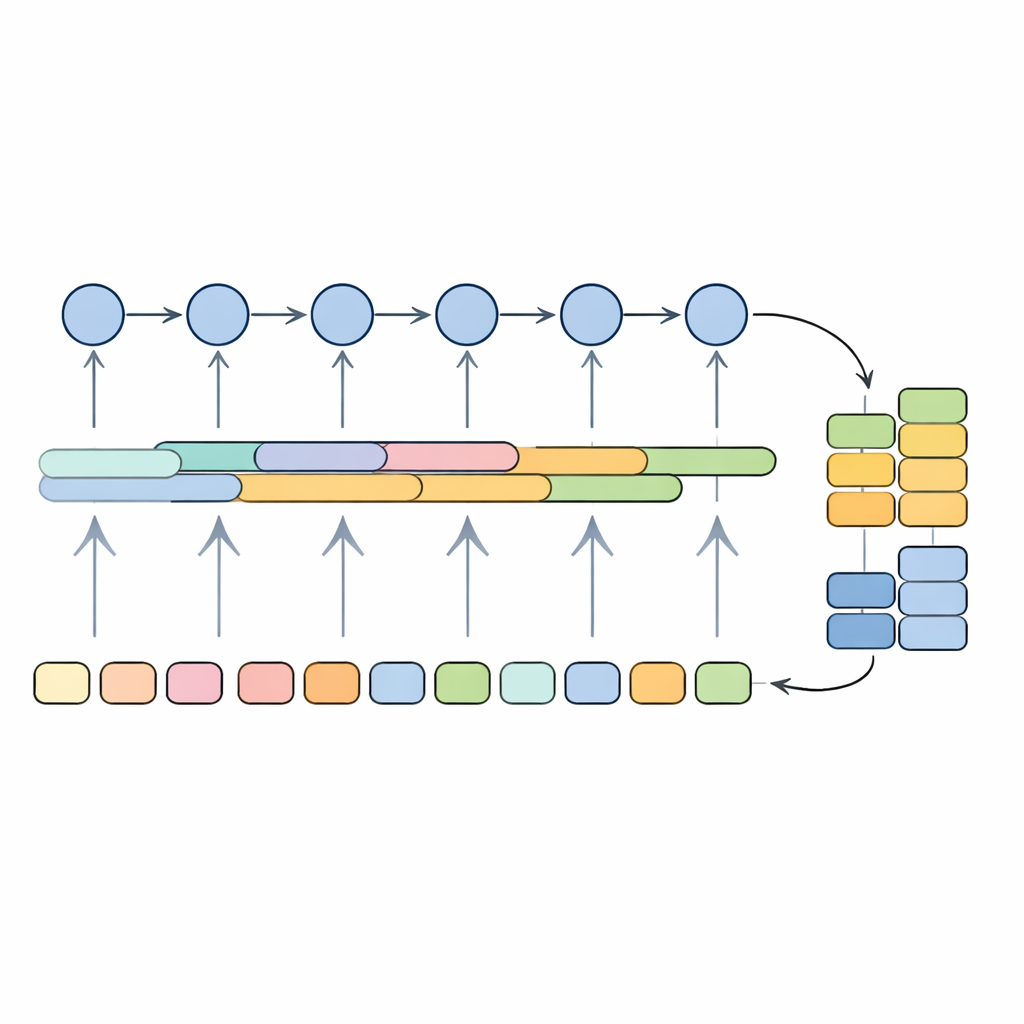
Mettre le modèle à l’épreuve sur des textes médicaux
Les chercheurs ont entraîné et évalué leur système sur un large jeu de données public d’avis sur les médicaments, où les phrases avaient été annotées comme affirmations, prémisses ou non-arguments via un processus d’annotation semi-automatique. Le modèle hybride a atteint environ 89 % sur une mesure équilibrée de précision et de rappel (score F1) et environ 91 % de précision globale, surpassant des méthodes plus traditionnelles telles que les machines à vecteurs de support, le naïf bayésien, les forêts aléatoires et des modèles profonds isolés comme des réseaux convolutifs simples, des LSTM ou des GRU utilisés seuls. Il s’est également comparé favorablement à un modèle transformeur largement utilisé similaire à BERT, tout en nécessitant sensiblement moins de puissance de calcul et de mémoire au moment de la prédiction. Pour vérifier la généralisation au-delà des avis sur les médicaments, les auteurs l’ont aussi appliqué à une référence d’abstracts de recherche médicale et ont constaté qu’il restait compétitif face aux systèmes de pointe conçus pour cette tâche.
Ce que cela signifie pour les patients et la médecine
Concrètement, ce travail montre qu’il est possible de transformer automatiquement des avis quotidiens sur les médicaments en cartes structurées de ce que les gens affirment et pourquoi ils croient ces affirmations. En combinant un scanner local rapide (QRNN), un auditeur conscient du contexte (GRU) et une stratégie d’ajustement efficace (optimisation par lucioles), le système peut filtrer de grands volumes de textes médicaux désordonnés et séparer de manière fiable les arguments pertinents sur l’efficacité et les effets secondaires du bruit de fond. Cela pourrait aider à terme les patients à obtenir des résumés plus clairs des expériences d’autrui, aider les cliniciens à repérer des tendances émergentes de bénéfice ou de préjudice et soutenir les chercheurs qui suivent la performance des médicaments en dehors des essais cliniques contrôlés. Les auteurs notent que leur modèle se concentre encore principalement sur des motifs au niveau de la phrase et sur des textes médicaux uniquement, mais ils y voient une étape prometteuse vers des outils plus riches et plus efficaces pour donner sens aux récits de santé des personnes.
Citation: Altameem, E., Alnuem, M. & Albassam, S. QRNN-GRU framework for automatic argument and annotation extraction in medical drug reviews. Sci Rep 16, 13581 (2026). https://doi.org/10.1038/s41598-026-41379-5
Mots-clés: extraction d’arguments, avis sur les médicaments, analyse de textes médicaux, réseaux neuronaux, expérience des patients