Clear Sky Science · pt
Estrutura QRNN-GRU para extração automática de argumentos e anotações em avaliações de medicamentos
Por que histórias online sobre medicamentos importam
Todos os dias, milhares de pessoas publicam relatos pessoais sobre os remédios que usam — quão bem funcionam, quais efeitos colaterais aparecem e se a vida realmente melhora. Oculto dentro desse fluxo barulhento de comentários há um manancial de informações valiosas para médicos, pacientes e reguladores. O desafio é que essas avaliações são desordenadas, emotivas e cheias de termos médicos específicos. Este artigo apresenta um novo sistema de inteligência artificial (IA) projetado para ler essas avaliações de medicamentos e extrair automaticamente argumentos bem estruturados sobre benefícios e malefícios, transformando anedotas dispersas em evidências organizadas.
De opiniões dispersas a argumentos claros
Quando as pessoas escrevem sobre medicamentos, frequentemente fazem argumentos sem perceber. Um pai pode afirmar que um remédio ajudou a condição do filho e então fornecer razões ou exemplos específicos como suporte. Mineração de argumentos é o campo de pesquisa que tenta detectar esses blocos de construção — reivindicações, razões de apoio (chamadas premissas) e sentenças irrelevantes — dentro do texto. Em avaliações médicas, isso é mais difícil do que em redações escolares ou debates formais porque a linguagem é informal, frases ficam incompletas e sintomas ou efeitos colaterais são descritos de várias maneiras. Os autores focam especificamente nesse cenário médico desafiador, onde melhores ferramentas poderiam ajudar a resumir experiências do mundo real com medicamentos de forma mais confiável.
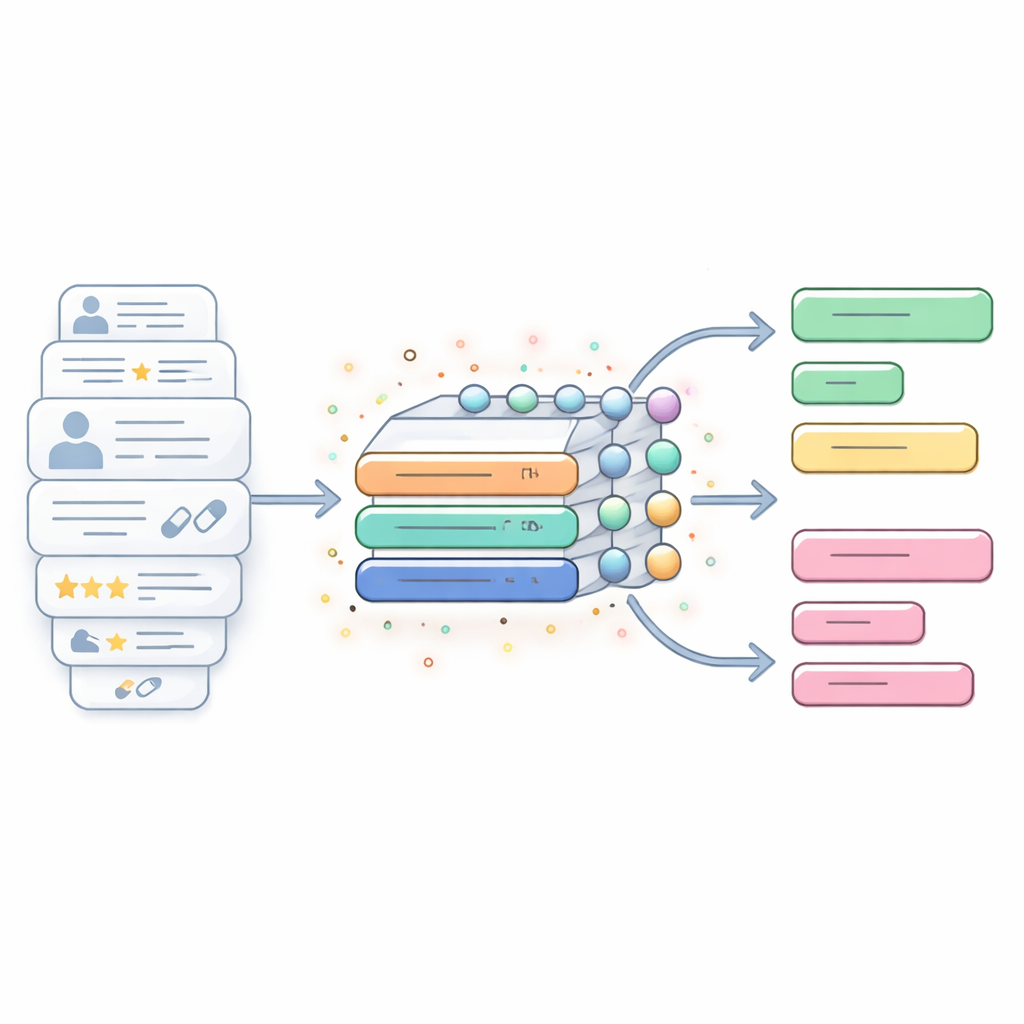
Um motor híbrido de IA feito para textos longos e ruidosos
O estudo introduz um modelo híbrido de IA que combina duas técnicas de processamento de sequências: redes neurais quase recorrentes (QRNNs) e unidades recorrentes com portões (GRUs). Em termos simples, a parte QRNN age como um scanner rápido que busca padrões locais curtos no texto — frases que sinalizam elogios, reclamações ou efeitos colaterais — enquanto a parte GRU funciona como um ouvinte atento que acompanha como esses padrões se desenrolam ao longo de trechos mais longos de uma avaliação. Juntas, elas buscam equilibrar velocidade e profundidade: o sistema pode lidar com relatos longos e bagunçados sem ficar lento demais ou perder o contexto importante espalhado por várias sentenças.
Deixando "vaga-lumes" digitais ajustarem o sistema
Projetar esse modelo de IA envolve muitas decisões: quantas camadas ele deve ter, quão rápido deve aprender e quão fortemente deve ser regularizado para evitar sobreajuste a peculiaridades dos dados. Em vez de ajustar manualmente essas configurações, os autores usam um método de otimização inspirado no comportamento de vaga-lumes. Nessa abordagem, muitas configurações candidatas "piscaram" de acordo com seu desempenho, e as melhores atraem as demais, direcionando gradualmente a busca para uma combinação de alto desempenho. Esse otimizador baseado em vaga-lumes ajusta finamente o sistema QRNN–GRU para que ele aprenda de forma eficiente a partir de grandes coleções de avaliações de usuários, mantendo estabilidade durante o treinamento.
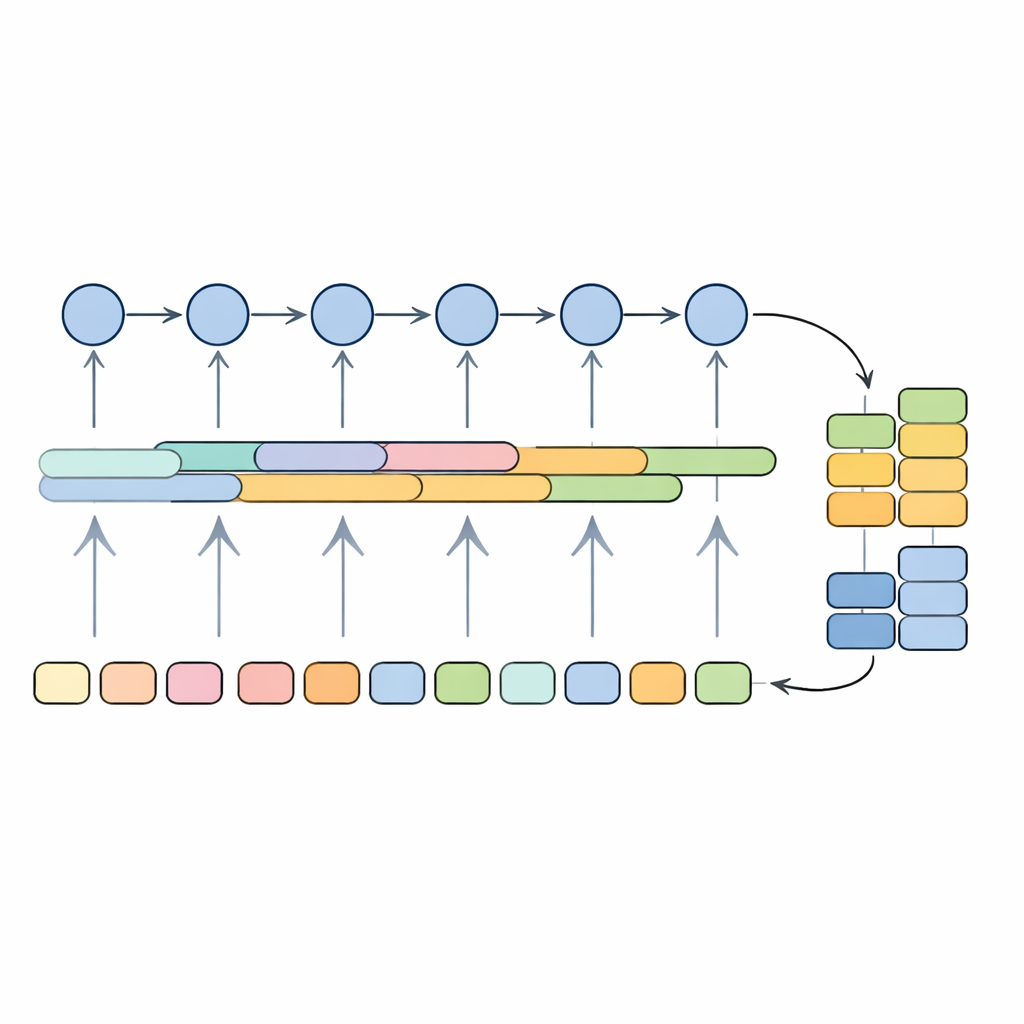
Colocando o modelo à prova em textos médicos
Os pesquisadores treinaram e avaliaram o sistema em um grande conjunto público de avaliações de medicamentos, onde as sentenças foram rotuladas como reivindicações, premissas ou não-argumentos usando um processo de anotação semiautomático. O modelo híbrido alcançou cerca de 89% em uma medida balanceada de precisão e cobertura (pontuação F1) e cerca de 91% de acurácia geral, superando métodos mais tradicionais como máquinas de vetores de suporte, naïve Bayes, florestas aleatórias e modelos profundos isolados como redes convolucionais simples, LSTMs ou GRUs usados sozinhos. Também se comparou favoravelmente a um modelo transformer amplamente usado, similar ao BERT, exigindo substancialmente menos potência computacional e memória no momento da predição. Para testar se a abordagem generaliza além das avaliações de medicamentos, os autores também a aplicaram a um conjunto de referência de resumos de pesquisas médicas e verificaram que ela permaneceu competitiva com sistemas de ponta projetados para essa tarefa.
O que isso significa para pacientes e medicina
Em termos práticos, este trabalho mostra que é possível transformar automaticamente avaliações cotidianas de medicamentos em mapas estruturados do que as pessoas afirmam e por que acreditam nessas afirmações. Ao combinar um scanner local rápido (QRNN), um ouvinte sensível ao contexto (GRU) e uma estratégia de ajuste eficiente (otimização por vaga-lumes), o sistema consegue vasculhar grandes volumes de texto médico confuso e separar de forma confiável argumentos significativos sobre eficácia e efeitos colaterais do ruído de fundo. Isso pode, eventualmente, ajudar pacientes a ver resumos mais claros das experiências de outros, auxiliar clínicos a identificar padrões emergentes de benefício ou dano e apoiar pesquisadores que acompanham o desempenho de medicamentos fora de ensaios clínicos controlados. Os autores observam que seu modelo ainda se concentra principalmente em padrões ao nível da sentença e apenas em textos médicos, mas o veem como um passo promissor rumo a ferramentas mais ricas e eficientes que façam sentido das histórias que as pessoas contam sobre sua saúde.
Citação: Altameem, E., Alnuem, M. & Albassam, S. QRNN-GRU framework for automatic argument and annotation extraction in medical drug reviews. Sci Rep 16, 13581 (2026). https://doi.org/10.1038/s41598-026-41379-5
Palavras-chave: mineração de argumentos, avaliações de medicamentos, análise de textos médicos, redes neurais, experiência do paciente