Clear Sky Science · it
Framework QRNN-GRU per l’estrazione automatica di argomentazioni e annotazioni nelle recensioni di farmaci
Perché contano le storie sui farmaci pubblicate online
Ogni giorno migliaia di persone pubblicano racconti personali sui farmaci che assumono: quanto funzionano, quali effetti collaterali compaiono e se la loro vita migliora davvero. Nascosto in questo flusso rumoroso di commenti c’è una miniera d’oro di informazioni per medici, pazienti e regolatori. La sfida è che queste recensioni sono disordinate, emotive e piene di termini medici specialistici. Questo articolo presenta un nuovo sistema di intelligenza artificiale (IA) progettato per leggere tali recensioni e individuare automaticamente argomentazioni ben strutturate su benefici e danni, trasformando aneddoti sparsi in evidenze organizzate.
Da opinioni frammentarie ad argomentazioni chiare
Quando le persone scrivono di medicinali, spesso formulano argomentazioni senza rendersene conto. Un genitore può affermare che un farmaco ha aiutato il figlio e poi fornire ragioni o esempi specifici a supporto. L’estrazione di argomentazioni è il campo di ricerca che cerca di rilevare questi mattoni costitutivi — affermazioni, ragioni di supporto (chiamate premesse) e frasi irrilevanti — all’interno del testo. Nelle recensioni mediche questo è più difficile che nei temi scolastici o nei dibattiti formali perché il linguaggio è informale, le frasi sono spesso incomplete e sintomi o effetti collaterali sono descritti in modi molto diversi. Gli autori si concentrano specificamente su questo contesto medico difficile, dove strumenti migliori potrebbero aiutare a riassumere in modo più affidabile le esperienze reali con i farmaci.
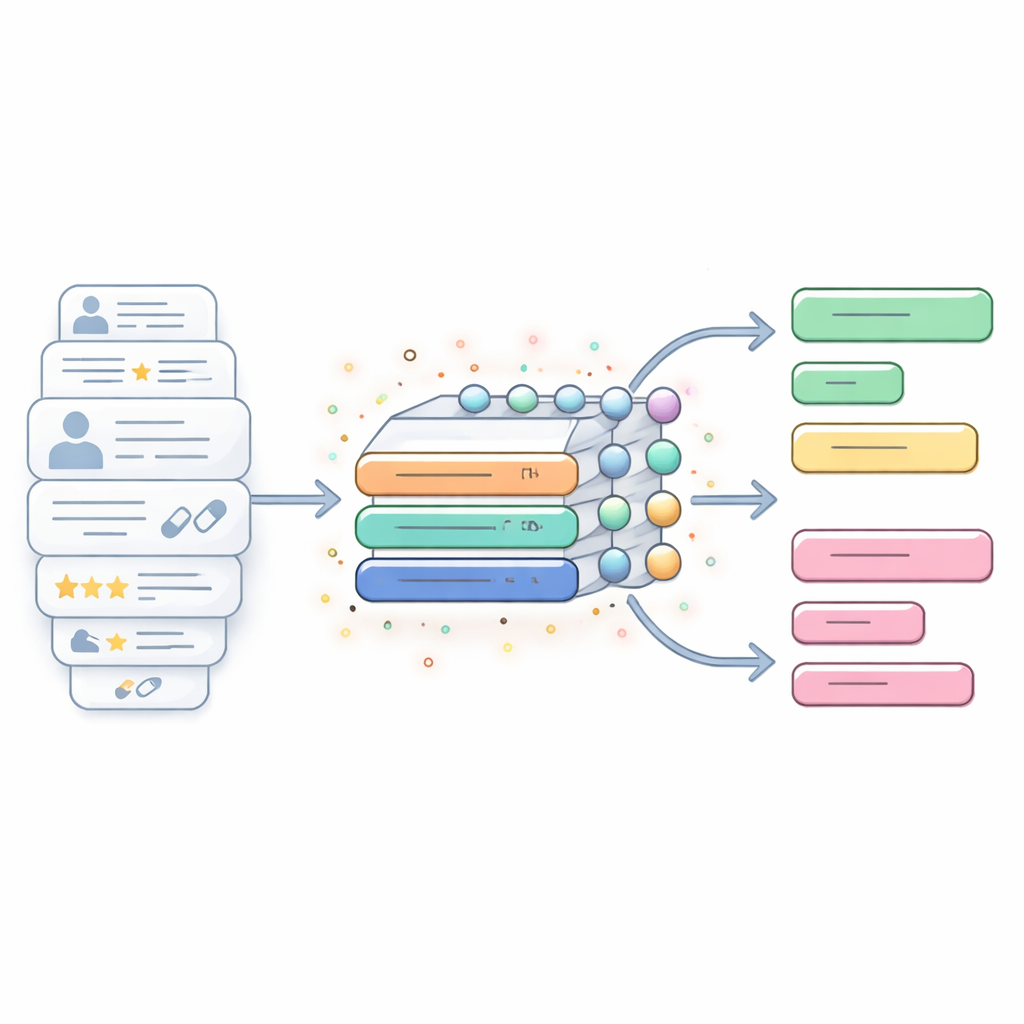
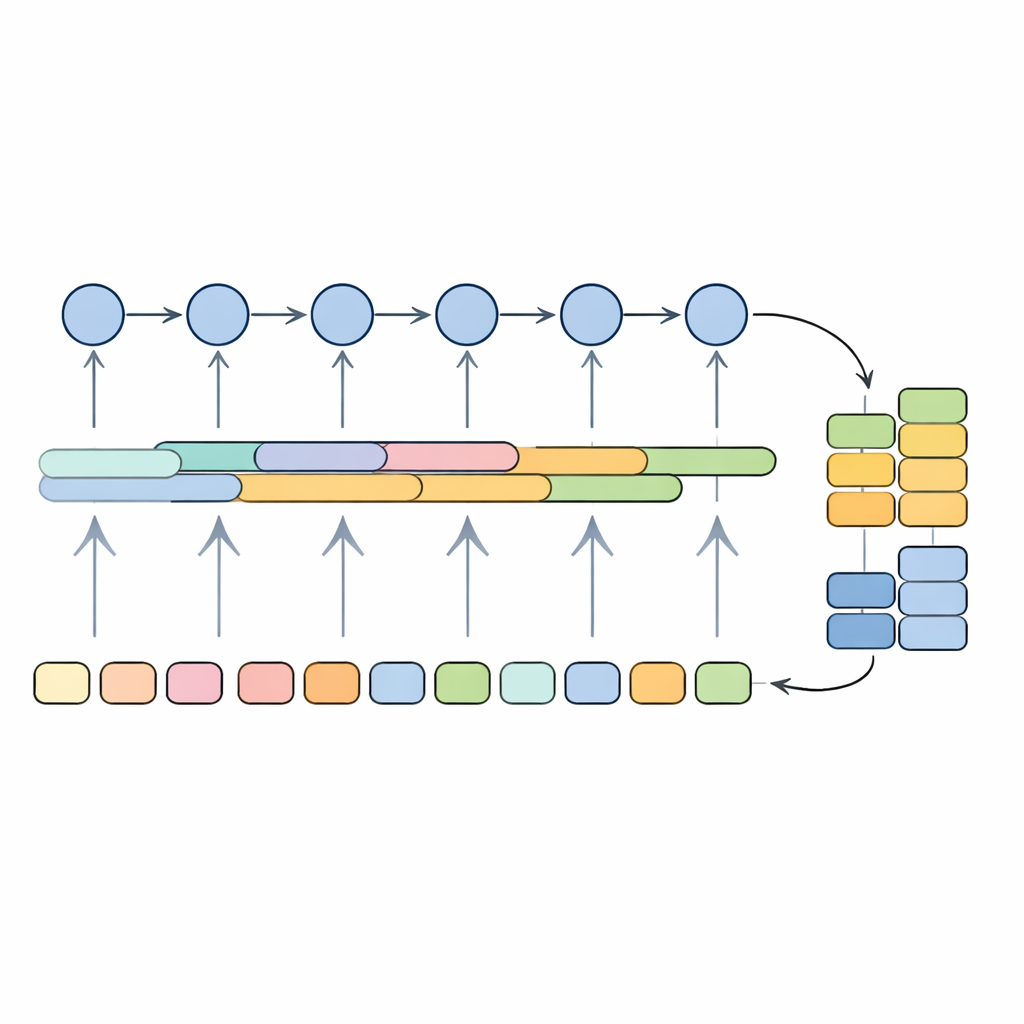
Un motore ibrido di IA progettato per testi lunghi e rumorosi
Lo studio introduce un modello ibrido di IA che combina due tecniche per l’elaborazione di sequenze: le reti neurali quasi ricorrenti (QRNN) e le unità ricorrenti gated (GRU). In termini semplici, la parte QRNN funziona come uno scanner veloce che cerca brevi pattern locali nel testo — frasi che segnalano elogi, lamentele o effetti collaterali — mentre la parte GRU è come un ascoltatore attento che tiene traccia di come questi pattern si evolvono lungo porzioni più lunghe della recensione. Insieme, mirano a bilanciare velocità e profondità: il sistema può gestire storie sui farmaci lunghe e disordinate senza diventare troppo lento o perdere il contesto importante distribuito su più frasi.
Lasciare che delle “lucciole” digitali ottimizzino il sistema
Progettare un modello di IA di questo tipo implica molte scelte: quante layer usare, quanto velocemente debba apprendere e quanto fortemente regolarizzarlo per evitare l’overfitting su peculiarità dei dati. Invece di impostare manualmente questi parametri, gli autori utilizzano un metodo di ottimizzazione ispirato al comportamento delle lucciole. In questo approccio, molte configurazioni candidate “lampeggiano” in base a quanto bene si comportano, e quelle migliori attraggono le altre, indirizzando gradualmente la ricerca verso una combinazione ad alte prestazioni. Questo ottimizzatore basato sulle lucciole affina il sistema QRNN–GRU in modo che apprenda in modo efficiente da grandi raccolte di recensioni degli utenti mantenendosi stabile durante l’addestramento.
Mettere il modello alla prova sui testi medici
I ricercatori hanno addestrato e valutato il loro sistema su un ampio dataset pubblico di recensioni di farmaci, in cui le frasi erano etichettate come affermazioni, premesse o non-argomentative tramite un processo di annotazione semi-automatico. Il modello ibrido ha raggiunto circa l’89 percento su una misura bilanciata di accuratezza e copertura (il punteggio F1) e circa il 91 percento di accuratezza complessiva, superando metodi più tradizionali come le macchine a vettori di supporto, il naïve Bayes, le foreste casuali e singoli modelli di deep learning come reti convoluzionali semplici, LSTM o GRU usati da soli. Ha inoltre confrontato favorevolmente con un ampio modello transformer simile a BERT, richiedendo però significativamente meno potenza di calcolo e memoria in fase di predizione. Per verificare se l’approccio generalizza oltre le recensioni di farmaci, gli autori lo hanno applicato anche a un benchmark di abstract di ricerche mediche e hanno rilevato che rimane competitivo con i sistemi all’avanguardia progettati per quel compito.
Cosa significa questo per i pazienti e la medicina
In termini semplici, questo lavoro dimostra che è possibile trasformare automaticamente le recensioni quotidiane sui farmaci in mappe strutturate di ciò che le persone affermano e del perché lo credono. Combinando uno scanner locale veloce (QRNN), un ascoltatore attento al contesto (GRU) e una strategia di ottimizzazione efficiente (ottimizzazione con lucciole), il sistema è in grado di setacciare grandi volumi di testo medico disordinato e separare in modo affidabile le argomentazioni significative sull’efficacia e sugli effetti collaterali dal rumore di fondo. Questo potrebbe aiutare i pazienti a ottenere riassunti più chiari delle esperienze altrui, assistere i clinici nell’individuare pattern emergenti di beneficio o danno e supportare i ricercatori che monitorano come i farmaci si comportano al di fuori degli studi clinici controllati. Gli autori osservano che il loro modello si concentra ancora principalmente su pattern a livello di frase e su testi medici, ma lo considerano un passo promettente verso strumenti più ricchi ed efficienti che diano senso alle storie che le persone raccontano sulla propria salute.
Citazione: Altameem, E., Alnuem, M. & Albassam, S. QRNN-GRU framework for automatic argument and annotation extraction in medical drug reviews. Sci Rep 16, 13581 (2026). https://doi.org/10.1038/s41598-026-41379-5
Parole chiave: estrazione di argomentazioni, recensioni di farmaci, analisi di testi medici, reti neurali, esperienza del paziente