Clear Sky Science · zh
传统中文双向阅读语料库:多语言眼动语料库的扩展
这项研究为何与日常阅读相关
我们大多数人习惯于从左到右在页面上阅读。但在传统中文中,文本可以横排也可以竖排,许多读者对两种格式都很熟练。本文介绍了一个规模庞大、采集严谨的数据集,记录了读者以两种方向阅读繁体中文段落时的眼动情况。通过比较相同文本在横排和竖排布局下眼睛的运动方式,研究者揭示了我们的视觉系统和大脑如何适应不同的排版方式——以及在表面之下阅读过程有多么相似。
同一语言的两种排版方式
传统中文书写视觉上密集,字符各自占据相同的方块空间。与英文不同,单词之间没有空格,字符可以排成横行或竖列。历史上,中文曾以竹简或木牍的竖排书写;横排直到上世纪才广泛普及,尤其是在科学和技术材料中。如今,像香港这样的地区在日常生活中仍会遇到两种格式的文本,从小说和报纸到教科书都有。这样不寻常的灵活性为科学家提供了难得的机会,来探究改变文本方向是否会改变阅读的基本机制——或者眼睛和大脑是否以大致相同的方式处理两种布局。
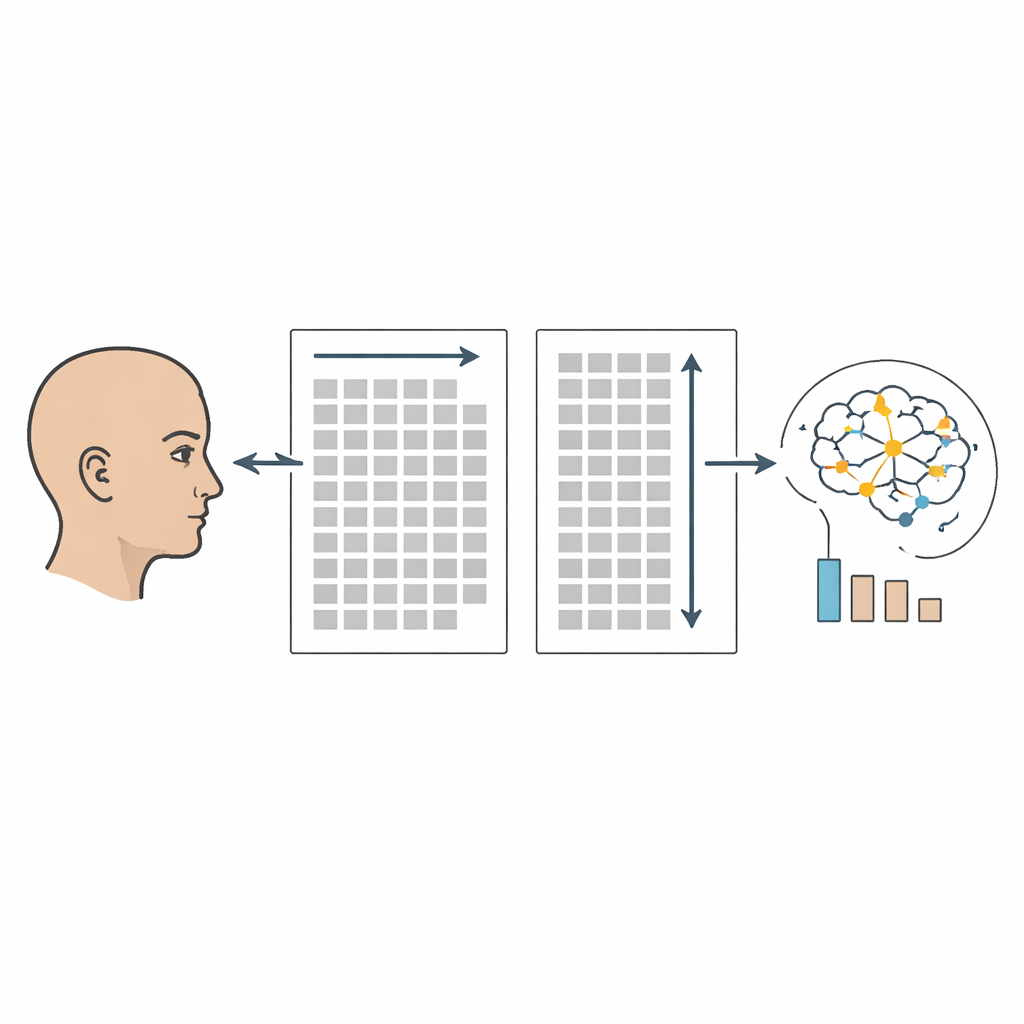
构建一个丰富的眼动语料库
为探讨这些问题,作者作为更大规模的多语言眼动语料库(MECO)项目的一部分,创建了双向中文MECO语料库。来自香港的六十名大学生阅读了十二篇繁体中文的说明性段落,风格类似简短的百科或维基百科条目,主题涵盖历史与自然现象等。每位参与者阅读六篇横排和六篇竖排的段落,文本在两种方向之间进行了精确对齐。在参与者静默阅读以理解内容的过程中,高精度眼动仪记录了他们注视的位置与持续时间,捕捉到逐时刻的测量数据,例如每个词被注视多少次、注视持续了多长时间以及回视的频率等。
眼动揭示了关于阅读的什么信息
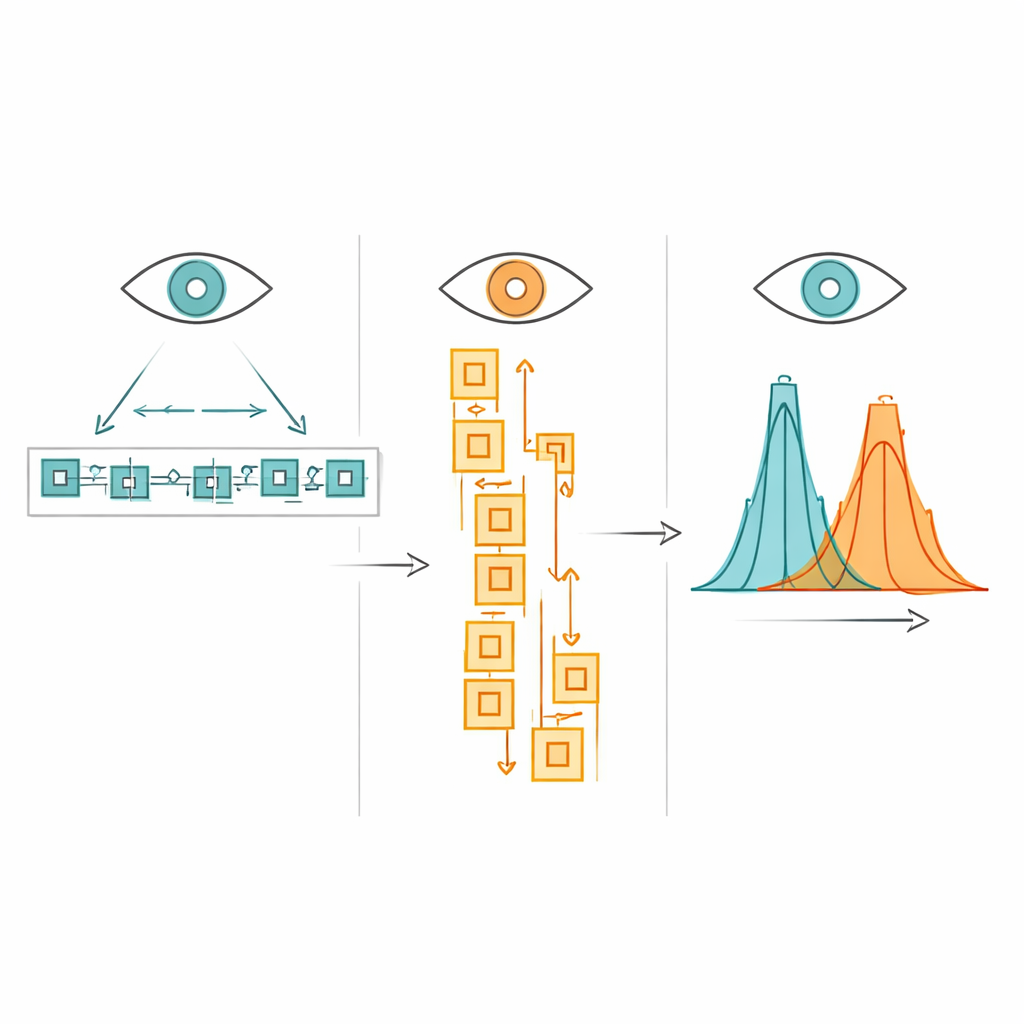
研究者对眼动数据进行了处理,以剔除技术性误差和异常注视,最终得到超过三万条的词级观测数据。随后他们发布了完整数据集,以及配套的脚本和文档,文件格式与其他MECO资源保持一致,方便全球科学家结合并比较不同语言的数据。研究团队通过不同方式划分数据并检验相同读者与相同词项是否表现出一致模式,来估计测量的可靠性。在参与者层面,可靠性非常高:个体的阅读行为在文本不同部分之间表现出惊人的稳定性。在词项层面,可靠性略低但仍然强劲,与其他语言的类似语料库一致,证明该数据集足够稳健,可用于详尽分析。
横排与竖排阅读:更多相似而非差异
接着,作者使用先进的统计模型检验在知名的影响眼动的因素是否也出现在这个新语料库中,以及这些效应是否随文本方向而变化。与以往中文研究一样,较长的词、较不常见的词以及笔画较多、视觉复杂的词会使眼睛停留更久。这些模式在横排与竖排阅读中均成立,表明识别词汇和处理视觉细节的核心过程在不同布局间是共享的。竖排阅读确实导致了略长的注视时间,以及词长和视觉复杂性效应更强,暗示竖排文本可能带来稍高的视觉负荷,尤其对较少接触竖排的读者。然而,总体相似之处远比差异更为显著。
对读者与未来研究的意义
从日常角度看,这项研究表明,熟练的繁体中文读者在处理横排与竖排文本时效率总体相似:无论行如何排列,面对更难或更复杂的词时,眼睛都会以可预测的方式放慢速度。该新语料库提供了一个丰富的公共资源,其他研究者可以用来检验阅读中眼动的理论、比较不同书写系统,并设计教育或辅助工具。由于竖排书写在若干亚洲语言以及年长的中文读者中仍较为常见,理解特定方向的经验如何塑造眼动,或有助于为不同读者群体设计更舒适、更易接近的阅读材料和干预方案。
引用: Pan, J., Xi, Y., Tan, D. et al. The Corpus of Bidirectional Reading of Traditional Chinese Text: An Extension of the Multilingual Eye-Movement Corpus. Sci Data 13, 628 (2026). https://doi.org/10.1038/s41597-026-06989-8
关键词: 眼动追踪, 中文阅读, 文本方向, 阅读研究, 视觉词汇识别