Clear Sky Science · nl
Het Corpus van Bidirectioneel Lezen van Traditionele Chinese Tekst: Een Uitbreiding van het Multilingual Eye-Movement Corpus
Waarom deze studie ertoe doet voor alledaags lezen
De meesten van ons gaan ervan uit dat we van links naar rechts over een pagina lezen. Maar in het traditionele Chinees kan tekst zowel horizontaal als verticaal worden gezet, en veel lezers zijn met beide stijlen vertrouwd. Dit artikel introduceert een grote, zorgvuldig verzamelde dataset die de oogbewegingen van lezers volgt terwijl ze traditionele Chinese passages in beide richtingen lezen. Door te vergelijken hoe de ogen bewegen over horizontale en verticale lay-outs van dezelfde teksten, werpen de onderzoekers licht op hoe ons visuele systeem en brein zich aanpassen aan verschillende manieren om woorden op een pagina te zetten — en hoe vergelijkbaar lezen onder de oppervlakte eigenlijk is.
Twee manieren om dezelfde taal weer te geven
Traditioneel Chinees schrift is visueel dicht en bestaat uit karakters die elk dezelfde vierkante ruimte vullen. In tegenstelling tot het Engels zijn er geen spaties tussen woorden, en karakters kunnen worden gerangschikt in horizontale regels of verticale kolommen. Historisch werd Chinees verticaal geschreven op bamboe- of houten stroken; horizontale lay-outs werden pas in de afgelopen eeuw algemeen, vooral voor wetenschappelijke en technische materialen. Tegenwoordig komen lezers in plaatsen als Hongkong beide formaten nog dagelijks tegen, van romans en kranten tot leerboeken. Deze ongebruikelijke flexibiliteit geeft wetenschappers een zeldzame kans om te onderzoeken of het veranderen van tekstrichting de basale mechanica van lezen verandert — of dat oog en brein beide lay-outs grotendeels op dezelfde manier verwerken.
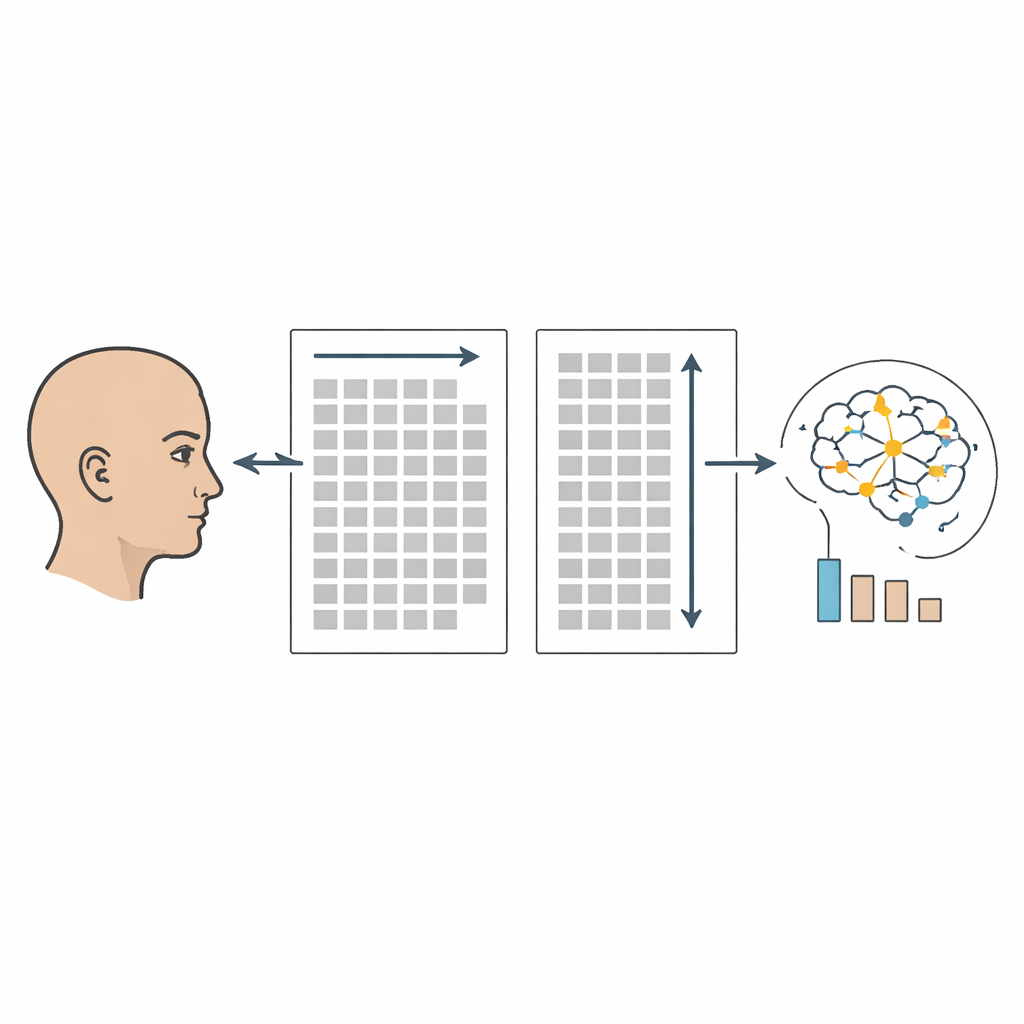
Het opbouwen van een rijk eyetracking-corpus
Om deze vragen te onderzoeken, creëerden de auteurs het Bidirectional Chinese MECO-corpus als onderdeel van het grotere Multilingual Eye-Movement Corpus-project. Zestig universiteitsstudenten in Hongkong lazen twaalf uitleggende passages in traditioneel Chinees, vergelijkbaar in stijl met korte encyclopedische of Wikipedia-achtige artikelen over onderwerpen als geschiedenis en natuurverschijnselen. Iedere deelnemer las zes passages in een horizontale lay-out en zes in een verticale lay-out, waarbij dezelfde tekstlijnen zorgvuldig over de richtingen werden afgestemd. Terwijl deelnemers stil lazen met begrip als doel, registreerde een hogeresolutie-eyetracker waar ze keken en hoe lang, en legde moment-tot-moment-maatregelen vast zoals hoe vaak elk woord werd gefixeerd, hoe lang het oog bleef hangen en hoe vaak het achteruit sprong.
Wat oogbewegingen onthullen over lezen
De onderzoekers verwerkten de eyetracking-gegevens om technische fouten en ongebruikelijke fixaties te verwijderen, en eindigden met meer dan dertigduizend observaties op woordniveau. Vervolgens maakten ze de volledige dataset openbaar, plus bijbehorende scripts en documentatie, in formaten die overeenkomen met andere MECO-bronnen, waardoor het eenvoudig is voor wetenschappers wereldwijd om gegevens over talen heen te combineren en te vergelijken. Het team schatte hoe betrouwbaar de metingen waren door de data op verschillende manieren te splitsen en te onderzoeken of dezelfde lezers en dezelfde woorden consistente patronen lieten zien. Op deelnemerniveau was de betrouwbaarheid extreem hoog: het leesgedrag van mensen was opvallend stabiel over verschillende delen van de teksten. Op woordniveau was de betrouwbaarheid iets lager maar nog steeds stevig, in lijn met vergelijkbare corpora in andere talen, wat bevestigt dat de dataset robuust genoeg is voor gedetailleerde analyses.
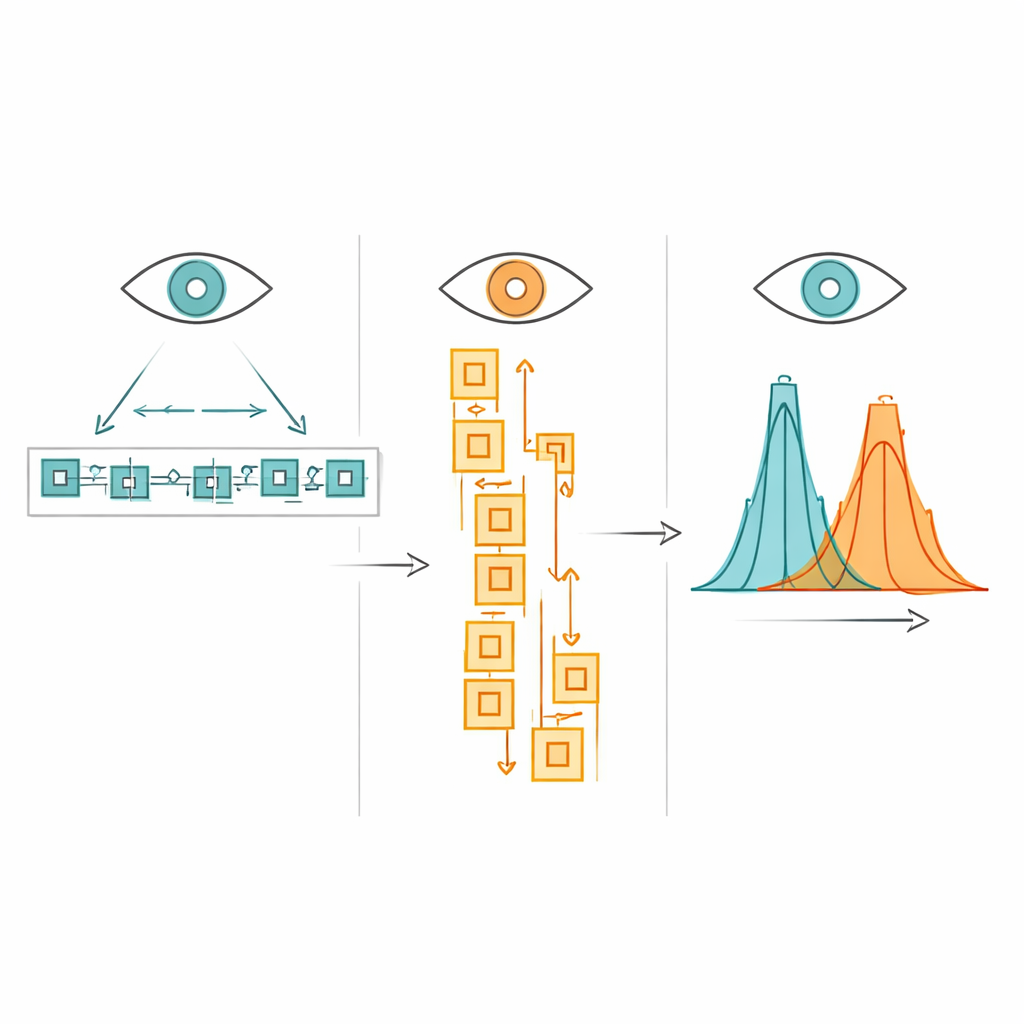
Horizontaal en verticaal lezen: meer overeenkomsten dan verschillen
Vervolgens gebruikten de auteurs geavanceerde statistische modellen om te testen of bekende invloeden op oogbewegingen ook in dit nieuwe corpus verschenen, en of ze veranderden met tekstrichting. Zoals in eerdere studies van het Chinees besteedden de ogen meer tijd aan langere woorden, minder frequente woorden en visueel complexere woorden met veel streken. Deze patronen hielden stand bij zowel horizontaal als verticaal lezen, wat laat zien dat kernprocessen van woordherkenning en omgaan met visuele details gedeeld worden tussen lay-outs. Verticaal lezen leidde wel tot iets langere fixaties en sterkere effecten van woordlengte en visuele complexiteit, wat suggereert dat verticale passages net iets zwaardere visuele eisen kunnen stellen, vooral voor lezers die ze minder vaak tegenkomen. Desondanks waren de algemene overeenkomsten veel opvallender dan de verschillen.
Wat dit betekent voor lezers en toekomstig onderzoek
In gewone bewoordingen laat deze studie zien dat vaardige lezers van traditioneel Chinees horizontale en verticale tekst over het algemeen met vergelijkbare efficiëntie verwerken: hun ogen vertragen op voorspelbare manieren bij moeilijkere of meer complexe woorden, ongeacht hoe de regels lopen. Het nieuwe corpus biedt een rijke publieke bron die andere wetenschappers kunnen gebruiken om theorieën over oogbewegingen tijdens het lezen te testen, verschillende schriftsystemen te vergelijken en educatieve of ondersteunende hulpmiddelen te ontwerpen. Omdat verticale schriftvoering in verschillende Aziatische talen en onder oudere Chinese lezers nog veel voorkomt, kan begrip van hoe ervaring met een bepaalde richting oogbewegingen vormt ook helpen bij het ontwerpen van leesmateriaal en interventies die comfortabeler en toegankelijker zijn voor verschillende groepen lezers.
Bronvermelding: Pan, J., Xi, Y., Tan, D. et al. The Corpus of Bidirectional Reading of Traditional Chinese Text: An Extension of the Multilingual Eye-Movement Corpus. Sci Data 13, 628 (2026). https://doi.org/10.1038/s41597-026-06989-8
Trefwoorden: eyetracking, Chinees lezen, tekstrichting, leesonderzoek, visuele woordherkenning