Clear Sky Science · zh
用于心脏磁共振图像嵌入并具备零样本能力的对比语言图像预训练
为何让计算机“读”心脏影像很重要
心脏MRI检查能在症状明显出现之前揭示细微的疾病征象,但每次检查包含数百张图像,专家解读耗时很长。本研究探索一种人工智能系统是否能学会“理解”这些复杂的扫描和相应的书面报告,从而帮助医生对病例进行分类、识别疾病模式,甚至撰写报告,而无需逐帧明确标注每张图像的含义。
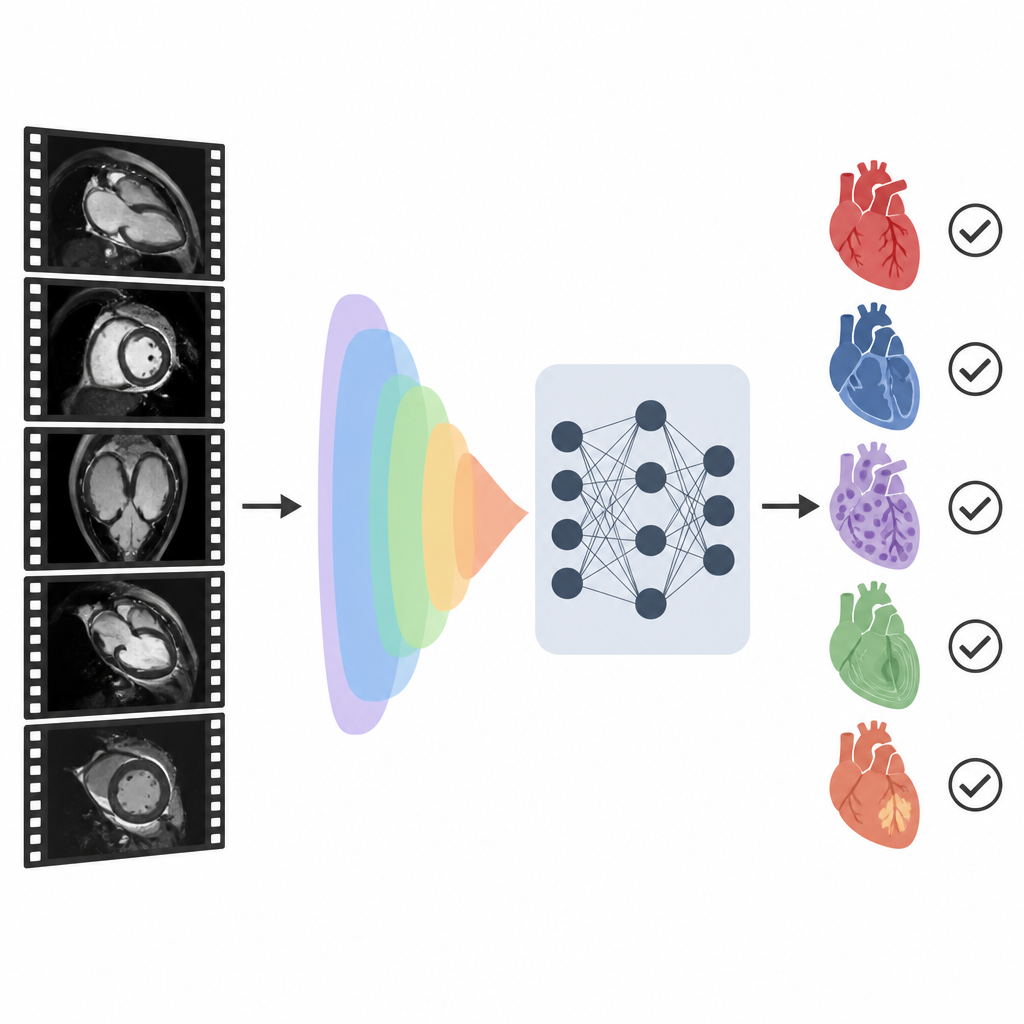
一种新的图像与文字配对方式
研究者构建了名为CMR-CLIP的系统,将心脏MRI图像与医生报告中的短印象段落相连接。他们不再把每张图像单独处理,而是把整个检查视作由多种标准心脏视图和成像技术组成的短视频。与此同时,系统读取描述关键发现和诊断的书面印象。通过在同一医疗体系中训练逾14,000例既往检查及其报告,模型逐步学会一种共享的“语言”,将图像中的视觉模式与文本短语联系起来,而无需为每帧绘制轮廓或手工标注。
几乎无需教学就能学会识别疾病
训练完成后,CMR-CLIP在心脏病学日常面临的经典任务上进行了测试,例如识别心脏收缩功能减弱、心腔扩大或心肌肥厚等。在零样本设置下,模型仅接收诸如“左心室扩张”之类简短、可读的提示,并被要求判断其是否适用于新的检查。在这种条件下,它在七种常见所见和若干主要疾病(包括肥厚型心肌病和心脏淀粉样变性)上都取得了稳健的准确率。它明显优于通用的图像—文本系统,表明心脏MRI存在通用模型难以捕捉的特有模式。
少量示例也能显著提升表现
团队还尝试了少样本学习,让模型在每种病况仅看到少量带标签的例子后,再对新病例进行分类。使用每类仅一例、二例或四例这样极小的训练集,CMR-CLIP仍然稳步改进,且常常达到或超过那些见过更多样本的其他模型。例如,在判断左心功能障碍时,性能从1个示例时的中等提升至32个示例时的极高,对心腔扩大和心肌肥厚亦有类似结果。这表明一旦学会共享的图像—文本空间,系统能够以远少于常规所需的标注数据适应新的临床任务。
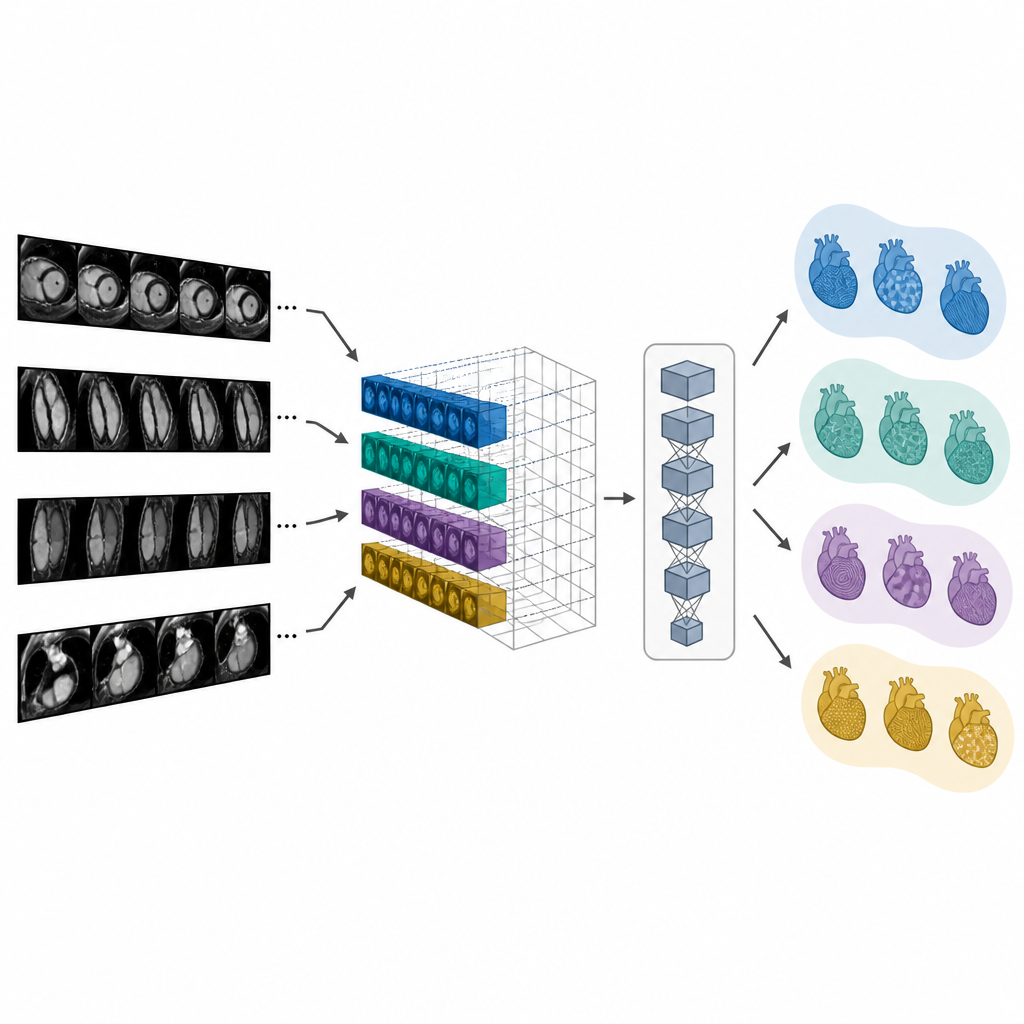
检索匹配影像与撰写报告
由于CMR-CLIP将图像与文字映射到共同空间,它可以在给定影像或文本查询时检索最相关的检查或报告。测试中,它比对照模型更有可能将真实匹配的报告或检查排在结果前列,即便数据来自不同医院或不同型号的MRI设备。作者随后以两种方式使用学得的图像特征来辅助报告撰写。一种方法是直接找到最相似的既往病例并复用其印象。第二种方法称为CMR-TARGET,将图像特征输入文本生成器,由生成器逐句撰写新的印象。这种生成式方法在标准语言评价指标上生成的摘要更接近真实临床报告。
在不同扫描仪与成像细节间表现稳健
研究者考察了设计选择如何影响性能。包括运动的“cine”影像和能够突出瘢痕组织的对比增强图像,以及多角度心脏视图,都显著提升了系统的检索与分类能力。使用更多帧数有助于捕捉心动周期中的细微变化,但也增加了计算需求。团队还强调了稳定性的重要性:当帧顺序被打乱或部分移除时,CMR-CLIP的内部表示变化很小,表明它侧重于与疾病相关的信号而非脆弱的细节。跨不同扫描仪品牌和磁场强度的测试显示准确性相对稳定,暗示模型能推广到训练中心以外的环境。
这对心脏护理可能意味着什么
对非专业读者而言,主要信息是计算机现在能够从心脏MRI检查及其书面解读中学到丰富且可复用的概念,即便没有对每张图像进行详细标注。CMR-CLIP充当一个专为心脏MRI打造的基础模型:它可支持多种重要心脏疾病的诊断、帮助检索相似既往病例,并起草结构化或自由文本报告供医生编辑。尽管它不能取代专家读片且仍依赖训练数据的质量与多样性,但这种方法有望减少解读时间、提高不同医院间结果的一致性,并最终帮助将基于MRI的先进心脏护理推广到更多患者。
引用: Nakashima, M., Qiu, J., Huang, P. et al. Contrastive language image pretraining for a cardiac magnetic resonance image embedding with zero-shot capabilities. Nat Commun 17, 4416 (2026). https://doi.org/10.1038/s41467-026-73022-2
关键词: 心脏MRI, 医学人工智能, 视-语模型, 心肌病, 临床决策支持