Clear Sky Science · ar
التدريب التبايني للغة والصورة لنمذجة تضمين صور التصوير بالرنين المغناطيسي القلبي بقدرات عدم التعلم المسبق
لماذا يهم تعليم الحواسيب قراءة فحوصات القلب
يمكن لفحوصات الـMRI القلبية أن تكشف إشارات دقيقة للأمراض قبل أن تظهر الأعراض بشكل واضح، لكن كل فحص يتضمن مئات الصور التي تستغرق وقتًا طويلاً لتفسيرها من قبل الأخصائيين. تبحث هذه الدراسة فيما إذا كان نظام ذكاء اصطناعي قادرًا على "فهم" هذه الفحوصات المعقدة وتقاريرها المكتوبة كي يساعد الأطباء في فرز الحالات، والتعرف على أنماط المرض، وحتى صياغة التقارير، وكل ذلك دون أن يُعلم صراحة ماذا تظهر كل صورة.
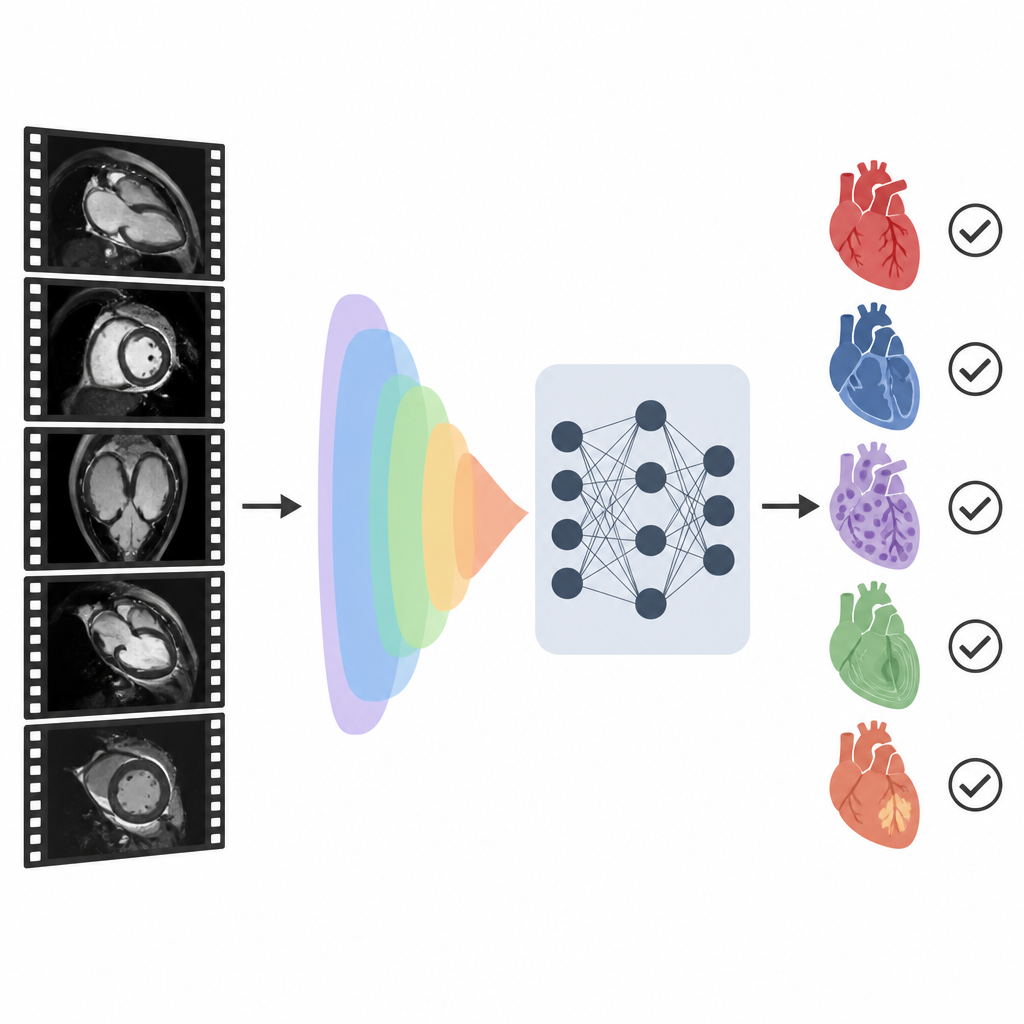
طريقة جديدة للاقتران بين الصور والكلمات
بنَى الباحثون نظامًا أسموه CMR-CLIP يربط صور الـMRI القلبية بقسم الملخص القصير في تقرير الطبيب. بدلًا من التعامل مع كل صورة بشكل منفصل، اعتبروا الفحص بأكمله كمقطع فيديو قصير مكوّن من العديد من مشاهد القلب وتقنيات التصوير القياسية. وفي الوقت نفسه، يقرأ النظام الانطباع المكتوب الذي يصف النتائج والتشخيصات الرئيسية. من خلال التدريب على أكثر من 14,000 فحص وتقرير سابق من نظام صحي واحد، يتعلم النموذج تدريجيًا "لغة" مشتركة تربط الأنماط البصرية في الصور بالعبارات في النص، من دون الحاجة إلى مخططات مرسومة يدويًا أو تسميات لكل إطار.
التعلّم على التعرف على المرض بقليل من التعليم
بعد التدريب، اختبروا CMR-CLIP على مهام يومية يواجهها أخصائيّو القلب، مثل اكتشاف ضعف ضخ القلب، اتساع الحجرات، أو سماكة عضلة القلب. في إعداد عدم التعلم المسبق (zero-shot)، أعطِي النموذج فقط مطالبات قصيرة قابلة للقراءة البشرية مثل "البطين الأيسر متوسع" وطُلب منه تقرير ما إذا كانت تنطبق على فحص جديد. وحتى في هذه الظروف، حقق دقة جيدة عبر سبع نتائج شائعة وعدد من الأمراض الرئيسية، بما في ذلك اعتلال عضلة القلب الضخامي والوَرَمَة القلبية النشوانية. وتفوّق بوضوح على أنظمة الصور-نص العامة، مما يوضح أن صور الـMRI القلبية تحتوي أنماطًا فريدة لا تلتقطها النماذج العامة جيدًا.
التحسن بعدد قليل من الأمثلة
جرّب الفريق أيضًا التعلم بعدد قليل من الأمثلة (few-shot)، حيث يرى النموذج فقط عددًا ضئيلًا من الأمثلة الموسومة لكل حالة قبل أن يُطلب منه تصنيف حالات جديدة. باستخدام مجموعات تدريب صغيرة جدًا تصل إلى فحص واحد أو اثنين أو أربعة لكل فئة، استمر CMR-CLIP في التحسن غالبًا وبلغ مستوى مساويًا أو متفوقًا على نماذج أخرى شاهدت أمثلة أكثر بكثير. على سبيل المثال، عند تقدير ضعف الجانب الأيسر من القلب، تحسّن الأداء من مقبول مع مثال واحد إلى عالٍ جدًا مع 32 مثالًا، وشوهدت نتائج مماثلة لاتساع الحجرات وسماكة العضلة. وهذا يشير إلى أنه بمجرد تعلّم فضاء مشترك بين الصورة والنص، يمكن للنظام التكيّف مع مهام سريرية جديدة ببيانات موسومة أقل كثيرًا من المعتاد.
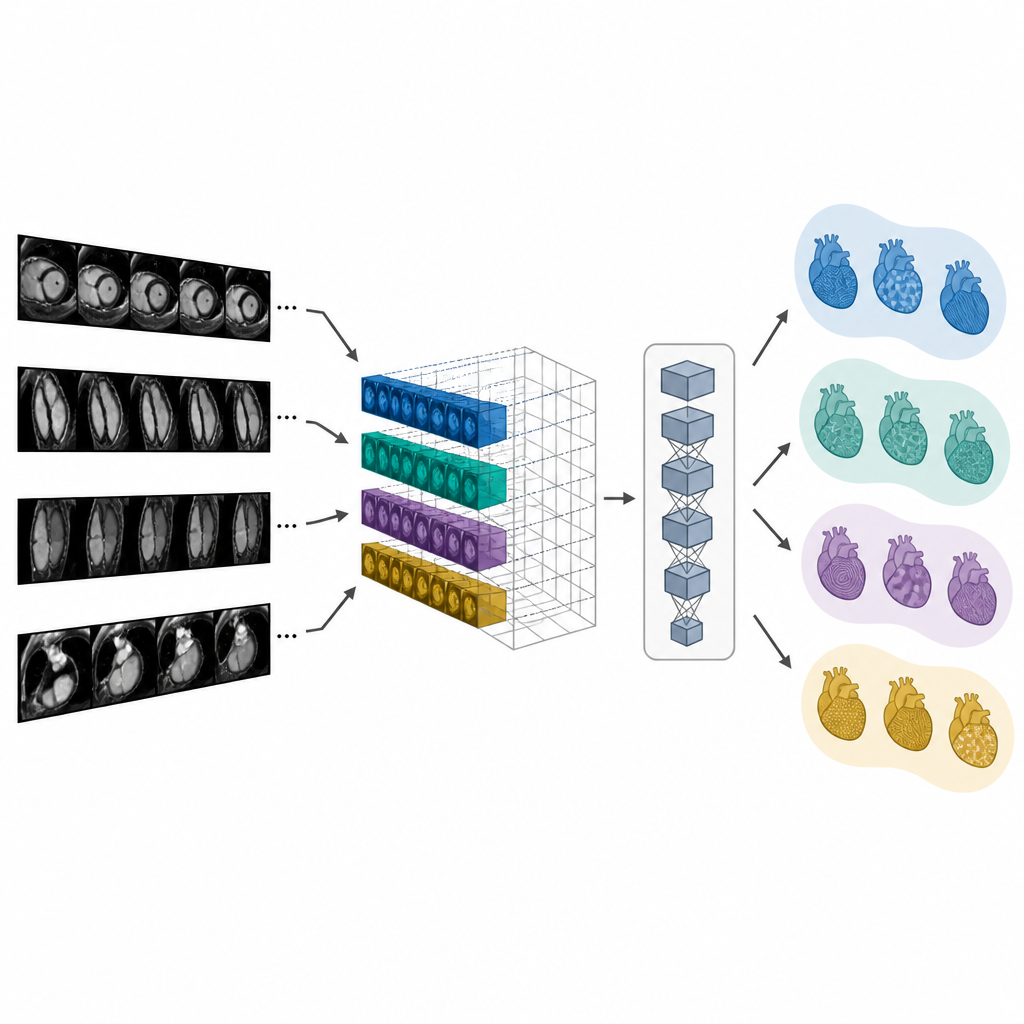
استرجاع الفحوص المتطابقة وصياغة التقارير
لأن CMR-CLIP يربط الصور والكلمات في فضاء مشترك، يمكنه استرجاع الفحص أو التقرير الأكثر صلة عندما يُعطى إما فحصًا أو استعلامًا نصيًا. في الاختبارات، كان أكثر احتمالًا بكثير من النماذج المقارنة أن يضع التقرير أو الفحص المطابق الحقيقي قرب أعلى النتائج، حتى عندما جاءت البيانات من مستشفيات أو أجهزة MRI مختلفة. استخدم المؤلفون بعد ذلك الميزات البصرية المتعلمة بطريقتين للمساعدة في التقرير. الطريقة الأولى تجد ببساطة أقرب حالة سابقة وتعيد استخدام انطباعها. الطريقة الثانية، المسماة CMR-TARGET، تُدخِل الميزات البصرية إلى مولّد نص ليكتب الانطباع الجديد جملة بجملة. أنتج هذا النهج التوليدي ملخصات تطابقت أكثر مع التقارير السريرية الحقيقية وفق مقاييس لغوية معيارية.
قوي عبر أجهزة ومسارات تصوير مختلفة
درس الباحثون كيف أثّرت خيارات التصميم على الأداء. أضافت متابعة كل من صور السينما المتحركة وصور التباين الخاصة التي تُبرز النسيج الندبي، بالإضافة إلى زوايا مشاهدة متعددة للقلب، تحسينًا واضحًا لقدرة النظام على الاسترجاع والتصنيف. ساعد استخدام مزيد من الإطارات لكل فحص في التقاط تغيّرات دقيقة على مدى نبضة القلب، رغم أنه تطلّب قدرة حوسبية أكبر. كما أكّد الفريق أهمية الثبات: فتمثيل CMR-CLIP الداخلي تغيّر قليلًا عندما أُعيد ترتيب الإطارات أو أُزيلت جزئيًا، ما يدل على أنه يركّز على إشارات ذات صلة بالمرض بدلًا من تفاصيل هشة. أظهرت الاختبارات عبر علامات أجهزة وقوى مغناطيسية مختلفة أن الدقة بقيت مستقرة نسبيًا، مما يوحي بإمكانية تعميم النموذج إلى ما بعد المركز الذي درّب فيه.
ماذا قد يعني هذا لرعاية القلب
بالنسبة لغير المتخصصين، الرسالة الأساسية هي أن الحواسيب أصبحت قادرة على تعلم مفاهيم غنية وقابلة لإعادة الاستخدام من فحوصات الـMRI القلبية وتفسيراتها المكتوبة، حتى من دون تسميات مفصلة على كل صورة. يعمل CMR-CLIP كنموذج تأسيسي مخصّص لتصوير القلب بالرنين المغناطيسي: يمكنه دعم تشخيص عدة أمراض قلبية مهمة، والمساعدة في استرجاع حالات سابقة مشابهة، وصياغة تقارير منظمة أو نص حر يمكن للأطباء تعديلها. وبينما لا يحل محل القرّاء الخبراء ولا يزال يعتمد على جودة وتنوّع بيانات التدريب، قد يقلّل هذا النهج من زمن القراءة، ويزيد اتساق النتائج بين المستشفيات، ويساهم في توسيع الرعاية المتقدمة القائمة على الـMRI لعدد أكبر من المرضى.
الاستشهاد: Nakashima, M., Qiu, J., Huang, P. et al. Contrastive language image pretraining for a cardiac magnetic resonance image embedding with zero-shot capabilities. Nat Commun 17, 4416 (2026). https://doi.org/10.1038/s41467-026-73022-2
الكلمات المفتاحية: تصوير الرنين المغناطيسي القلبي, الذكاء الاصطناعي الطبي, نموذج رؤية-لغة, اعتلال عضلة القلب, دعم القرار السريري