Clear Sky Science · sv
Kontrastiv språk-bildförträningsmodell för inbäddning av hjärt-MR-bilder med nollskottskapacitet
Varför det är viktigt att lära datorer läsa hjärtundersökningar
Hjärt-MR-undersökningar kan avslöja subtila tecken på sjukdom långt innan symtomen blir uppenbara, men varje undersökning innehåller hundratals bilder som tar specialister lång tid att gå igenom. Denna studie undersöker om ett artificiellt intelligenssystem kan lära sig att ”förstå” dessa komplexa undersökningar och deras skriftliga rapporter så att det kan hjälpa läkare sortera fall, känna igen sjukdomsmönster och till och med utarbeta rapporter — allt utan att uttryckligen få veta vad varje bild visar.
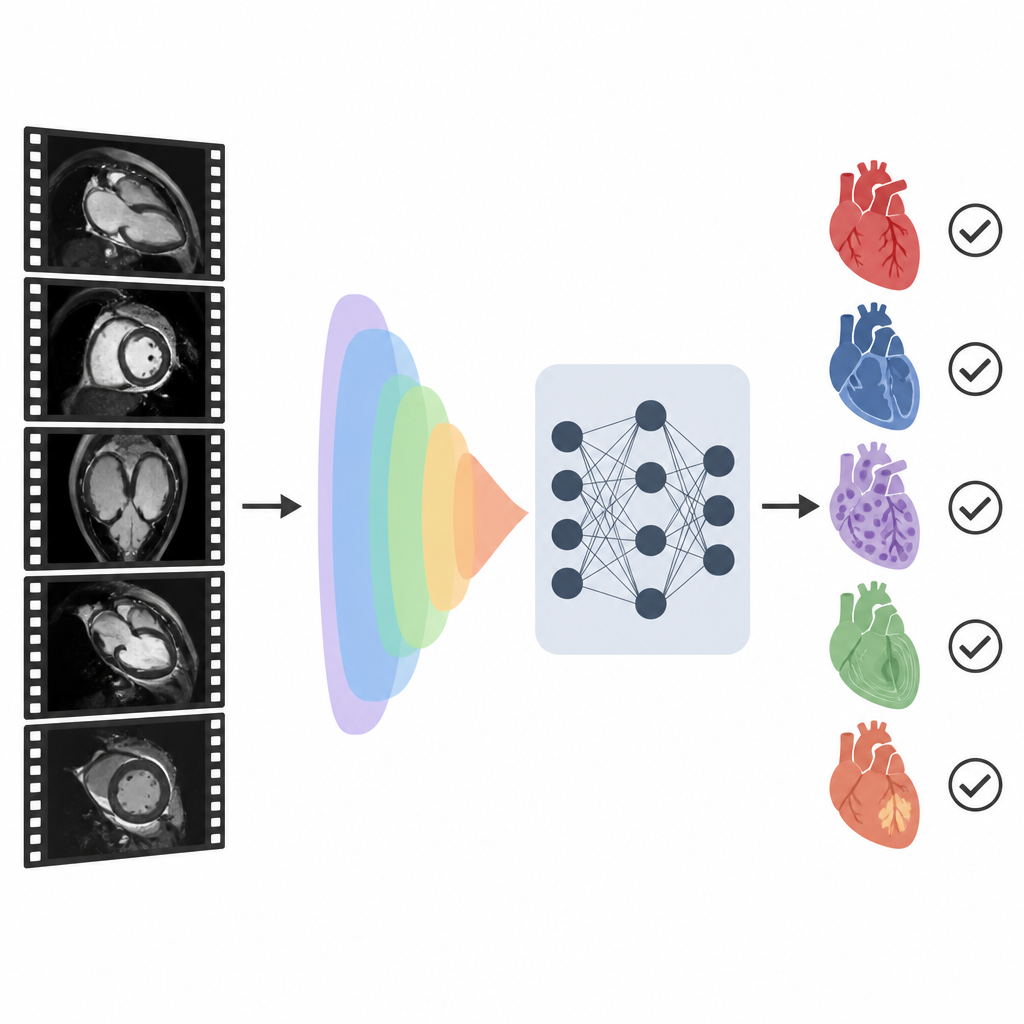
Ett nytt sätt att para ihop bilder och ord
Forskarna byggde ett system kallat CMR-CLIP som förbinder hjärt-MR-bilder med läkarens korta sammanfattningsdel i rapporten. I stället för att behandla varje bild för sig behandlar de en hel undersökning som om det vore en kort video bestående av många standardiserade hjärtvyer och avbildningstekniker. Samtidigt läser systemet den skrivna slutsatsen som beskriver nyckelfynd och diagnoser. Genom att träna på mer än 14 000 tidigare undersökningar och deras rapporter från ett sjukvårdssystem lär sig modellen gradvis ett gemensamt ”språk” som länkar visuella mönster i bilderna med fraser i texten, utan att behöva handritade konturer eller manuella etiketter för varje bildruta.
Lära sig känna igen sjukdom med nästan ingen undervisning
När CMR-CLIP väl var tränat testades det på klassiska uppgifter som kardiologer möter dagligen, såsom att upptäcka nedsatt pumpfunktion, förstorade hjärtkammare eller förtjockad hjärtmuskel. I en nollskottsinställning fick modellen endast korta, människoläsbara promptar som ”vänster kammare är dilaterad” och ombads avgöra om de gällde en ny undersökning. Även under dessa förutsättningar nådde den god noggrannhet för sju vanliga fynd och flera större sjukdomar, inklusive hypertrofisk kardiomyopati och kardiell amyloidos. Den slog tydligt allmänna bild–text-system, vilket visar att hjärt-MR rymmer unika mönster som generiska modeller inte fångar väl.
Bli bättre med bara några få exempel
Teamet prövade också få-skottsinlärning, där modellen endast ser ett litet antal märkta exempel för varje tillstånd innan den ombeds klassificera nya fall. Med mycket små träningsset, ner till en, två eller fyra undersökningar per kategori, förbättrades CMR-CLIP ändå stadigt och matchade ofta eller överträffade andra modeller som sett många fler exempel. Till exempel vid bedömning av vänstersidigt hjärtfunktionsbortfall steg prestandan från rimlig med ett exempel till mycket hög med 32 exempel, och jämförbara resultat sågs för kammarförstoring och muskelförtjockning. Detta tyder på att när det gemensamma bild–text-utrymmet är inlärt kan systemet anpassas till nya kliniska uppgifter med mycket mindre märkt data än vanligt.
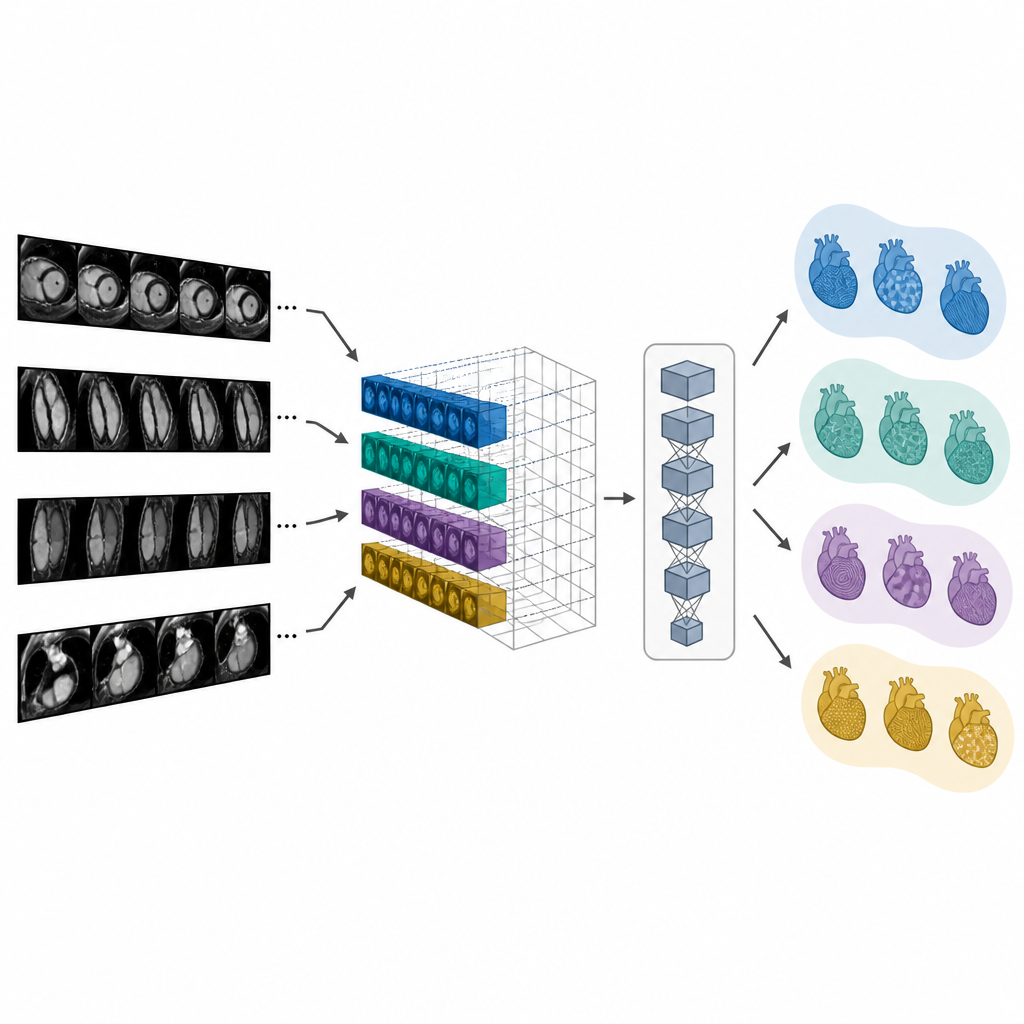
Hitta matchande undersökningar och utarbeta rapporter
Eftersom CMR-CLIP länkar bilder och ord i ett gemensamt utrymme kan det hämta den mest relevanta undersökningen eller rapporten när det ges antingen en bild eller en textfråga. I tester rankade det med större sannolikhet än jämförande modeller den verkliga matchande rapporten eller undersökningen högt bland resultaten, även när data kom från olika sjukhus eller MR-scanners. Författarna använde sedan de inlärda bildfunktionerna på två sätt för att hjälpa rapporteringen. En metod hittar helt enkelt det mest lika tidigare fallet och återanvänder dess slutsats. En andra metod, kallad CMR-TARGET, matar bildfunktionerna till en textgenerator som skriver en ny slutsats mening för mening. Denna generativa metod producerade sammanfattningar som enligt standardiserade språkmått överensstämde bättre med verkliga kliniska rapporter.
Robust över olika scannrar och bilddetaljer
Forskarna granskade hur designval påverkade prestanda. Att inkludera både rörliga ”cine”-bilder och specialkontrastbilder som framhäver ärrvävnad, samt flera visningsvinklar av hjärtat, förbättrade tydligt systemets förmåga att hämta och klassificera fall. Att använda fler rutor per undersökning hjälpte till att fånga subtila förändringar över hjärtslaget, även om det också krävde mer beräkningskraft. Teamet betonade också vikten av stabilitet: CMR-CLIP:s interna representation förändrades lite när rutor slogs om eller delvis togs bort, vilket indikerar att den fokuserar på sjukdomsrelevanta signaler snarare än sköra detaljer. Tester över olika scanner-märken och magnetfältstyrkor visade att noggrannheten förblev relativt stabil, vilket tyder på att modellen kan generalisera bortom den klinik där den tränades.
Vad detta kan innebära för hjärtvården
För en icke-specialist är huvudbudskapet att datorer nu kan lära sig rika, återanvändbara begrepp från hjärt-MR-undersökningar och deras skriftliga tolkningar, även utan detaljerade etiketter på varje bild. CMR-CLIP fungerar som en grundmodell anpassad till hjärt-MR: den kan stödja diagnostik av flera viktiga hjärtsjukdomar, hjälpa till att hitta liknande tidigare fall och utarbeta strukturerade eller fri-text-rapporter som läkare kan redigera. Även om den inte ersätter expertläsare och fortfarande är beroende av kvaliteten och variationen i dess träningsdata, kan detta tillvägagångssätt minska genomläsningstid, göra resultat mer konsekventa mellan sjukhus och så småningom hjälpa till att utöka avancerad MR-baserad hjärtvård till fler patienter.
Citering: Nakashima, M., Qiu, J., Huang, P. et al. Contrastive language image pretraining for a cardiac magnetic resonance image embedding with zero-shot capabilities. Nat Commun 17, 4416 (2026). https://doi.org/10.1038/s41467-026-73022-2
Nyckelord: hjärt-MR, medicinsk AI, vision–språk-modell, kardiomyopati, kliniskt beslutsstöd