Clear Sky Science · es
Preentrenamiento contrastivo lenguaje-imagen para una incrustación de resonancia magnética cardiaca con capacidades de zero-shot
Por qué importa enseñar a los ordenadores a leer exploraciones del corazón
Las resonancias magnéticas cardiacas pueden revelar signos sutiles de enfermedad mucho antes de que los síntomas sean evidentes, pero cada exploración incluye cientos de imágenes que requieren mucho tiempo de lectura por parte de especialistas. Este estudio explora si un sistema de inteligencia artificial puede aprender a "entender" estas exploraciones complejas y sus informes escritos para ayudar a los médicos a clasificar casos, reconocer patrones de enfermedad e incluso redactar informes, todo ello sin que se le indique explícitamente qué muestra cada imagen.
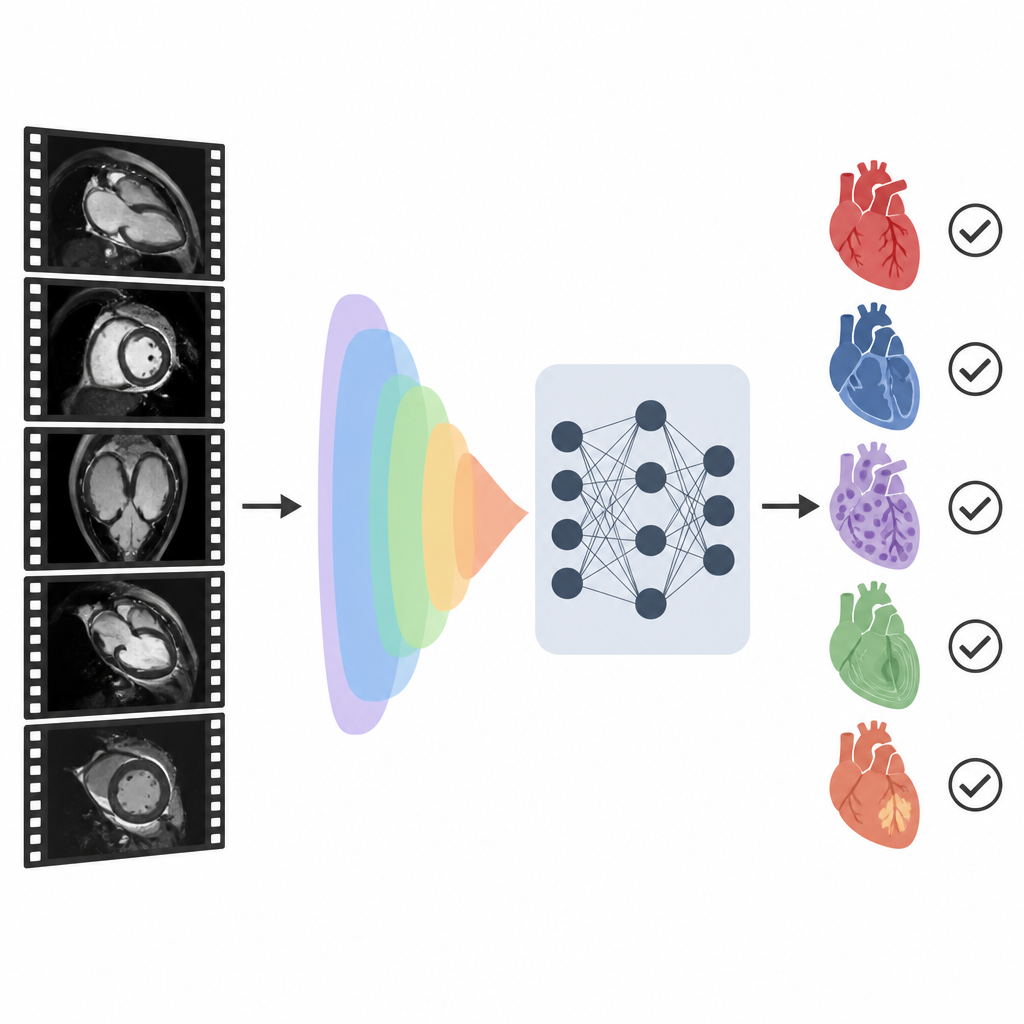
Una nueva manera de emparejar imágenes y palabras
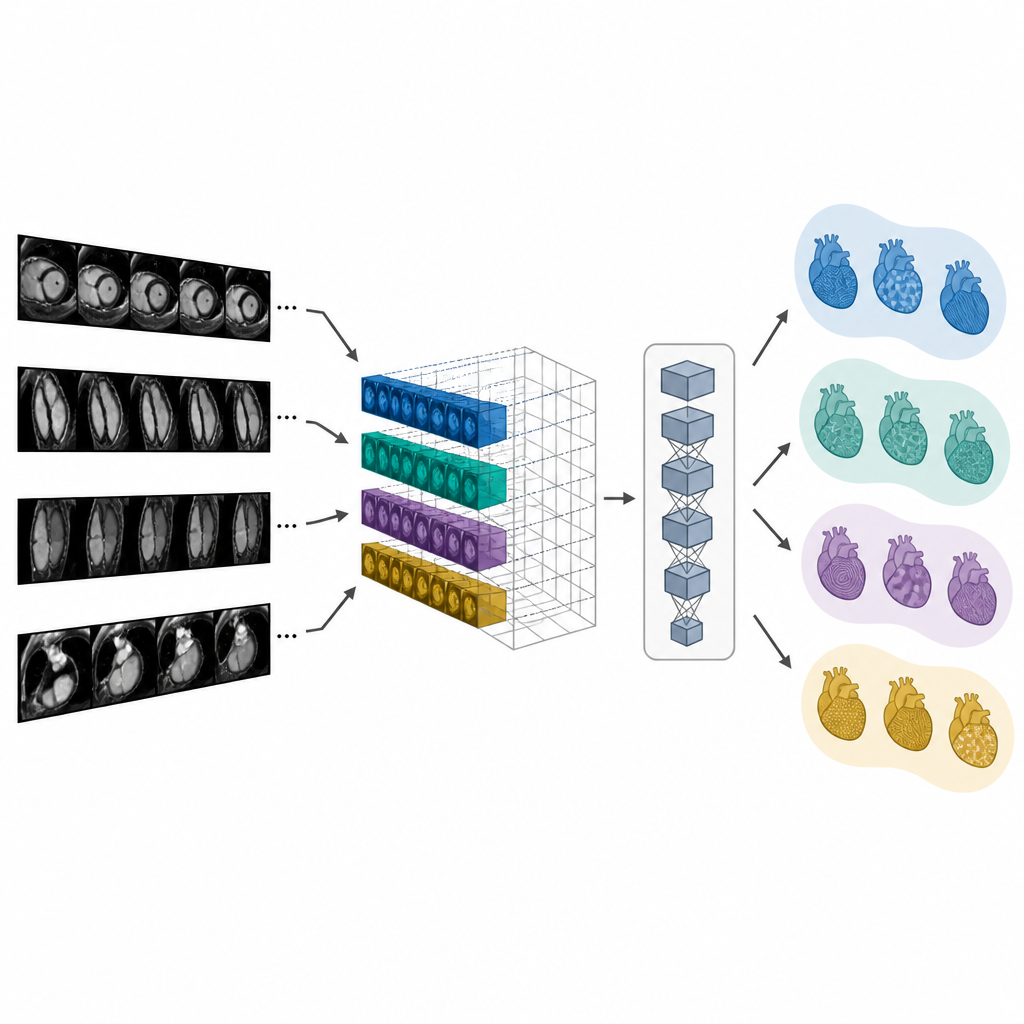
Los investigadores construyeron un sistema llamado CMR-CLIP que conecta las imágenes de resonancia cardíaca con la sección de resumen breve del informe médico. En lugar de tratar cada imagen de forma independiente, consideran todo el examen como si fuera un pequeño vídeo compuesto por muchas vistas cardíacas estándar y técnicas de imagen. Al mismo tiempo, el sistema lee la impresión escrita que describe los hallazgos clave y los diagnósticos. Al entrenar con más de 14.000 exámenes previos y sus informes procedentes de un mismo sistema sanitario, el modelo aprende gradualmente un "lenguaje" compartido que vincula patrones visuales en las imágenes con frases en el texto, sin necesitar contornos dibujados a mano ni etiquetas manuales para cada fotograma.
Aprender a reconocer la enfermedad con casi ninguna enseñanza
Una vez entrenado, CMR-CLIP se probó en tareas clásicas que los cardiólogos afrontan a diario, como detectar una contractilidad débil del corazón, cavidades dilatadas o engrosamiento del músculo cardíaco. En un escenario zero-shot, al modelo solo se le dieron indicaciones cortas y legibles por humanos como "el ventrículo izquierdo está dilatado" y se le pidió decidir si se aplicaban a un nuevo examen. Incluso en estas condiciones, alcanzó una precisión sólida en siete hallazgos comunes y varias enfermedades importantes, incluyendo miocardiopatía hipertrófica y amiloidosis cardíaca. Superó claramente a sistemas generales imagen-texto, mostrando que la RM cardiaca presenta patrones únicos que los modelos genéricos no capturan bien.
Mejorando con solo unos pocos ejemplos
El equipo también probó aprendizaje few-shot, donde el modelo ve solo un puñado de ejemplos etiquetados por condición antes de clasificar casos nuevos. Con conjuntos de entrenamiento diminutos de solo uno, dos o cuatro exámenes por categoría, CMR-CLIP siguió mejorando de forma constante y con frecuencia igualó o superó a otros modelos que habían visto muchos más ejemplos. Por ejemplo, al evaluar la disfunción del corazón izquierdo, el rendimiento pasó de aceptable con un ejemplo a muy alto con 32 ejemplos, y resultados comparables se observaron para la dilatación de cavidades y el engrosamiento del músculo. Esto sugiere que una vez aprendido el espacio imagen-texto compartido, el sistema puede adaptarse a nuevas tareas clínicas con mucha menos data etiquetada de la habitual.
Encontrar exploraciones coincidentes y redactar informes
Porque CMR-CLIP vincula imágenes y palabras en un espacio común, puede recuperar el examen o informe más relevante al recibir ya sea una exploración o una consulta en texto. En pruebas, fue mucho más probable que los modelos de comparación clasifiquen el informe o la exploración coincidente verdadero entre los primeros resultados, incluso cuando los datos procedían de distintos hospitales o escáneres de RM. Los autores usaron entonces las características de imagen aprendidas de dos maneras para ayudar en la generación de informes. Un método simplemente encuentra el caso pasado más similar y reutiliza su impresión. Un segundo método, llamado CMR-TARGET, introduce las características de imagen en un generador de texto que escribe una nueva impresión frase por frase. Este enfoque generativo produjo resúmenes que coincidían más estrechamente con informes clínicos reales según métricas de lenguaje estándar.
Robusto frente a distintos escáneres y detalles de imagen
Los investigadores examinaron cómo las decisiones de diseño afectaban al rendimiento. Incluir tanto imágenes en movimiento "cine" como imágenes con contraste especial que resaltan tejido cicatricial, así como múltiples ángulos de visión del corazón, mejoró claramente la capacidad del sistema para recuperar y clasificar casos. Usar más fotogramas por examen ayudó a capturar cambios sutiles a lo largo del latido, aunque también requirió más potencia de cálculo. El equipo también destacó la importancia de la estabilidad: la representación interna de CMR-CLIP cambió poco cuando los fotogramas se barajaron o se eliminaron parcialmente, lo que indica que se centra en señales relevantes para la enfermedad más que en detalles frágiles. Pruebas entre distintas marcas de escáner y potencias magnéticas mostraron que la precisión se mantuvo relativamente estable, lo que sugiere que el modelo puede generalizar más allá del centro donde se entrenó.
Qué podría significar esto para la atención cardíaca
Para un no especialista, el mensaje principal es que los ordenadores pueden ahora aprender conceptos ricos y reutilizables a partir de exámenes de RM cardiaca y sus interpretaciones escritas, incluso sin etiquetas detalladas en cada imagen. CMR-CLIP actúa como un modelo fundacional adaptado a la RM cardiaca: puede apoyar el diagnóstico de varias enfermedades cardíacas importantes, ayudar a recuperar casos pasados similares y redactar informes estructurados o en texto libre que los médicos pueden editar. Aunque no sustituye a los lectores expertos y sigue dependiendo de la calidad y variedad de sus datos de entrenamiento, este enfoque podría reducir el tiempo de lectura, hacer los resultados más consistentes entre hospitales y, en última instancia, ayudar a extender la atención cardíaca avanzada basada en RM a más pacientes.
Cita: Nakashima, M., Qiu, J., Huang, P. et al. Contrastive language image pretraining for a cardiac magnetic resonance image embedding with zero-shot capabilities. Nat Commun 17, 4416 (2026). https://doi.org/10.1038/s41467-026-73022-2
Palabras clave: resonancia magnética cardíaca, IA médica, modelo visión-lenguaje, miocardiopatía, apoyo a la decisión clínica