Clear Sky Science · fr
Pré-entraînement contrastif langage-image pour un encodage d’IRM cardiaque avec capacités zero-shot
Pourquoi apprendre aux ordinateurs à lire les examens cardiaques est important
Les IRM cardiaques peuvent révéler des signes subtils de maladie bien avant l’apparition de symptômes évidents, mais chaque examen comprend des centaines d’images qui prennent beaucoup de temps aux spécialistes pour être lues. Cette étude examine si un système d’intelligence artificielle peut apprendre à « comprendre » ces examens complexes et leurs comptes rendus écrits afin d’aider les médecins à trier les cas, reconnaître des motifs de maladie et même rédiger des rapports, le tout sans qu’on lui indique explicitement ce que montre chaque image.
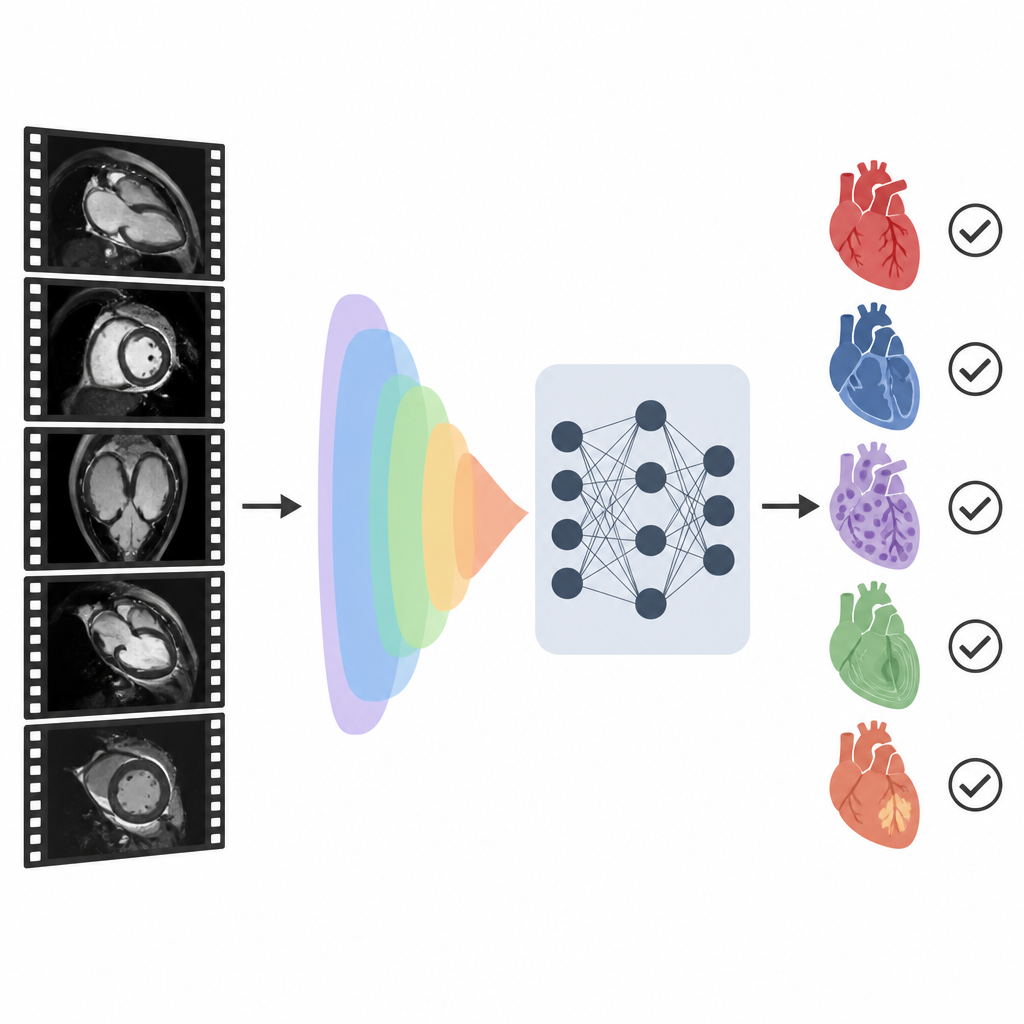
Une nouvelle façon d’apparier images et mots
Les chercheurs ont construit un système nommé CMR-CLIP qui connecte les images d’IRM cardiaque à la section synthétique courte du compte rendu du médecin. Plutôt que de traiter chaque image individuellement, ils considèrent un examen entier comme une courte vidéo composée de nombreuses vues cardiaques standard et de techniques d’imagerie variées. Dans le même temps, le système lit l’impression écrite qui décrit les principaux constats et diagnostics. En s’entraînant sur plus de 14 000 examens passés et leurs comptes rendus provenant d’un même système de santé, le modèle apprend progressivement un « langage » partagé qui relie les motifs visuels des images aux expressions du texte, sans nécessiter de contours dessinés à la main ni d’étiquettes manuelles pour chaque image.
Apprendre à reconnaître la maladie avec presque aucun apprentissage supervisé
Une fois entraîné, CMR-CLIP a été testé sur des tâches classiques que rencontrent quotidiennement les cardiologues, comme détecter une faible fonction de pompage, des cavités dilatées ou un épaississement du muscle cardiaque. En mode zero-shot, le modèle n’a reçu que de courtes consignes lisibles par un humain comme « ventricule gauche dilaté » et devait décider si elles s’appliquaient à un nouvel examen. Même dans ces conditions, il a atteint une précision solide sur sept constatations courantes et plusieurs maladies majeures, y compris la cardiomyopathie hypertrophique et l’amylose cardiaque. Il a nettement surpassé des systèmes image–texte généraux, montrant que l’IRM cardiaque présente des motifs uniques que les modèles génériques captent mal.
De meilleures performances avec seulement quelques exemples
L’équipe a également testé l’apprentissage few-shot, où le modèle ne voit qu’une poignée d’exemples étiquetés par condition avant d’être invité à classer de nouveaux cas. Avec des jeux d’entraînement minuscules contenant aussi peu qu’un, deux ou quatre examens par catégorie, CMR-CLIP s’est malgré tout amélioré de façon régulière et a souvent égalé ou dépassé d’autres modèles qui avaient vu beaucoup plus d’exemples. Par exemple, pour juger d’une dysfonction cardiaque gauche, la performance est passée d’acceptable avec un seul exemple à très élevée avec 32 exemples, et des résultats comparables ont été observés pour la dilatation des cavités et l’épaississement du muscle. Cela suggère qu’une fois l’espace image–texte partagé appris, le système peut s’adapter à de nouvelles tâches cliniques avec beaucoup moins de données étiquetées que d’habitude.
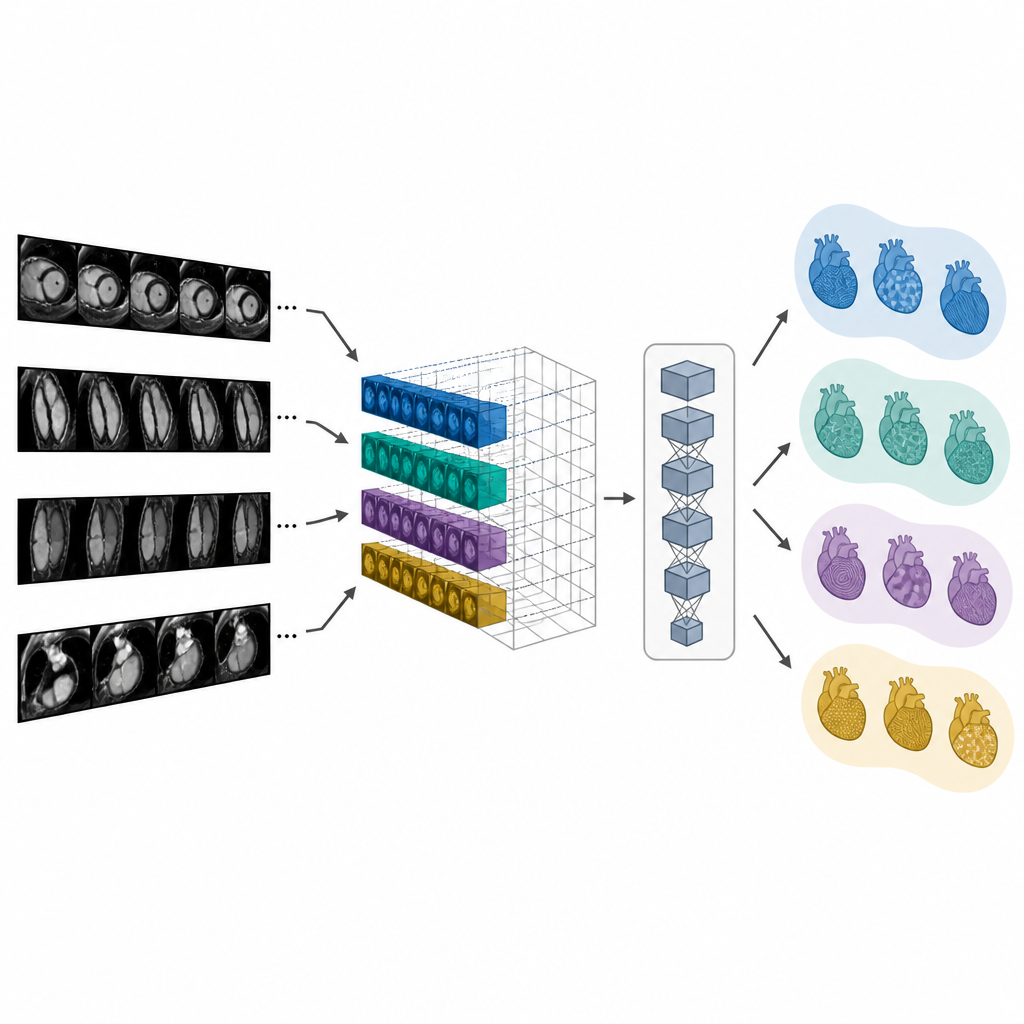
Retrouver des examens similaires et rédiger des comptes rendus
Parce que CMR-CLIP relie images et mots dans un espace commun, il peut retrouver l’examen ou le compte rendu le plus pertinent lorsqu’on lui fournit soit une image soit une requête textuelle. Dans les tests, il classait beaucoup plus souvent que les modèles de comparaison le vrai compte rendu ou l’examen correspondant parmi les premiers résultats, même lorsque les données provenaient d’hôpitaux ou d’appareils IRM différents. Les auteurs ont ensuite utilisé les caractéristiques d’image apprises de deux manières pour aider à la rédaction des comptes rendus. Une méthode retrouve simplement le cas passé le plus similaire et réutilise son impression. Une seconde méthode, appelée CMR-TARGET, alimente les caractéristiques d’image dans un générateur de texte qui écrit une nouvelle impression phrase par phrase. Cette approche générative a produit des résumés qui correspondaient davantage aux comptes rendus cliniques réels selon des métriques de langage standard.
Robuste face aux marques d’appareils et aux détails d’imagerie
Les chercheurs ont examiné comment les choix de conception affectaient les performances. L’inclusion à la fois des images « ciné » en mouvement et des images de contraste spéciales qui mettent en évidence les zones de cicatrice, ainsi que de multiples angles de vue du cœur, a clairement amélioré la capacité du système à retrouver et à classifier les cas. L’utilisation de plus d’images par examen a aidé à capter des changements subtils au cours du battement cardiaque, bien que cela nécessite aussi plus de puissance de calcul. L’équipe a également souligné l’importance de la stabilité : la représentation interne de CMR-CLIP change peu lorsque les images sont mélangées ou partiellement retirées, ce qui indique qu’il se concentre sur des signaux pertinents pour la maladie plutôt que sur des détails fragiles. Des tests sur des marques d’appareils et des intensités de champ magnétique différentes ont montré que la précision restait relativement stable, suggérant que le modèle peut se généraliser au-delà du centre où il a été entraîné.
Ce que cela pourrait signifier pour les soins cardiaques
Pour un non-spécialiste, le message principal est que les ordinateurs peuvent désormais apprendre des concepts riches et réutilisables à partir d’examens IRM cardiaques et de leurs interprétations écrites, même sans étiquettes détaillées sur chaque image. CMR-CLIP agit comme un modèle fondation adapté à l’IRM cardiaque : il peut soutenir le diagnostic de plusieurs maladies cardiaques importantes, aider à retrouver des cas passés similaires et rédiger des comptes rendus structurés ou en texte libre que les médecins peuvent modifier. Bien qu’il ne remplace pas les lecteurs experts et dépende encore de la qualité et de la diversité de ses données d’entraînement, cette approche pourrait réduire le temps de lecture, uniformiser les résultats entre établissements et, à terme, aider à étendre des soins cardiaques avancés basés sur l’IRM à un plus grand nombre de patients.
Citation: Nakashima, M., Qiu, J., Huang, P. et al. Contrastive language image pretraining for a cardiac magnetic resonance image embedding with zero-shot capabilities. Nat Commun 17, 4416 (2026). https://doi.org/10.1038/s41467-026-73022-2
Mots-clés: IRM cardiaque, IA médicale, modèle vision-langage, cardiomyopathie, aide à la décision clinique