Clear Sky Science · pt
Pré-treinamento contraste linguagem-imagem para um embedding de ressonância magnética cardíaca com capacidades zero-shot
Por que ensinar computadores a ler exames cardíacos importa
Exames de RM do coração podem revelar sinais sutis de doença muito antes de os sintomas se tornarem óbvios, mas cada exame inclui centenas de imagens que levam especialistas muito tempo para analisar. Este estudo investiga se um sistema de inteligência artificial pode aprender a “entender” esses exames complexos e seus relatórios escritos para ajudar médicos a organizar casos, reconhecer padrões de doença e até redigir laudos, tudo sem receber instruções explícitas sobre o que cada imagem mostra.
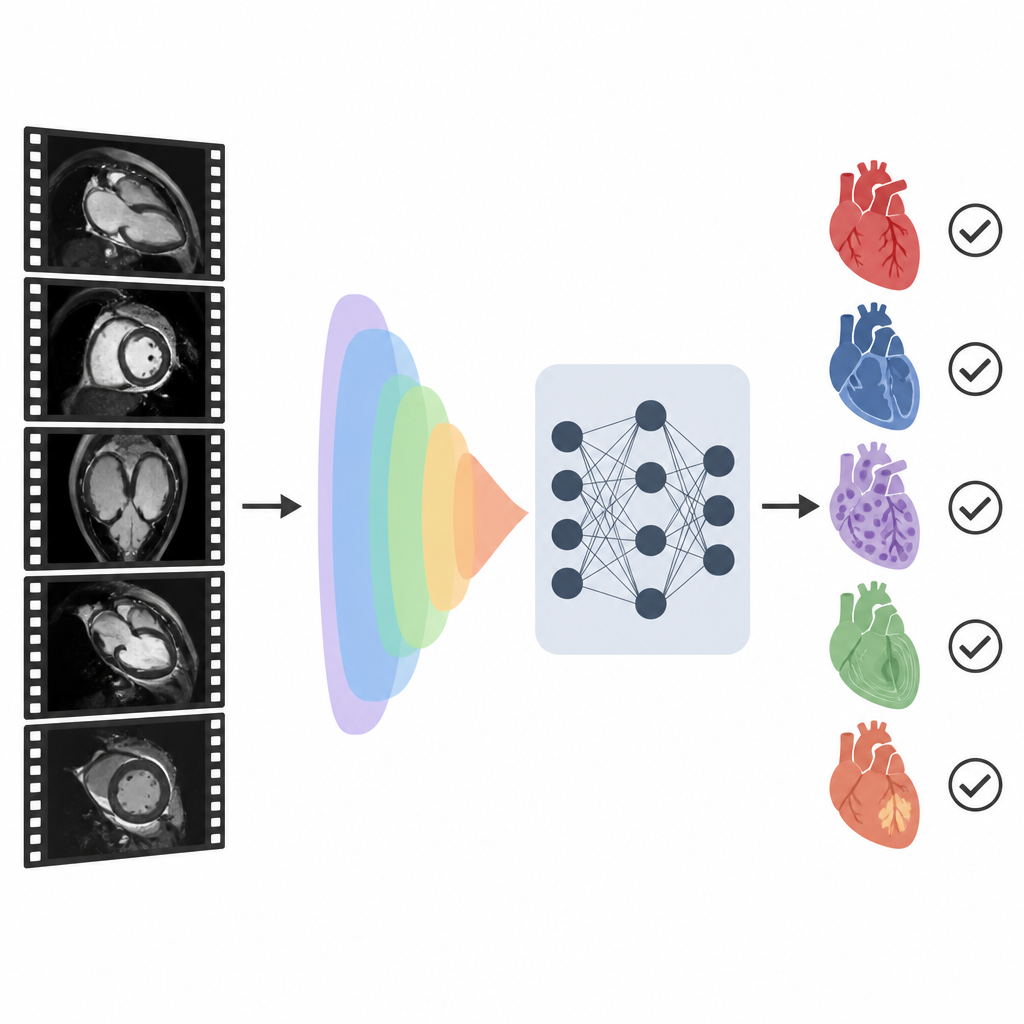
Uma nova forma de parear imagens e palavras
Os pesquisadores construíram um sistema chamado CMR-CLIP que conecta imagens de RM cardíaca com a seção de resumo curto do laudo médico. Em vez de tratar cada imagem isoladamente, eles consideram todo o exame como se fosse um pequeno vídeo composto por muitas vistas padrão do coração e técnicas de imagem. Ao mesmo tempo, o sistema lê a impressão escrita que descreve achados e diagnósticos principais. Ao treinar com mais de 14.000 exames passados e seus laudos de um sistema de saúde, o modelo aprende gradualmente uma “linguagem” comum que vincula padrões visuais nas imagens a expressões no texto, sem precisar de contornos desenhados à mão ou rótulos manuais para cada quadro.
Aprendendo a reconhecer doenças com quase nenhum ensinamento
Uma vez treinado, o CMR-CLIP foi testado em tarefas clássicas que cardiologistas enfrentam diariamente, como detectar fraqueza da contração do coração, dilatação de câmaras ou espessamento do músculo cardíaco. Em um cenário zero-shot, o modelo recebeu apenas prompts curtos e legíveis por humanos, como “ventrículo esquerdo dilatado”, e teve que decidir se isso se aplicava a um novo exame. Mesmo nessas condições, alcançou precisão sólida em sete achados comuns e várias doenças importantes, incluindo cardiomiopatia hipertrófica e amiloidose cardíaca. Superou claramente sistemas genéricos imagem–texto, mostrando que a RM cardíaca tem padrões únicos que modelos genéricos não capturam bem.
Melhorando com apenas alguns exemplos
O grupo também testou aprendizado few-shot, em que o modelo vê apenas um punhado de exemplos rotulados por condição antes de classificar novos casos. Usando conjuntos de treinamento minúsculos, de apenas um, dois ou quatro exames por categoria, o CMR-CLIP ainda melhorou de forma estável e frequentemente igualou ou superou outros modelos que viram muito mais exemplos. Por exemplo, ao avaliar disfunção do lado esquerdo do coração, o desempenho subiu de razoável com um exemplo para muito alto com 32 exemplos, e resultados comparáveis foram observados para dilatação de câmaras e espessamento do músculo. Isso sugere que, uma vez aprendido o espaço imagem–texto compartilhado, o sistema pode se adaptar a novas tarefas clínicas com muito menos dados rotulados do que o habitual.
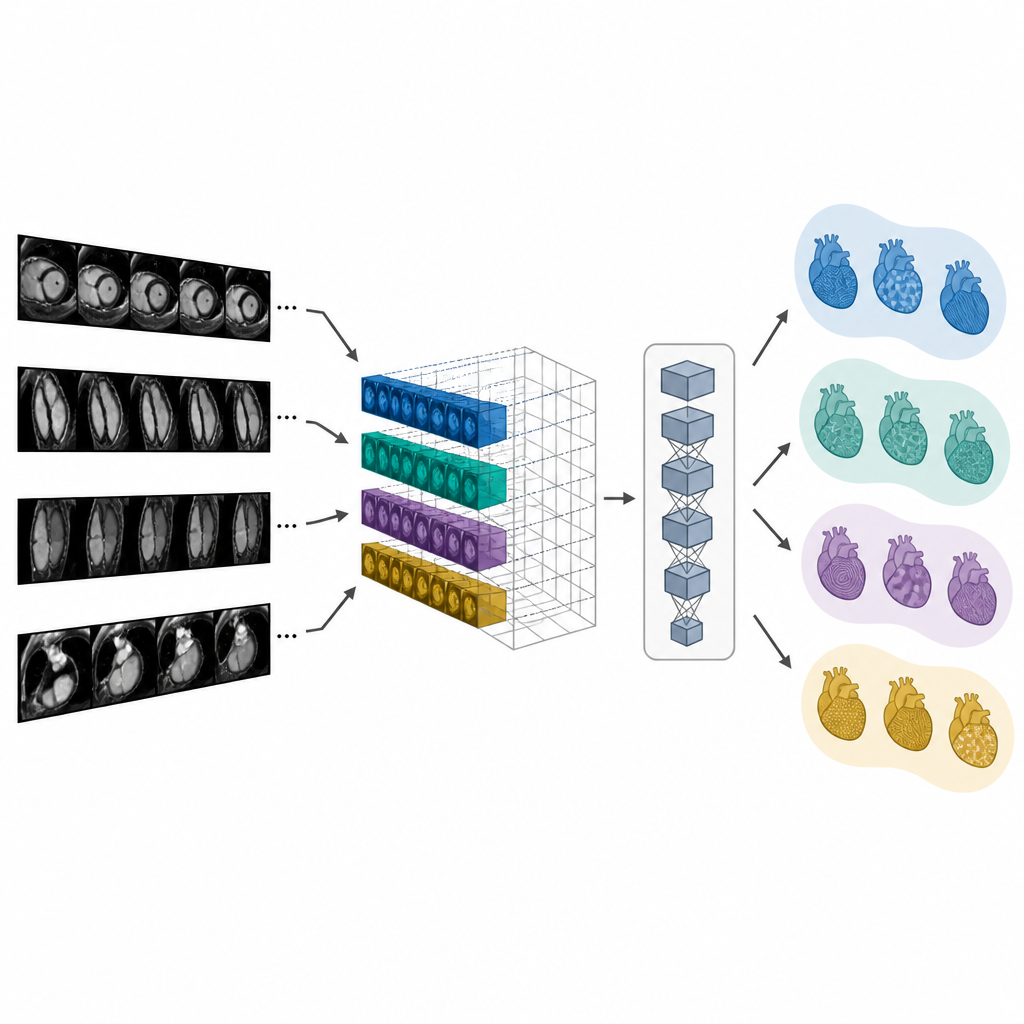
Encontrando exames correspondentes e redigindo laudos
Como o CMR-CLIP vincula imagens e palavras em um espaço comum, ele pode recuperar o exame ou laudo mais relevante quando recebe uma imagem ou uma consulta em texto. Em testes, foi muito mais provável do que modelos comparativos classificar o verdadeiro laudo ou exame correspondente entre os primeiros resultados, mesmo quando os dados vinham de hospitais ou aparelhos de RM diferentes. Os autores então usaram as características de imagem aprendidas de duas maneiras para auxiliar na elaboração de laudos. Um método simplesmente encontra o caso passado mais semelhante e reaproveita sua impressão. Um segundo método, chamado CMR-TARGET, alimenta as características de imagem em um gerador de texto que escreve uma nova impressão frase por frase. Essa abordagem generativa produziu resumos que combinavam mais de perto com laudos clínicos reais segundo métricas padrão de linguagem.
Robusto entre aparelhos e detalhes de imagem
Os pesquisadores examinaram como escolhas de projeto afetaram o desempenho. Incluir tanto imagens em movimento “cine” quanto imagens de contraste especiais que destacam tecido cicatricial, bem como múltiplos ângulos de visualização do coração, melhorou claramente a capacidade do sistema de recuperar e classificar casos. Usar mais quadros por exame ajudou a captar mudanças sutis ao longo do ciclo cardíaco, embora também exigisse mais poder computacional. A equipe também ressaltou a importância da estabilidade: a representação interna do CMR-CLIP mudou pouco quando quadros foram embaralhados ou parcialmente removidos, indicando que foca em sinais relevantes para a doença em vez de detalhes frágeis. Testes entre marcas diferentes de aparelhos e intensidades magnéticas mostraram que a precisão se manteve relativamente estável, sugerindo que o modelo pode generalizar além do centro onde foi treinado.
O que isso pode significar para o cuidado cardíaco
Para um não especialista, a mensagem principal é que computadores agora podem aprender conceitos ricos e reutilizáveis a partir de exames de RM cardíaca e suas interpretações escritas, mesmo sem rótulos detalhados em cada imagem. O CMR-CLIP age como um modelo base adaptado à RM cardíaca: pode apoiar o diagnóstico de várias doenças cardíacas importantes, ajudar a recuperar casos passados semelhantes e redigir laudos estruturados ou em texto livre que os médicos podem editar. Embora não substitua leitores especialistas e ainda dependa da qualidade e variedade dos dados de treinamento, essa abordagem pode reduzir o tempo de leitura, tornar os resultados mais consistentes entre hospitais e, eventualmente, ajudar a ampliar o acesso a cuidados cardíacos avançados baseados em RM para mais pacientes.
Citação: Nakashima, M., Qiu, J., Huang, P. et al. Contrastive language image pretraining for a cardiac magnetic resonance image embedding with zero-shot capabilities. Nat Commun 17, 4416 (2026). https://doi.org/10.1038/s41467-026-73022-2
Palavras-chave: RM cardíaca, IA médica, modelo visão-linguagem, cardiomiopatia, apoio à decisão clínica