Clear Sky Science · zh
利用加权嵌入与Transformer架构提高作物复杂性状的表型预测
更聪明的育种造就更优的作物
为了养活不断增长的人口,需要培育产量更高、耐逆境、更具营养性的作物。然而,决定哪些品系进行杂交长期以来依赖耗时的田间试验与反复试错。本研究提出了一种从DNA直接学习以预测植物表现的新型人工智能模型,承诺为大豆、玉米、水稻和小麦等作物带来更快、更精确的育种决策。
从DNA编码到可见性状
每株植物都携带数百万个微小的DNA差异,它们共同决定了油含量、产量或抗旱性等性状。传统统计工具可以利用这些信息,但在数据体量巨大、遗传效应分散且微弱时往往力不从心。作者通过把长片段的DNA视为一种复杂语言来应对这一挑战,并采用能够更深层次“阅读”这种语言的模型,不仅捕捉明显信号,还能识别那些累积起来在田间产生重大差异的众多小变异。
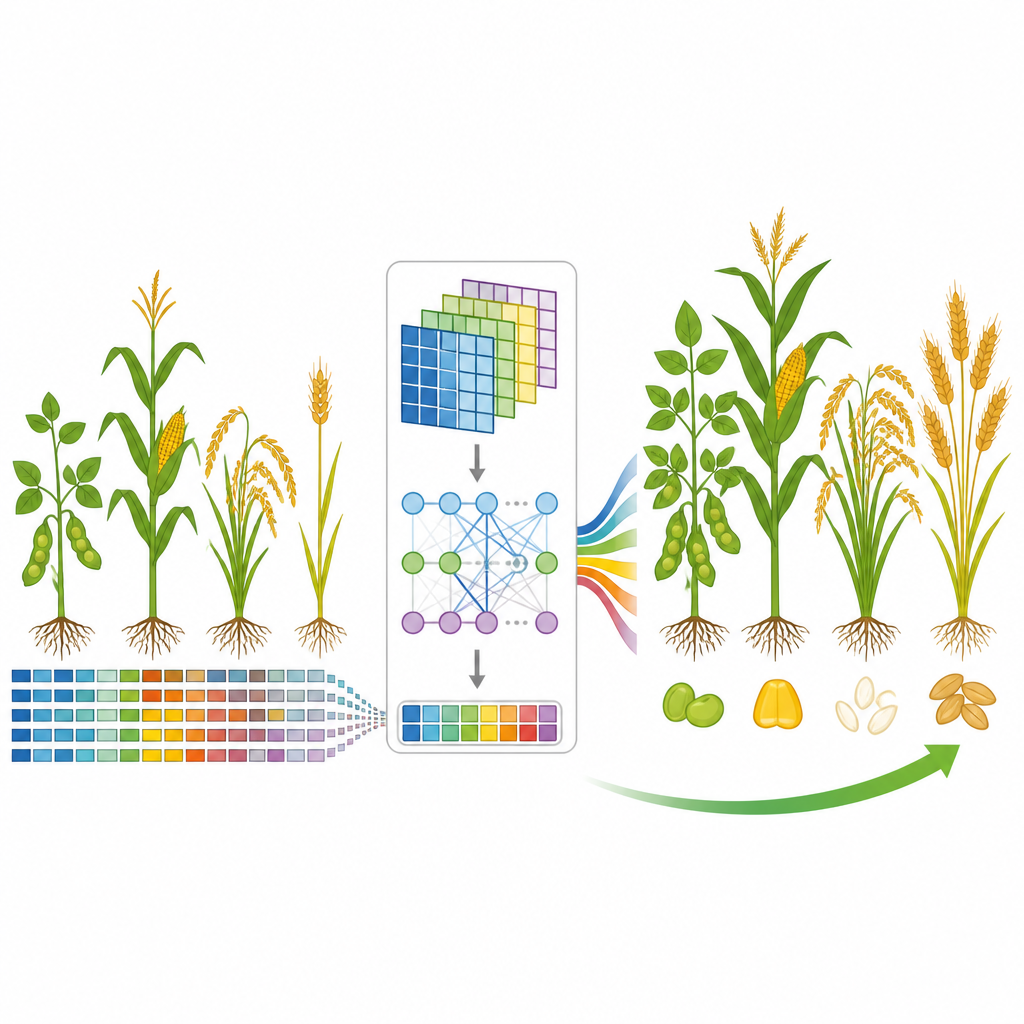
能听见重要遗传信号的新模型
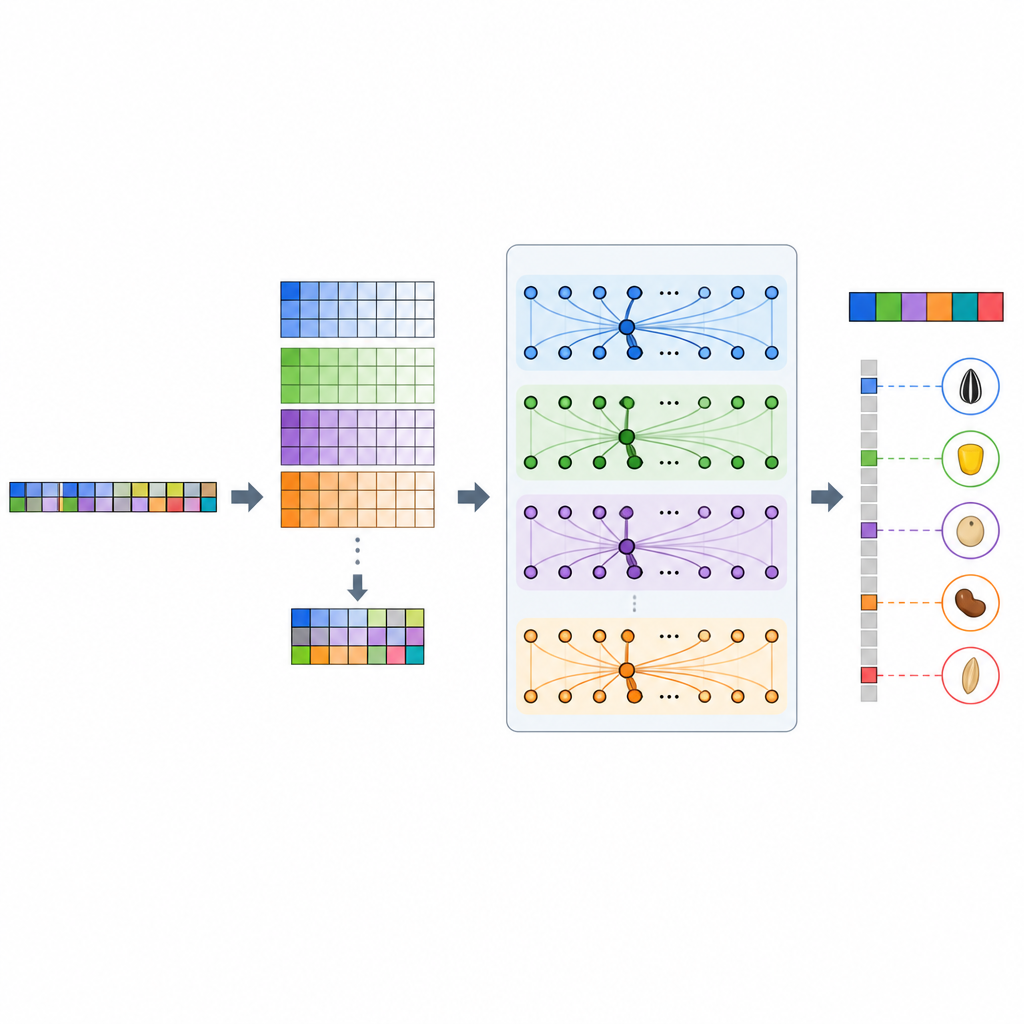
团队开发了GP-WAITER,一种结合两种思想的深度学习框架。首先,它利用全基因组关联研究(GWAS)的结果,这些结果会标识与性状统计相关的DNA位点,为每个遗传标记赋予一个反映其信息量的数值“权重”。其次,它将这些加权标记输入到一个混合系统中,该系统结合了擅长检测局部模式的卷积层与在语言模型中以捕捉远程关系见长的Transformer模块。通过将超长DNA序列切分为可处理的片段并对关键区域分配注意力,GP-WAITER能够追踪远距遗传变异如何协同作用影响性状。
在多种作物上实现更高精度与更快计算
为测试GP-WAITER,研究人员汇集了六个大型数据集,涵盖数千条大豆、玉米、水稻和小麦品系,以及多种营养和农艺性状。他们将新模型与七种主流预测工具比较,包括经典线性方法、如梯度提升的机器学习方法,以及其他深度网络和基于Transformer的模型。在所有数据集中,GP-WAITER持续产生更准确的预测,在部分情况下精度提升约四分之三,预测误差最多减少78%。在一个包含数十万DNA标记的超大型大豆数据集上,它的训练速度也明显快于其他深度模型且占用更少的显卡内存,表明它能够高效处理真实育种规模的数据。
为遗传学中的AI“黑箱”打开一扇窗
深度学习常被担忧为“黑箱”,让生物学家难以理解预测背后的原因。作者通过使用SHAP(一种流行的可解释AI方法)来测量每个DNA变异对模型预测的贡献,从而应对了这一问题。他们发现GP-WAITER经常突出显示位于已知会影响大豆种子中维生素E、类胡萝卜素和异黄酮等关键化合物的基因或调控区的变异。在某些情况下,模型还指出了标准关联检验未能发现的有希望变异,这表明它能够恢复对营养和产量重要的强信号与微弱信号。
这对未来作物育种意味着什么
通过将加权遗传信息与强大的基于注意力的架构相结合,GP-WAITER提供了一种实用方式来更准确地预测植物性状,同时仍能清晰地联系到底层生物学。对育种者而言,这意味着他们可以仅凭DNA数据对成千上万的候选品系进行排序,将田间试验聚焦于最有前景的杂交组合,并更容易定位值得在精准育种中靶向的基因区。对公众而言,这项工作展示了先进AI方法如何帮助更快提供更优作物,从而支持更具韧性和营养性的食品系统,而无需在每个环境中测试每一株植物。
引用: Li, J., Yu, L., Li, M. et al. Leveraging weighted embedding and Transformer architecture to improve phenotype prediction of complex traits for crops. Nat Commun 17, 4427 (2026). https://doi.org/10.1038/s41467-026-71035-5
关键词: 基因组预测, 作物育种, Transformer模型, 大豆遗传学, 农业中的机器学习