Clear Sky Science · en
Leveraging weighted embedding and Transformer architecture to improve phenotype prediction of complex traits for crops
Smarter breeding for better crops
Feeding a growing world means breeding crops that yield more, tolerate stress, and pack better nutrition. Yet deciding which plant lines to cross has long relied on slow, trial-and-error field testing. This study introduces a new artificial intelligence model that learns directly from DNA to forecast how a plant will perform, promising faster, more precise breeding decisions for crops like soybean, maize, rice, and wheat.
From DNA code to visible traits
Every plant carries millions of tiny DNA differences that together shape traits such as oil content, yield, or drought tolerance. Traditional statistical tools can use this information, but they struggle when the data are huge and the genetic effects are subtle and spread across the whole genome. The authors tackle this challenge by treating long stretches of DNA like a complex language and using a model that can read this language more deeply, noticing not only obvious signals but also the many small variants that quietly add up to big differences in the field.
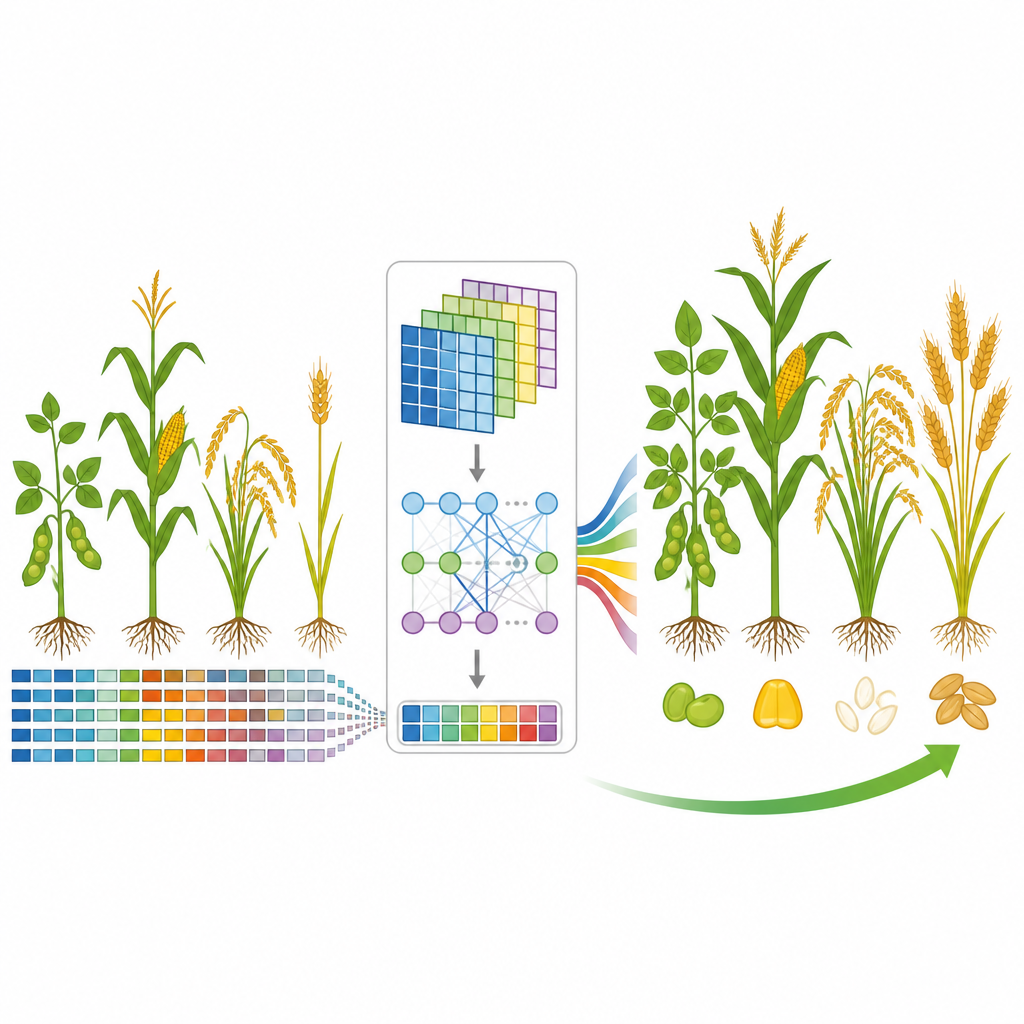
A new model that listens to important genetic signals
The team developed GP-WAITER, a deep learning framework that combines two ideas. First, it uses results from genome-wide association studies, which flag DNA sites statistically linked to traits, to give each genetic marker a numerical “weight” reflecting how informative it might be. Second, it feeds these weighted markers into a hybrid system that joins convolutional layers, good at detecting local patterns, with a Transformer module, well known in language models for capturing long-range relationships. By breaking ultra-long DNA sequences into manageable pieces and assigning attention to influential regions, GP-WAITER can track how distant genetic variants work together to shape a trait.
Higher accuracy and faster computation across many crops
To test GP-WAITER, the researchers assembled six large datasets covering thousands of lines of soybean, maize, rice, and wheat, and a wide range of nutritional and agronomic traits. They compared the new model with seven leading prediction tools, including classic linear methods, machine learning approaches such as gradient boosting, and other deep networks and Transformer-based models. Across all datasets, GP-WAITER consistently produced more accurate predictions, in some cases improving accuracy by up to about three-quarters and cutting prediction error by as much as 78 percent. On a very large soybean dataset with hundreds of thousands of DNA markers, it also trained substantially faster than competing deep models while using less graphics-card memory, showing that it can handle real-world breeding-scale data efficiently.
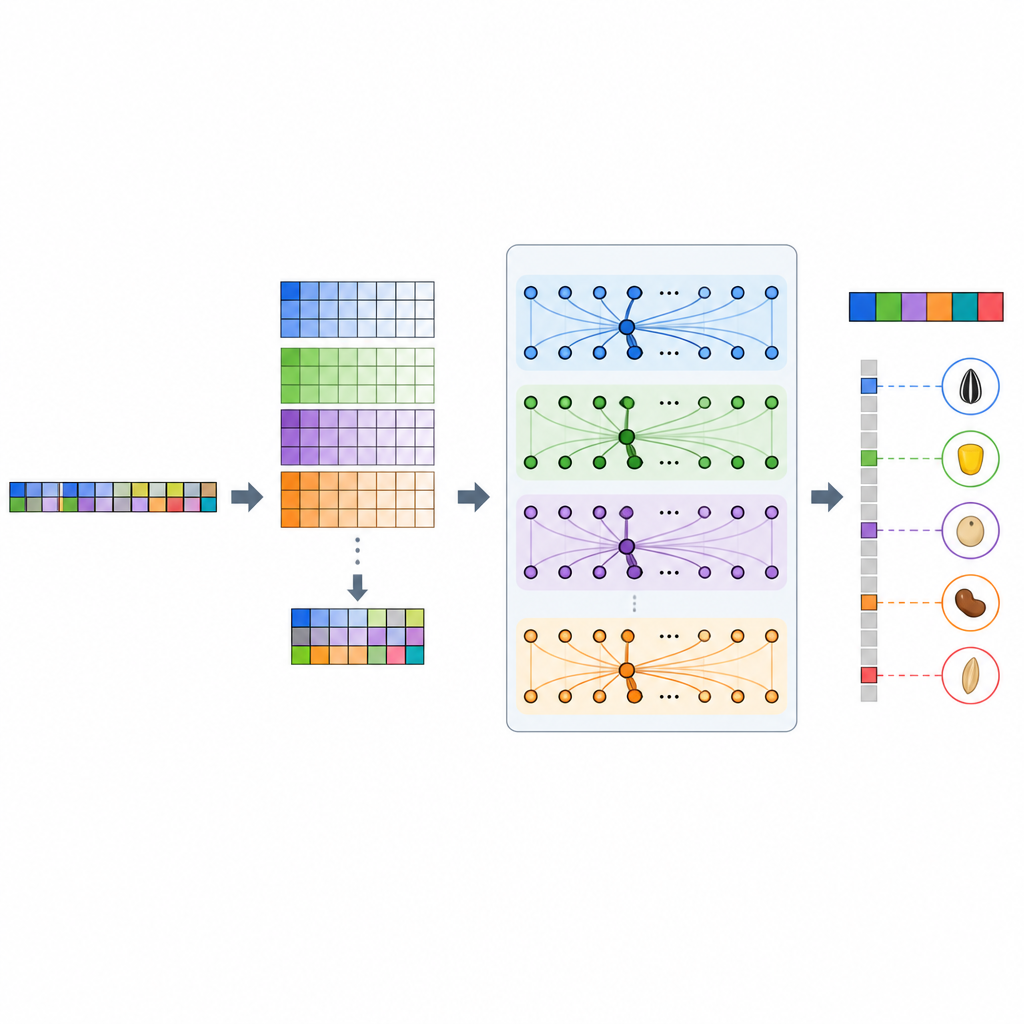
Opening the black box of AI in genetics
A common worry with deep learning is that it behaves like a black box, making it hard for biologists to see why a prediction is made. The authors addressed this by using SHAP, a popular explainable AI method, to measure the contribution of each DNA variant to the model’s predictions. They found that GP-WAITER frequently highlighted variants located in genes or regulatory regions already known to influence key compounds such as vitamin E, carotenoids, and isoflavones in soybean seeds. In some cases, the model pointed to promising variants that standard association tests had missed, suggesting it can recover both strong and subtle genetic signals that matter for nutrition and yield.
What this means for future crop breeding
By combining weighted genetic information with a powerful attention-based architecture, GP-WAITER offers a practical way to predict plant traits more accurately while still keeping a clear link back to the underlying biology. For breeders, this means they can rank thousands of candidate lines using DNA data alone, focus field trials on the most promising crosses, and more easily pinpoint genetic regions worth targeting in precision breeding. For the wider public, the work shows how advanced AI methods can help deliver better crops faster, supporting more resilient and nutritious food systems without needing to test every plant in every environment.
Citation: Li, J., Yu, L., Li, M. et al. Leveraging weighted embedding and Transformer architecture to improve phenotype prediction of complex traits for crops. Nat Commun 17, 4427 (2026). https://doi.org/10.1038/s41467-026-71035-5
Keywords: genomic prediction, crop breeding, transformer model, soybean genetics, machine learning in agriculture