Clear Sky Science · nl
Gewogen embedding en Transformer-architectuur benutten om fenotypevoorspelling van complexe eigenschappen bij gewassen te verbeteren
Slimmer veredelen voor betere gewassen
Om een groeiende wereld te voeden moeten gewassen worden veredeld die hogere opbrengsten leveren, bestand zijn tegen stress en beter van voedingswaarde zijn. Toch berust de keuze welke plantlijnen te kruisen vaak op trage, oefening-en-fout veldtests. Deze studie introduceert een nieuw kunstmatig-intelligentie-model dat rechtstreeks uit DNA leert voorspellen hoe een plant zal presteren, en belooft snellere en preciezere veredelingsbeslissingen voor gewassen zoals soja, maïs, rijst en tarwe.
Van DNA-code naar zichtbare eigenschappen
Elke plant draagt miljoenen kleine DNA-verschillen die gezamenlijk eigenschappen bepalen zoals oliegehalte, opbrengst of droogtetolerantie. Traditionele statistische hulpmiddelen kunnen deze informatie gebruiken, maar ze lopen vast wanneer de data enorm zijn en de genetische effecten subtiel en over het hele genoom verspreid zijn. De auteurs pakken deze uitdaging aan door lange stukken DNA te behandelen als een complexe taal en een model te gebruiken dat deze taal dieper kan lezen, waarbij het niet alleen duidelijke signalen opmerkt maar ook de vele kleine varianten die stilletjes optellen tot grote verschillen in het veld.
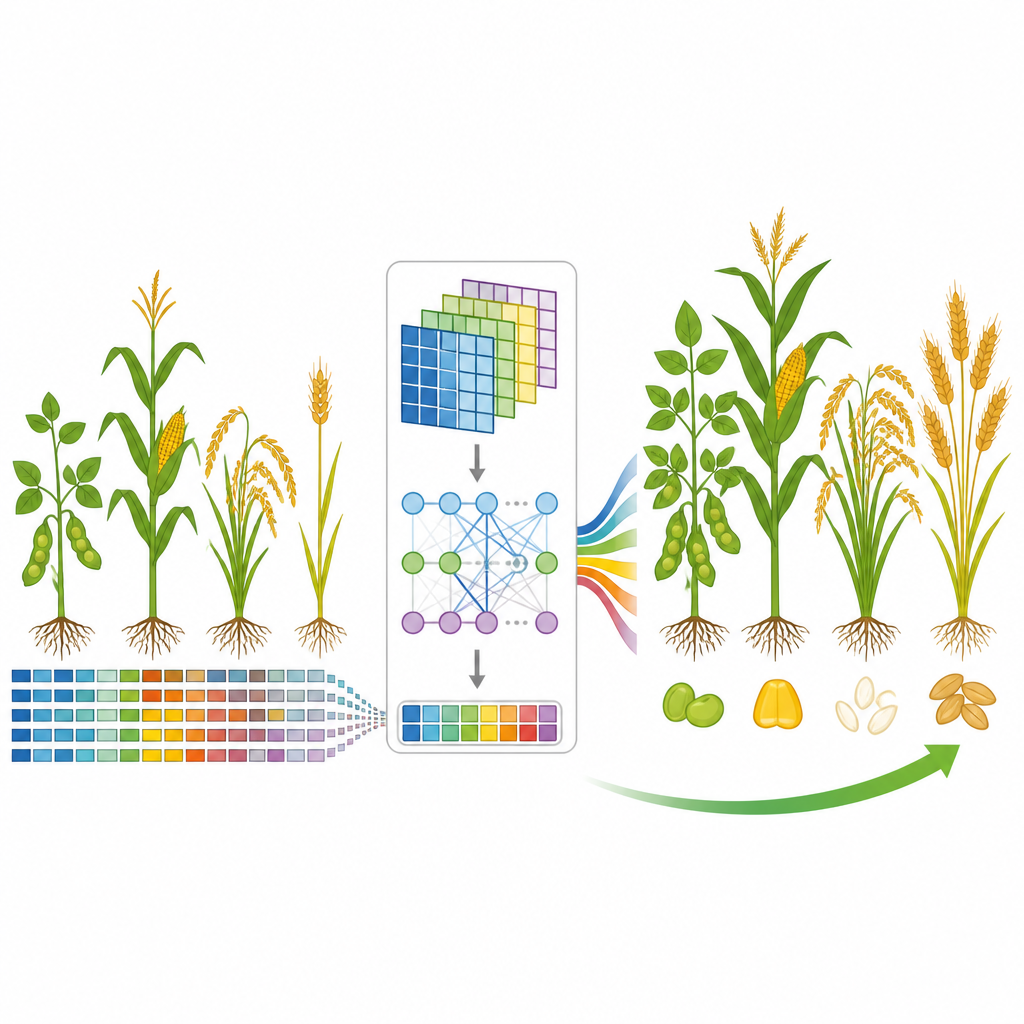
Een nieuw model dat luistert naar belangrijke genetische signalen
Het team ontwikkelde GP-WAITER, een deep-learningraamwerk dat twee ideeën combineert. Ten eerste gebruikt het resultaten uit genome-wide association studies, die DNA-locaties aanwijzen die statistisch aan eigenschappen zijn gekoppeld, om elke genetische marker een numerisch “gewicht” te geven dat reflecteert hoe informatief die kan zijn. Ten tweede voert het deze gewogen markers in een hybride systeem dat convolutionele lagen, goed in het detecteren van lokale patronen, combineert met een Transformer-module, bekend uit taalmodellen om langafstandrelaties vast te leggen. Door ultralange DNA-sequenties op te delen in hanteerbare stukken en aandacht te geven aan invloedrijke regio’s, kan GP-WAITER volgen hoe verre genetische varianten samenwerken om een eigenschap te vormen.
Hogere nauwkeurigheid en snellere berekening voor meerdere gewassen
Om GP-WAITER te testen verzamelden de onderzoekers zes grote datasets die duizenden lijnen van soja, maïs, rijst en tarwe besloegen, en een breed scala aan nutritionele en agronomische eigenschappen. Ze vergeleken het nieuwe model met zeven toonaangevende voorspellingsinstrumenten, waaronder klassieke lineaire methoden, machine-learningbenaderingen zoals gradient boosting, en andere diepe netwerken en op Transformers gebaseerde modellen. Over alle datasets produceerde GP-WAITER consequent accuratere voorspellingen; in sommige gevallen verbeterde de nauwkeurigheid met tot ongeveer driekwart en verminderde de voorspellingsfout met maximaal 78 procent. Op een zeer grote sojadataset met honderdduizenden DNA-markers trainde het ook substantieel sneller dan concurrerende diepe modellen en gebruikte het minder grafische geheugen, wat aantoont dat het efficiënt met gegevens op veredelingsschaal uit de praktijk kan omgaan.
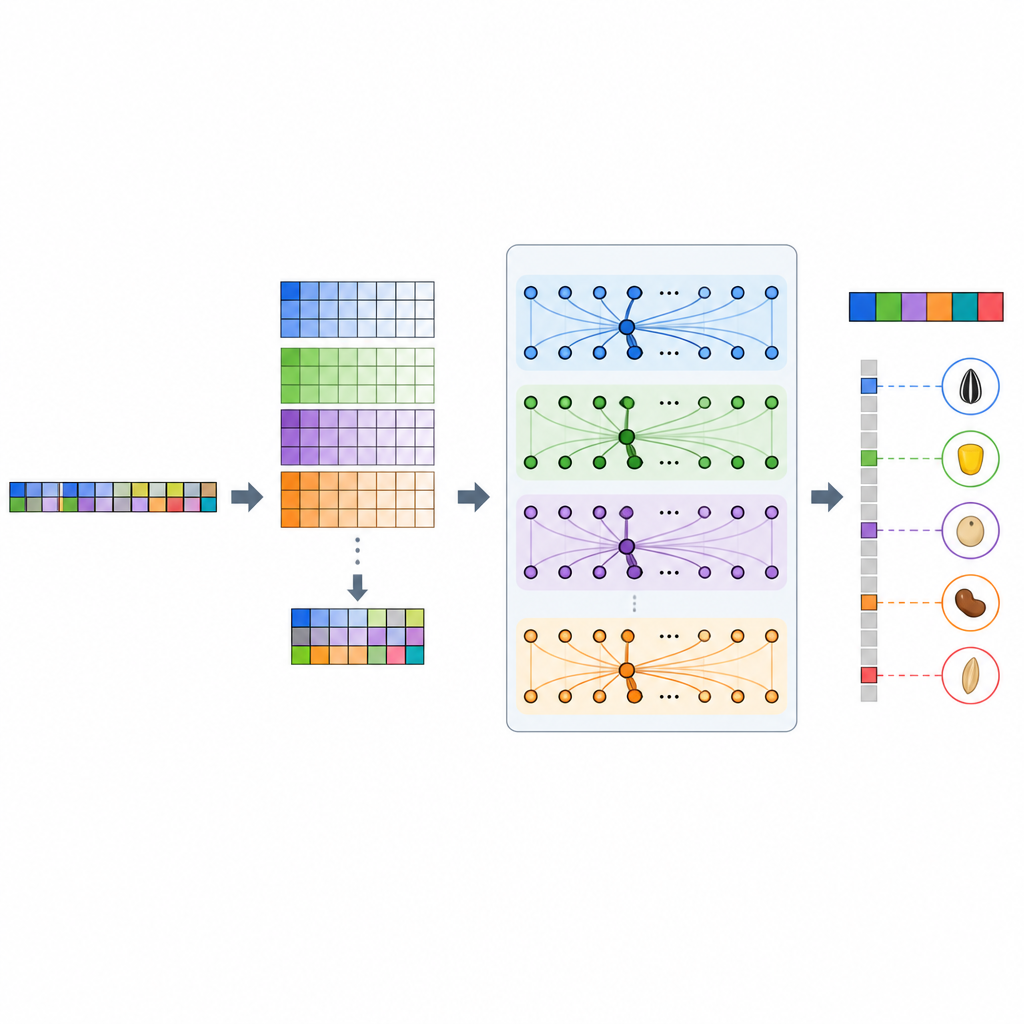
De zwarte doos van AI in genetica openen
Een veelgehoorde zorg bij deep learning is dat het als een zwarte doos werkt, waardoor het voor biologen moeilijk is te zien waarom een voorspelling is gedaan. De auteurs gingen hiermee om door SHAP te gebruiken, een populaire methode voor uitlegbare AI, om de bijdrage van elke DNA-variant aan de voorspellingen van het model te meten. Ze vonden dat GP-WAITER vaak varianten benadrukte die zich in genen of regulatorische regio’s bevinden die al bekend zijn als beïnvloeders van sleutelverbindingen zoals vitamine E, carotenoïden en isoflavonen in sojabonen. In sommige gevallen wees het model op veelbelovende varianten die standaard associatietests hadden gemist, wat suggereert dat het zowel sterke als subtiele genetische signalen kan terugvinden die van belang zijn voor voeding en opbrengst.
Wat dit betekent voor toekomstige veredeling van gewassen
Door gewogen genetische informatie te combineren met een krachtige op aandacht gebaseerde architectuur biedt GP-WAITER een praktische manier om plantkenmerken nauwkeuriger te voorspellen, terwijl de link met de onderliggende biologie behouden blijft. Voor veredelaars betekent dit dat ze duizenden kandidaatlijnen kunnen rangschikken op basis van alleen DNA-gegevens, veldproeven kunnen concentreren op de meest veelbelovende kruisingen, en eenvoudiger genetische regio’s kunnen aanwijzen die het waard zijn om te targeten bij precisieveredeling. Voor het brede publiek toont dit werk hoe geavanceerde AI-methoden kunnen helpen om sneller betere gewassen te leveren, en zo veerkrachtigere en voedzamere voedselsystemen te ondersteunen zonder elk plantje in elke omgeving te hoeven testen.
Bronvermelding: Li, J., Yu, L., Li, M. et al. Leveraging weighted embedding and Transformer architecture to improve phenotype prediction of complex traits for crops. Nat Commun 17, 4427 (2026). https://doi.org/10.1038/s41467-026-71035-5
Trefwoorden: genomische voorspelling, gewasveredeling, transformer-model, sojabonen genetica, machine learning in landbouw