Clear Sky Science · fr
Exploiter l’embedding pondéré et l’architecture Transformer pour améliorer la prédiction des phénotypes de caractères complexes chez les cultures
Sélection plus intelligente pour de meilleures cultures
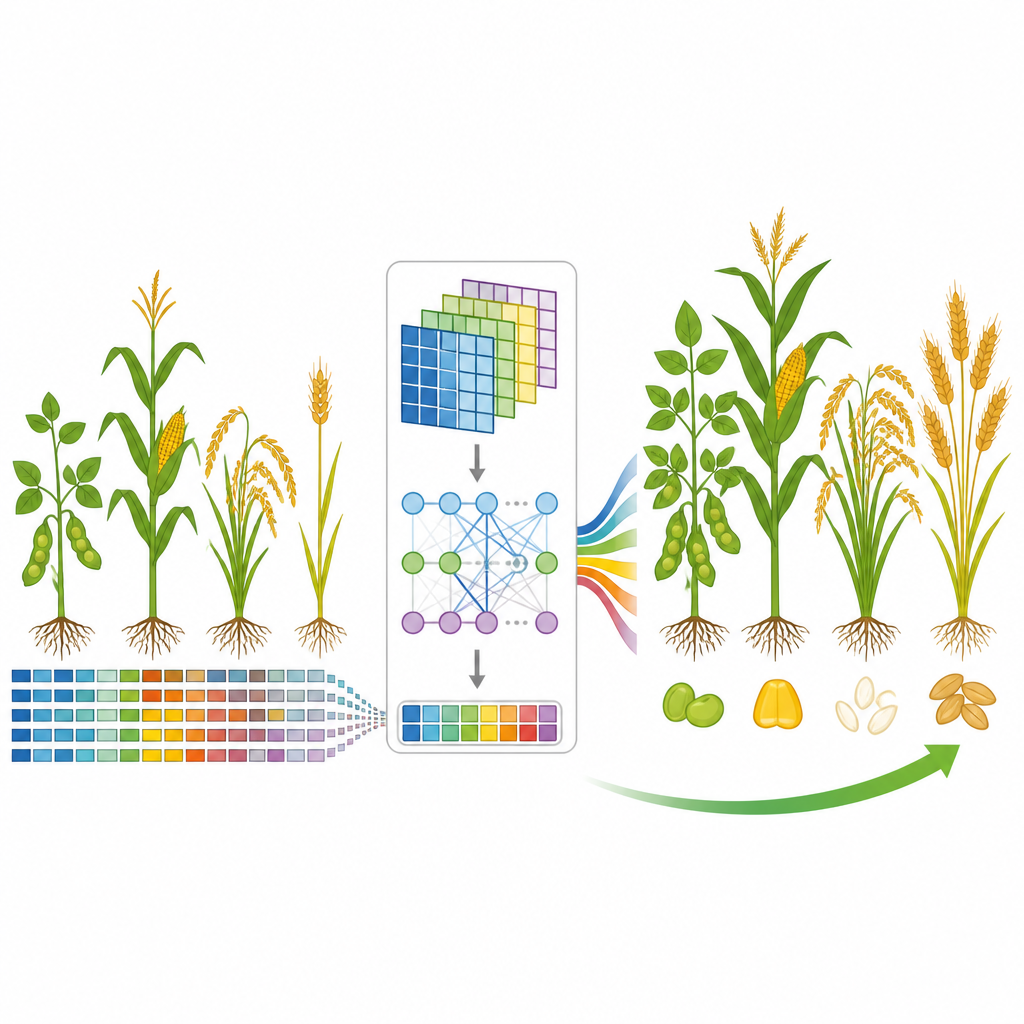
Nourrir un monde en croissance implique de sélectionner des cultures qui produisent davantage, tolèrent le stress et offrent une meilleure valeur nutritionnelle. Pourtant, décider quelles lignées croiser reposait longtemps sur des essais de terrain lents et itératifs. Cette étude introduit un nouveau modèle d’intelligence artificielle qui apprend directement à partir de l’ADN pour prédire la performance d’une plante, ouvrant la voie à des décisions de sélection plus rapides et plus précises pour des cultures comme le soja, le maïs, le riz et le blé.
Du code ADN aux caractères visibles
Chaque plante porte des millions de petites différences dans l’ADN qui, ensemble, déterminent des caractères tels que la teneur en huile, le rendement ou la tolérance à la sécheresse. Les outils statistiques traditionnels peuvent exploiter ces informations, mais peinent lorsque les données sont massives et que les effets génétiques sont faibles et répartis sur l’ensemble du génome. Les auteurs relèvent ce défi en considérant de longues séquences d’ADN comme un langage complexe et en utilisant un modèle capable de lire ce langage en profondeur, détectant non seulement les signaux évidents mais aussi les nombreux petits variants qui s’additionnent pour produire de grandes différences en conditions de terrain.
Un nouveau modèle qui écoute les signaux génétiques importants
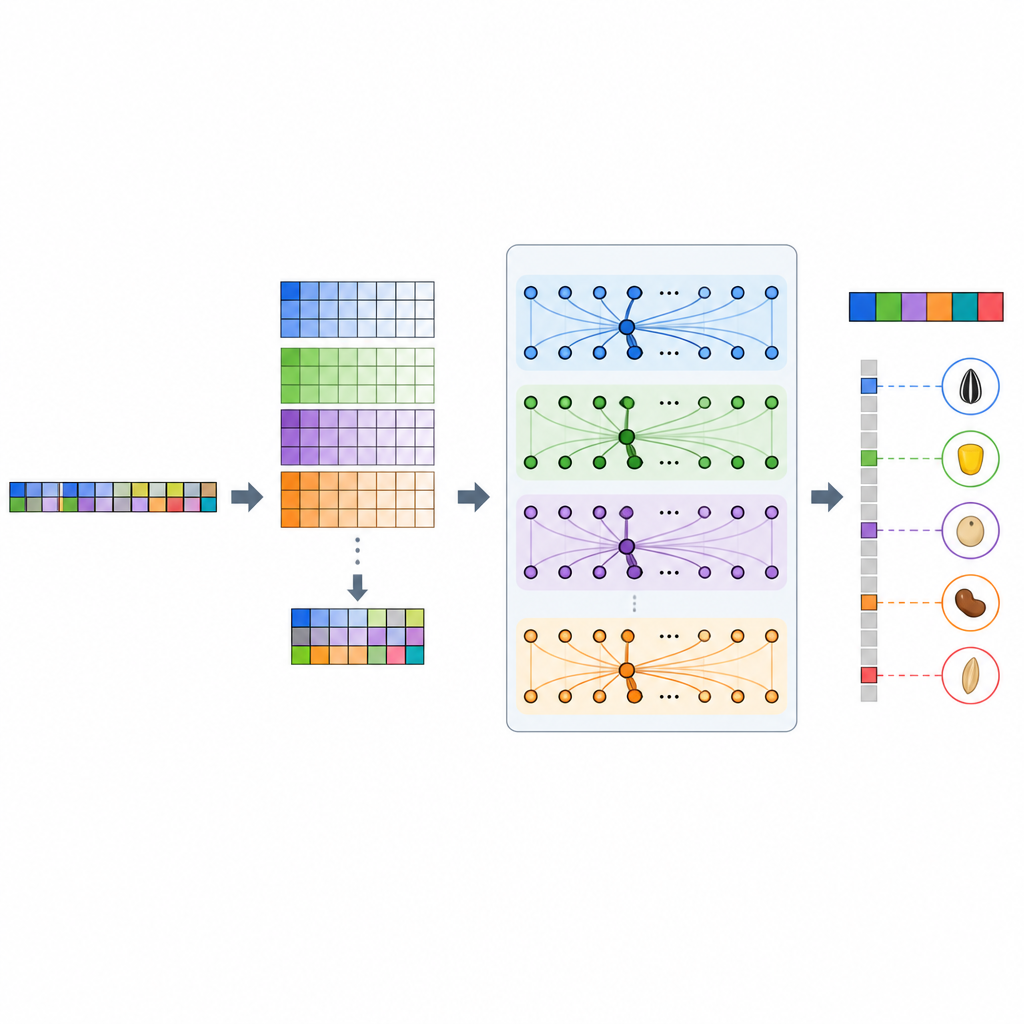
L’équipe a développé GP-WAITER, un cadre d’apprentissage profond qui combine deux idées. D’abord, il exploite les résultats des études d’association pangénomique (GWAS), qui signalent les sites d’ADN statistiquement liés aux caractères, pour attribuer à chaque marqueur génétique un « poids » numérique reflétant son niveau d’information potentiel. Ensuite, il injecte ces marqueurs pondérés dans un système hybride qui associe des couches convolutionnelles, efficaces pour repérer des motifs locaux, à un module Transformer, reconnu pour capter les relations à longue portée dans les modèles de langage. En découpant des séquences d’ADN ultra-longues en fragments gérables et en attribuant une attention aux régions influentes, GP-WAITER peut suivre comment des variants génétiques distants interagissent pour façonner un caractère.
Plus grande précision et calcul plus rapide sur de nombreuses cultures
Pour évaluer GP-WAITER, les chercheurs ont réuni six larges jeux de données couvrant des milliers de lignées de soja, maïs, riz et blé, et une gamme étendue de caractères nutritionnels et agronomiques. Ils ont comparé le nouveau modèle à sept outils de prédiction de pointe, y compris des méthodes linéaires classiques, des approches d’apprentissage automatique comme le gradient boosting, ainsi que d’autres réseaux profonds et modèles basés sur Transformer. Sur l’ensemble des jeux de données, GP-WAITER a systématiquement produit des prédictions plus précises, améliorant dans certains cas la précision d’environ trois quarts et réduisant l’erreur de prédiction jusqu’à 78 %. Sur un très grand jeu de données de soja comportant des centaines de milliers de marqueurs, il s’est aussi entraîné nettement plus rapidement que d’autres modèles profonds tout en consommant moins de mémoire GPU, montrant sa capacité à traiter efficacement des données à l’échelle réelle de la sélection.
Ouvrir la boîte noire de l’IA en génétique
Un reproche fréquent adressé à l’apprentissage profond est son caractère de « boîte noire », qui rend difficile pour les biologistes de comprendre pourquoi une prédiction est faite. Les auteurs ont traité ce point en utilisant SHAP, une méthode d’explicabilité populaire, pour mesurer la contribution de chaque variant d’ADN aux prédictions du modèle. Ils ont constaté que GP-WAITER mettait souvent en évidence des variants situés dans des gènes ou des régions régulatrices déjà connus pour influencer des composés clés tels que la vitamine E, les caroténoïdes et les isoflavones dans les graines de soja. Dans certains cas, le modèle a identifié des variants prometteurs que les tests d’association standards avaient manqués, suggérant qu’il peut récupérer à la fois des signaux génétiques forts et subtils pertinents pour la nutrition et le rendement.
Ce que cela signifie pour la sélection future des cultures
En combinant une information génétique pondérée avec une architecture puissante fondée sur l’attention, GP-WAITER offre un moyen pratique de prédire les caractères des plantes avec plus de précision tout en conservant un lien clair avec la biologie sous-jacente. Pour les sélectionneurs, cela signifie qu’ils peuvent classer des milliers de lignées candidates à partir des seules données d’ADN, concentrer les essais de terrain sur les croisements les plus prometteurs et identifier plus facilement les régions génétiques à cibler dans la sélection de précision. Pour le grand public, ce travail montre comment des méthodes d’IA avancées peuvent aider à fournir des cultures meilleures et plus rapidement, soutenant des systèmes alimentaires plus résilients et nutritifs sans devoir tester chaque plante dans chaque environnement.
Citation: Li, J., Yu, L., Li, M. et al. Leveraging weighted embedding and Transformer architecture to improve phenotype prediction of complex traits for crops. Nat Commun 17, 4427 (2026). https://doi.org/10.1038/s41467-026-71035-5
Mots-clés: prédiction génomique, amélioration des cultures, modèle Transformer, génétique du soja, apprentissage automatique en agriculture