Clear Sky Science · de
Nutzung gewichteter Einbettungen und Transformer-Architektur zur Verbesserung der Phänotypvorhersage komplexer Merkmale bei Kulturpflanzen
Klügere Zucht für bessere Ernten
Um eine wachsende Welt zu ernähren, müssen Pflanzen gezüchtet werden, die höhere Erträge liefern, Stress besser tolerieren und nährstoffreicher sind. Doch die Entscheidung, welche Linien gekreuzt werden sollen, beruhte lange auf langsamen, durch Versuch und Irrtum bestimmten Feldprüfungen. Diese Studie stellt ein neues Modell der künstlichen Intelligenz vor, das direkt aus der DNA lernt, um vorherzusagen, wie sich eine Pflanze entwickelt. Das verspricht schnellere und präzisere Zuchtentscheidungen für Kulturpflanzen wie Sojabohne, Mais, Reis und Weizen.
Vom DNA-Code zu sichtbaren Merkmalen
Jede Pflanze trägt Millionen kleiner DNA-Unterschiede, die zusammen Merkmale wie Ölgehalt, Ertrag oder Trockenresistenz formen. Traditionelle statistische Werkzeuge können diese Informationen nutzen, geraten jedoch an ihre Grenzen, wenn die Daten riesig sind und die genetischen Effekte dezentral und subtil über das gesamte Genom verteilt sind. Die Autoren begegnen dieser Herausforderung, indem sie lange DNA-Abschnitte wie eine komplexe Sprache behandeln und ein Modell einsetzen, das diese Sprache tiefer „lesen“ kann — es erkennt nicht nur offensichtliche Signale, sondern auch die vielen kleinen Varianten, die sich leise zu großen Unterschieden im Feld aufsummieren.
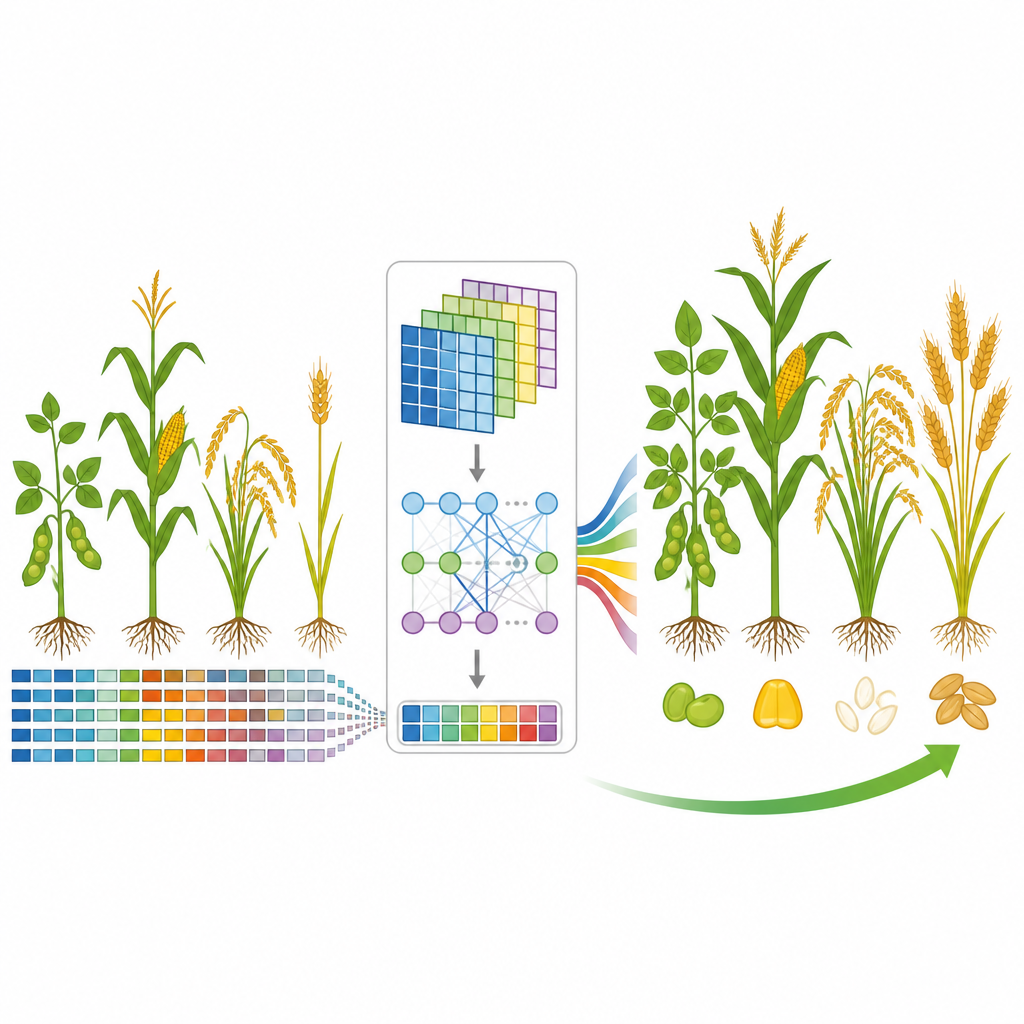
Ein neues Modell, das wichtigen genetischen Signalen lauscht
Das Team entwickelte GP-WAITER, ein Deep-Learning-Framework, das zwei Ideen verbindet. Erstens nutzt es Ergebnisse aus genomweiten Assoziationsstudien, die DNA-Stellen identifizieren, die statistisch mit Merkmalen verknüpft sind, und verleiht jedem genetischen Marker ein numerisches „Gewicht“, das seine Informationsfülle widerspiegelt. Zweitens speist es diese gewichteten Marker in ein hybrides System ein, das Faltungs‑ (Convolutional) Schichten, die lokale Muster gut erfassen, mit einem Transformer-Modul kombiniert, das aus Sprachmodellen dafür bekannt ist, langreichweitige Beziehungen abzubilden. Indem ultra‑lange DNA-Sequenzen in handhabbare Stücke zerlegt und auf einflussreiche Regionen besondere Aufmerksamkeit gelegt wird, kann GP-WAITER verfolgen, wie weit entfernte genetische Varianten gemeinsam ein Merkmal formen.
Höhere Genauigkeit und schnellere Berechnungen über viele Kulturen hinweg
Um GP-WAITER zu testen, stellten die Forscher sechs große Datensätze zusammen, die Tausende von Linien von Sojabohne, Mais, Reis und Weizen sowie ein breites Spektrum an Nähr‑ und agronomischen Merkmalen abdecken. Sie verglichen das neue Modell mit sieben führenden Vorhersagewerkzeugen, darunter klassische lineare Methoden, maschinelle Lernverfahren wie Gradient Boosting sowie andere Deep‑Netzwerke und Transformer-basierte Modelle. In allen Datensätzen lieferte GP-WAITER durchgehend genauere Vorhersagen, in einigen Fällen mit einer Genauigkeitsverbesserung von bis zu etwa drei Vierteln und einer Reduktion des Vorhersagefehlers um bis zu 78 Prozent. In einem sehr großen Sojabohnen‑Datensatz mit Hunderttausenden von DNA-Markern trainierte es zudem deutlich schneller als konkurrierende Deep‑Modelle und benötigte weniger Grafikkarten‑Speicher, was zeigt, dass es reale, zuchtnahe Daten effizient verarbeiten kann.
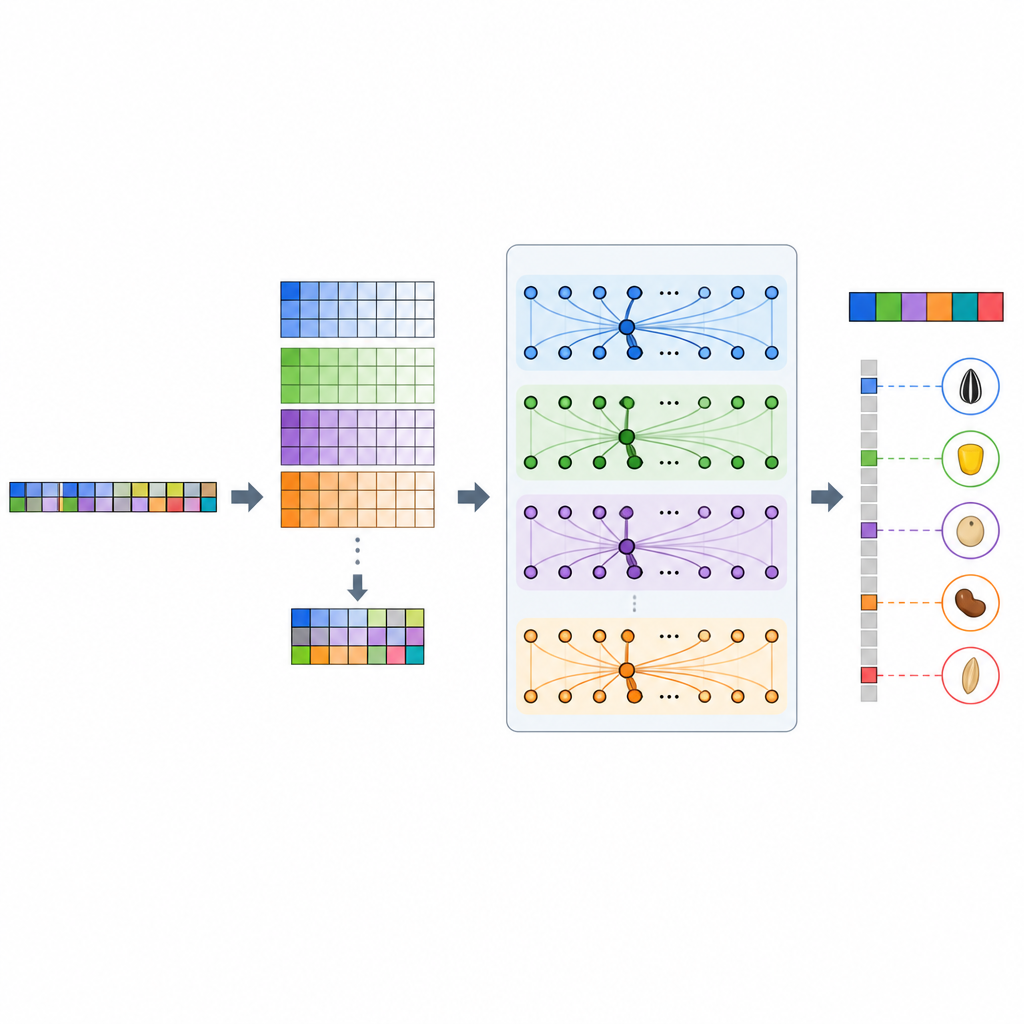
Die Blackbox der KI in der Genetik öffnen
Ein häufiges Anliegen bei Deep Learning ist, dass es wie eine Blackbox wirkt und Biologen schwer nachvollziehen können, warum eine Vorhersage getroffen wurde. Die Autoren gingen dieses Problem an, indem sie SHAP einsetzten, eine gängige Methode der erklärbaren KI, um den Beitrag jeder DNA‑Variante zur Modellvorhersage zu messen. Sie fanden heraus, dass GP-WAITER häufig Varianten hervorhob, die in Genen oder regulatorischen Regionen liegen, von denen bereits bekannt ist, dass sie Schlüsselverbindungen wie Vitamin E, Carotinoide und Isoflavone in Sojabohnensamen beeinflussen. In manchen Fällen zeigte das Modell vielversprechende Varianten auf, die Standard‑Assoziationstests übersehen hatten, was darauf hindeutet, dass es sowohl starke als auch subtile genetische Signale zurückgewinnen kann, die für Nährwert und Ertrag wichtig sind.
Was das für die zukünftige Pflanzenzucht bedeutet
Durch die Kombination gewichteter genetischer Informationen mit einer leistungsfähigen auf Aufmerksamkeit basierenden Architektur bietet GP-WAITER einen praktischen Weg, Pflanzenmerkmale genauer vorherzusagen und gleichzeitig eine klare Verbindung zur zugrunde liegenden Biologie zu behalten. Für Züchter bedeutet das, Tausende von Kandidatenlinien allein anhand von DNA‑Daten zu bewerten, Feldversuche auf die vielversprechendsten Kreuzungen zu konzentrieren und genetische Regionen leichter zu identifizieren, die sich für präzise Zuchtmaßnahmen eignen. Für die breite Öffentlichkeit zeigt die Arbeit, wie fortgeschrittene KI‑Methoden helfen können, bessere Pflanzen schneller bereitzustellen und damit robustere und nährstoffreichere Ernährungssysteme zu unterstützen, ohne jede Pflanze in jeder Umgebung testen zu müssen.
Zitation: Li, J., Yu, L., Li, M. et al. Leveraging weighted embedding and Transformer architecture to improve phenotype prediction of complex traits for crops. Nat Commun 17, 4427 (2026). https://doi.org/10.1038/s41467-026-71035-5
Schlüsselwörter: genomische Vorhersage, Pflanzenzucht, Transformer-Modell, Sojabohnen-Genetik, Maschinelles Lernen in der Landwirtschaft