Clear Sky Science · it
Sfruttare embedding pesati e architettura Transformer per migliorare la previsione fenotipica di tratti complessi nelle colture
Selezione più intelligente per colture migliori
Nutrire un mondo in crescita significa allevare colture che producano di più, tollerino stress e offrano migliore valore nutritivo. Tuttavia, decidere quali linee incrociare si è basato a lungo su test di campo lenti e di tipo prova-errore. Questo studio introduce un nuovo modello di intelligenza artificiale che apprende direttamente dal DNA per prevedere le prestazioni di una pianta, promettendo decisioni di miglioramento più rapide e precise per colture come soia, mais, riso e grano.
Dal codice del DNA ai tratti visibili
Ogni pianta porta milioni di piccole differenze nel DNA che insieme modellano caratteristiche come il contenuto di olio, la resa o la tolleranza alla siccità. Gli strumenti statistici tradizionali possono usare queste informazioni, ma faticano quando i dati sono enormi e gli effetti genetici sono sottili e distribuiti su tutto il genoma. Gli autori affrontano questa sfida trattando lunghi tratti di DNA come un linguaggio complesso e utilizzando un modello in grado di leggere questo linguaggio in profondità, notando non solo segnali evidenti ma anche le molte piccole varianti che, sommate, producono grandi differenze in campo.
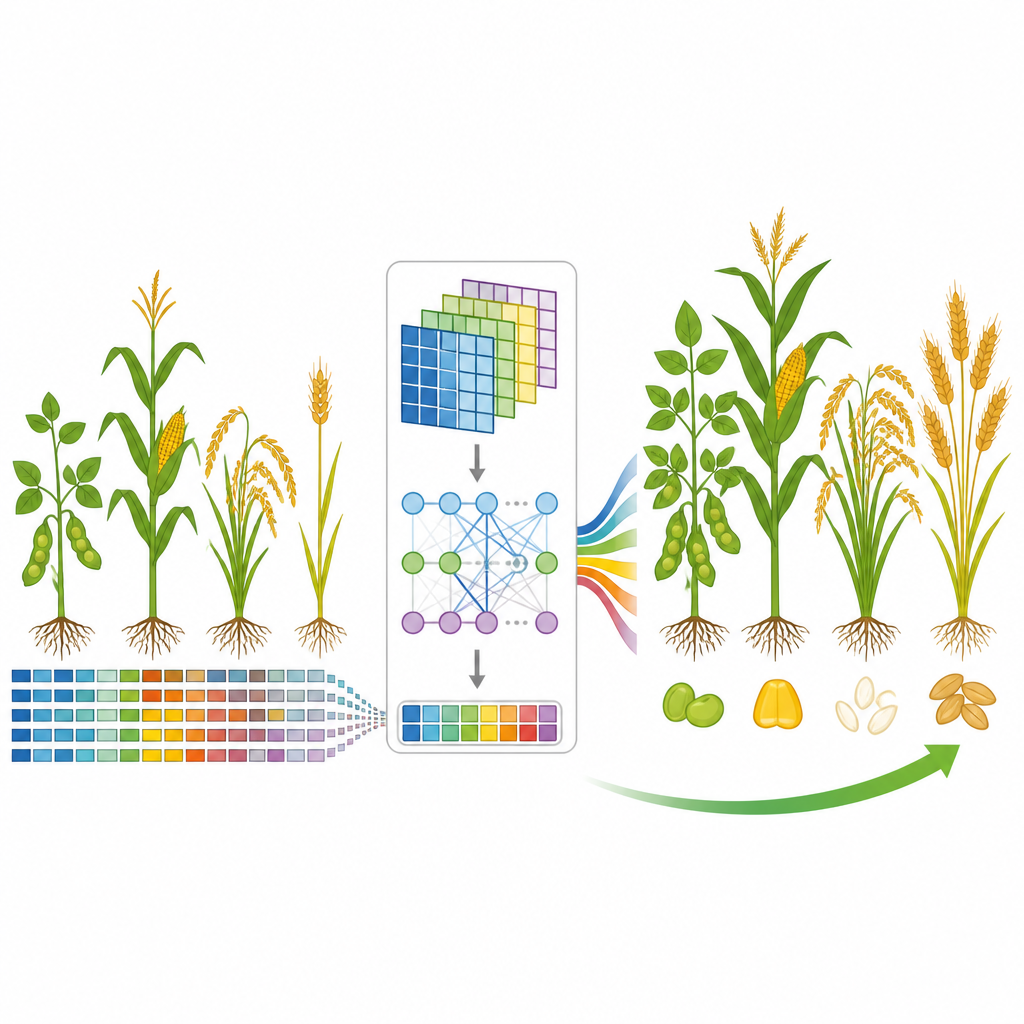
Un nuovo modello che coglie i segnali genetici importanti
Il team ha sviluppato GP-WAITER, un framework di deep learning che combina due idee. Primo, utilizza i risultati degli studi di associazione genome-wide, che segnalano siti del DNA statisticamente legati ai tratti, per assegnare a ciascun marcatore genetico un “peso” numerico che riflette quanto possa essere informativo. Secondo, alimenta questi marcatori pesati in un sistema ibrido che unisce strati convoluzionali, efficaci nell’individuare pattern locali, con un modulo Transformer, noto nei modelli linguistici per catturare relazioni a lungo raggio. Suddividendo sequenze di DNA ultralonghe in pezzi gestibili e assegnando attenzione alle regioni influenti, GP-WAITER può tracciare come varianti genetiche distanti collaborino per modellare un tratto.
Maggiore accuratezza e calcolo più veloce su molte colture
Per testare GP-WAITER, i ricercatori hanno assemblato sei grandi set di dati che coprono migliaia di linee di soia, mais, riso e grano, e una vasta gamma di tratti nutrizionali e agronomici. Hanno confrontato il nuovo modello con sette tra i principali strumenti di predizione, incluse metodologie lineari classiche, approcci di machine learning come il gradient boosting e altre reti profonde e modelli basati su Transformer. Su tutti i dataset, GP-WAITER ha prodotto costantemente previsioni più accurate, in alcuni casi migliorando l’accuratezza fino a circa tre quarti e riducendo l’errore di predizione fino al 78 percento. Su un dataset molto grande di soia con centinaia di migliaia di marcatori, si è anche addestrato sostanzialmente più velocemente rispetto ad altri modelli deep pur usando meno memoria della GPU, dimostrando di poter gestire dati su scala reale per il miglioramento genetico in modo efficiente.
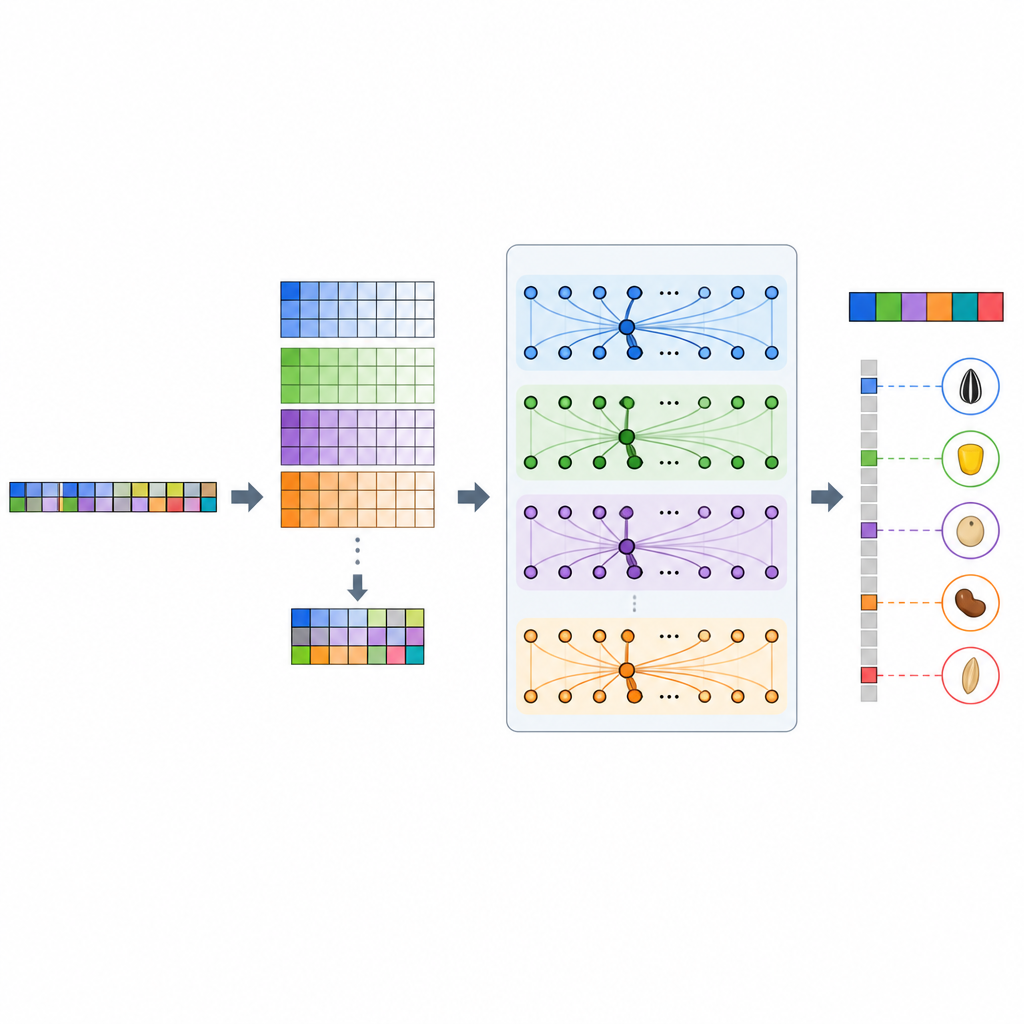
Aprire la scatola nera dell’IA in genetica
Una preoccupazione comune con il deep learning è che si comporti come una scatola nera, rendendo difficile per i biologi capire perché viene fatta una previsione. Gli autori hanno affrontato questo problema usando SHAP, un noto metodo di explainable AI, per misurare il contributo di ciascuna variante del DNA alle predizioni del modello. Hanno rilevato che GP-WAITER evidenziava frequentemente varianti collocate in geni o regioni regolatorie già note per influenzare composti chiave come la vitamina E, i carotenoidi e le isoflavoni nei semi di soia. In alcuni casi, il modello ha indicato varianti promettenti che i test di associazione standard avevano perso, suggerendo che può recuperare sia segnali genetici forti sia sottili rilevanti per nutrizione e resa.
Cosa significa per il miglioramento futuro delle colture
Combinando informazioni genetiche pesate con una potente architettura basata sull’attenzione, GP-WAITER offre un modo pratico per prevedere i tratti delle piante con maggiore accuratezza mantenendo comunque un chiaro collegamento con la biologia sottostante. Per i miglioratori significa poter classificare migliaia di linee candidate usando solo dati DNA, concentrare i test di campo sugli incroci più promettenti e individuare più facilmente le regioni genetiche da prendere di mira nel miglioramento di precisione. Per il pubblico più ampio, il lavoro mostra come metodi avanzati di IA possano contribuire a ottenere colture migliori più rapidamente, sostenendo sistemi alimentari più resilienti e nutritivi senza dover testare ogni pianta in ogni ambiente.
Citazione: Li, J., Yu, L., Li, M. et al. Leveraging weighted embedding and Transformer architecture to improve phenotype prediction of complex traits for crops. Nat Commun 17, 4427 (2026). https://doi.org/10.1038/s41467-026-71035-5
Parole chiave: predizione genomica, miglioramento delle colture, modello Transformer, genetica della soia, machine learning in agricoltura