Clear Sky Science · zh
通过对比学习解读 DEL 口袋模式
为什么观察蛋白质“口袋”能加速新药研发
现代的药物发现者现在可以使用 DNA 编码文库(DEL)同时筛选数万亿种微小分子。然而,只有少数由 DEL 得到的分子最终成为真正的药物。一个重要的缺失环节是无法确切知道体内哪些蛋白质具有适合 DEL 分子附着的凹槽——“口袋”。本研究通过绘制成功的 DEL 口袋的特征并构建名为 ErePOC 的人工智能模型来寻找人体中相似的口袋,从而填补了这一空白。
DEL 技术如何搜索新药分子
DEL 有点像带条形码的鱼饵。化学家将候选小分子连接到作为 ID 标签的短 DNA 片段上,然后将大量带标签的分子混合物暴露于目标蛋白。能够结合的分子通过测序其 DNA 被识别出来。这种方法速度快且成本低,但将 DEL 命中转化为真正的药物仍然困难。部分原因在于 DEL 分子具有某些化学限制,例如在水相中的合成方式和 DNA 标签的连接方式。这些限制使它们倾向于偏爱特定类型的蛋白质口袋,但直到现在,这些偏好还没有被系统地描绘出来。
什么样的口袋对 DEL 分子有吸引力
作者首先比较了数千个结合不同配体类型的蛋白口袋:普通生物小分子、经 FDA 批准的药物和 DEL 命中。他们发现 DEL 和药物结合口袋往往比天然配体的口袋更大、化学复杂性更高。具体而言,DEL 口袋更开阔且更疏水——意味着偏好油性、排斥水的相互作用——同时还保留了一小组重要的极性接触点来微调结合。某些体积较大的氨基酸提供芳香和疏水表面,例如酪氨酸和苯丙氨酸,在 DEL 和药物结合口袋中比在典型蛋白表面更常见。总体上,DEL 口袋更像经典的药物靶点口袋,而不是普通的代谢位点,但带有向大而疏水空腔的额外偏好。
教 AI 模型识别口袋的“个性”
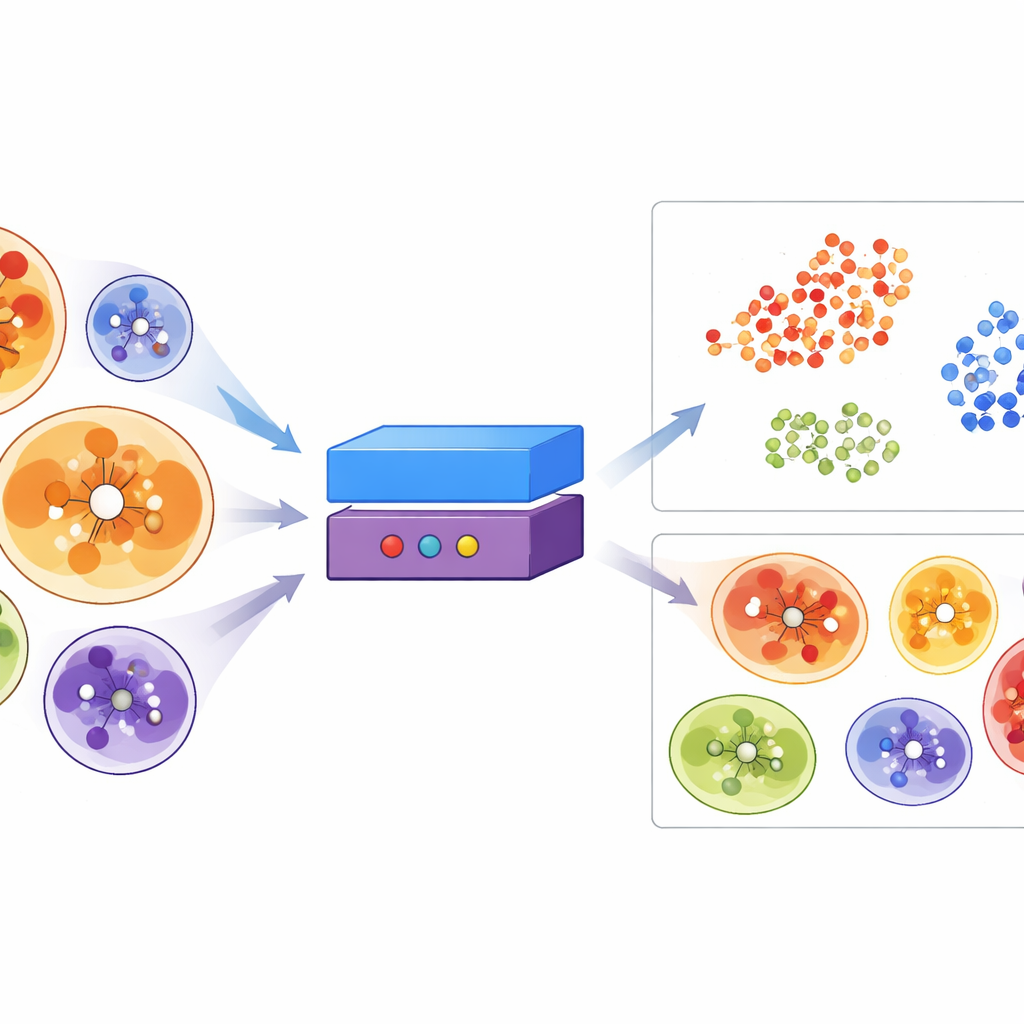
为了超越简单的大小和化学计数,团队构建了 ErePOC,一个将每个结合口袋视为指纹的表征模型。它起始于蛋白质语言模型的嵌入,这些嵌入捕捉了从数百万序列中学到的模式,并将构成口袋的残基信息压缩为紧凑的数值向量。通过对比学习,ErePOC 被训练使得结合化学类似配体的口袋在该抽象空间中彼此靠近,而结合差异很大的分子则相互远离。当作者可视化该空间时,已知结合相同辅因子(如 ATP 或血红素)的口袋形成了分明的簇,表明模型学会按功能行为对口袋进行分组,而不仅仅按整体蛋白形状。
在整个人类蛋白组中寻找适合 DEL 的目标
在训练好 ErePOC 后,研究者将已知的 DEL 口袋、药物口袋以及来自实验和预测蛋白结构的数十万个口袋投影到相同的景观中。DEL 口袋分布广泛,表明理论上 DEL 筛选可以覆盖大部分传统的“可成药”空间,但它们仍对与较大、疏水口袋相关的某些区域表现出明显偏好。团队接着扫描了超过 23,000 个 AlphaFold 预测的人类蛋白,筛选出定义良好的口袋,并询问哪些口袋在 ErePOC 空间中最像已知的 DEL 口袋。他们识别出近 2,800 个在人类蛋白中具有高度类似于成功 DEL 位点的口袋,这些口袋在转移酶、水解酶、氧化还原酶、染色质调控因子以及一些 RNA 结合蛋白等家族中有强烈富集。后续对大型虚拟 DEL 的计算对接表明,这些由 ErePOC 标记的口袋确实更倾向于有利地结合类 DEL 分子。
这对未来药物发现意味着什么
对非专业读者来说,关键结论是超大型化学文库的成功在很大程度上依赖于选择合适的蛋白质口袋,就像依赖分子本身一样。该工作表明 DEL 命中往往来自大、柔性且疏水的口袋,并引入了一个强大的 AI 工具,能够仅凭序列或结构识别此类口袋。通过使用 ErePOC 将 DEL 筛选聚焦于那些口袋已显示出与 DEL 相容性的蛋白,药物发现者可以优先考虑更有前景的靶点,减少无效筛选工作量,并可能拓展到未充分探索的类别,例如染色质和 RNA 结合蛋白。简而言之,该研究既清晰描绘了“DEL 适配”口袋的样貌,又提供了在整个人类蛋白组中寻找更多此类口袋的实用地图与指南。
引用: Zhang, W., Wang, Y., Zhan, R. et al. Deciphering DEL pocket patterns through contrastive learning. Nat Commun 17, 2810 (2026). https://doi.org/10.1038/s41467-026-69663-y
关键词: DNA 编码文库, 蛋白质结合口袋, 对比学习, 药物发现人工智能, ErePOC