Clear Sky Science · zh
甲骨文信息处理:一项综述
古老的龟甲兽骨,现代的问题
三千多年前,中国的占卜者在龟甲与牛骨上刻下对统治者的询问,然后以热力使其开裂以观兆。甲骨文是已知最早的汉字书写形式,也是窥见青铜时代政治、宗教与日常生活的珍贵窗口。然而今天这些骨片多已残破不全,书写难以辨认,许多字符仍未被解读。本文说明了新一波人工智能如何改变学者清理、重建、识读与解释这些脆弱遗迹的方式,以及仍然存在的挑战。
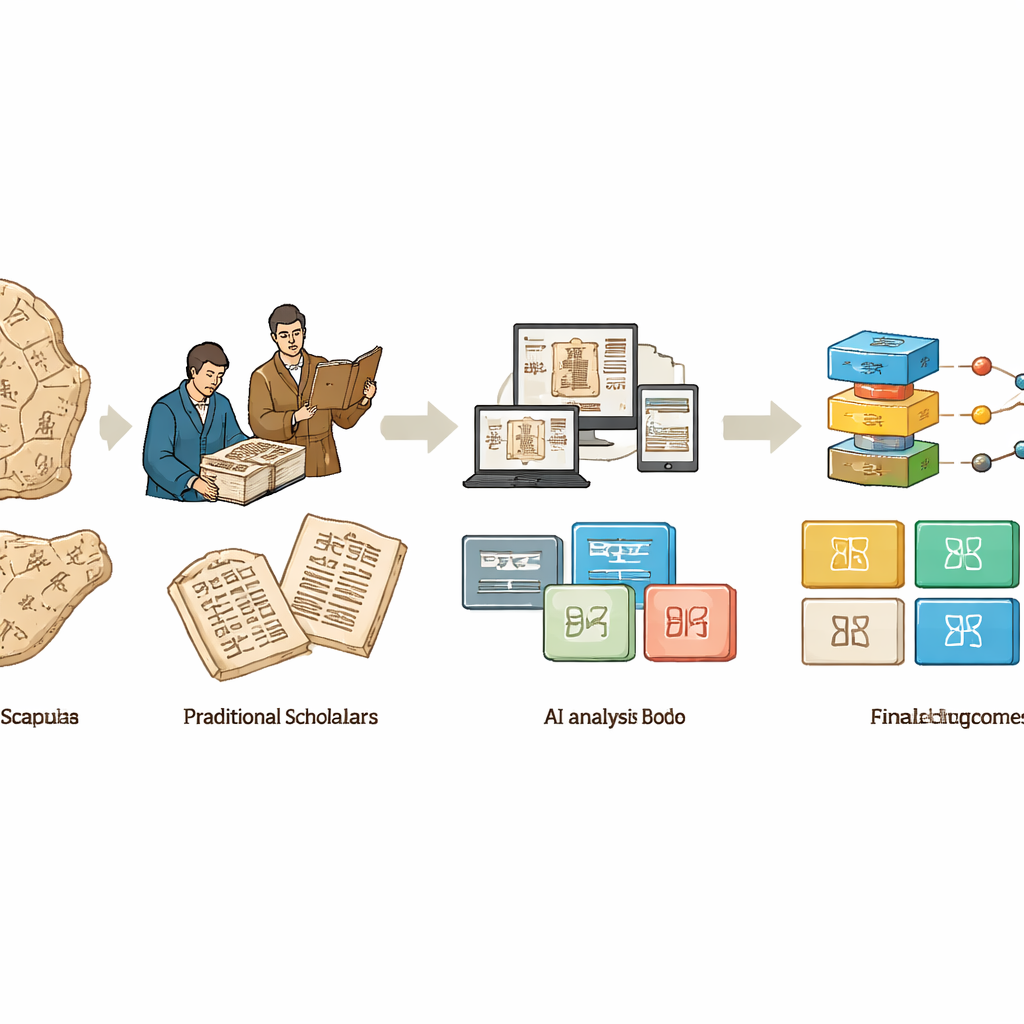
从手与眼到硅与代码
在上个世纪的大部分时间里,甲骨文只能由一小圈专家研究,他们耐心地审阅拓片、描摹与照片,汇编大量印刷目录,提出单字读法,并就如何给刻辞定年与分组争论不休。这些工作奠定了学科基础,但进展缓慢、难以复现,且高度依赖每位学者的记忆与判断。随着计算机的出现,研究人员开始将拓片数字化并应用诸如对比度增强与边缘检测等基本图像处理技巧。早期工具使得骨片更易观察与共享,但仍把字符当作单纯形状来处理,而非有意义的书写。
深度学习走入档案
深度学习的兴起改变了局面。卷积神经网络和最初在日常照片上训练的变换器,被重新训练以从有噪声的拓片中识别字符、将其分类,甚至帮助匹配原本属于同一块骨头的断片。为满足这些数据贪婪的模型,团队编制了数十个专门数据集:有的侧重于识别拓片中的每一个字符,有的用于分类裁切后的字形、关联偏旁与部件,或将古体与后世字体配对。然而数据也反映历史现实:少数常见字符出现数千次,而许多罕见或未解字符仅见一例。研究者通过巧妙的数据增强、能够合成新样本的生成模型,以及旨在仅凭少量——甚至零样本——已知例子识别字符的训练方案来应对这一问题。
教机器连接视觉与意义
在最新阶段,将视觉与语言结合的大型多模态模型被用于甲骨文研究。这些系统不再只定位字符,而尝试像人类古文字学家那样把字形外观与可能含义连接起来。新基准测试评估这些模型是否能识别字符、拼接断片、检索相似铭文并提出合理读法。有些框架尝试将古代符号直接映射到现代汉字,追溯数百年的视觉演变;有的把图形符号与现实物体的图像相连;还有的努力对一行占辞给出完整的文本性解释。代理式系统更进一步,通过编排多种工具与数据库,帮助用户在一次工作流程中跨越图像、转录与学术注记进行检索。
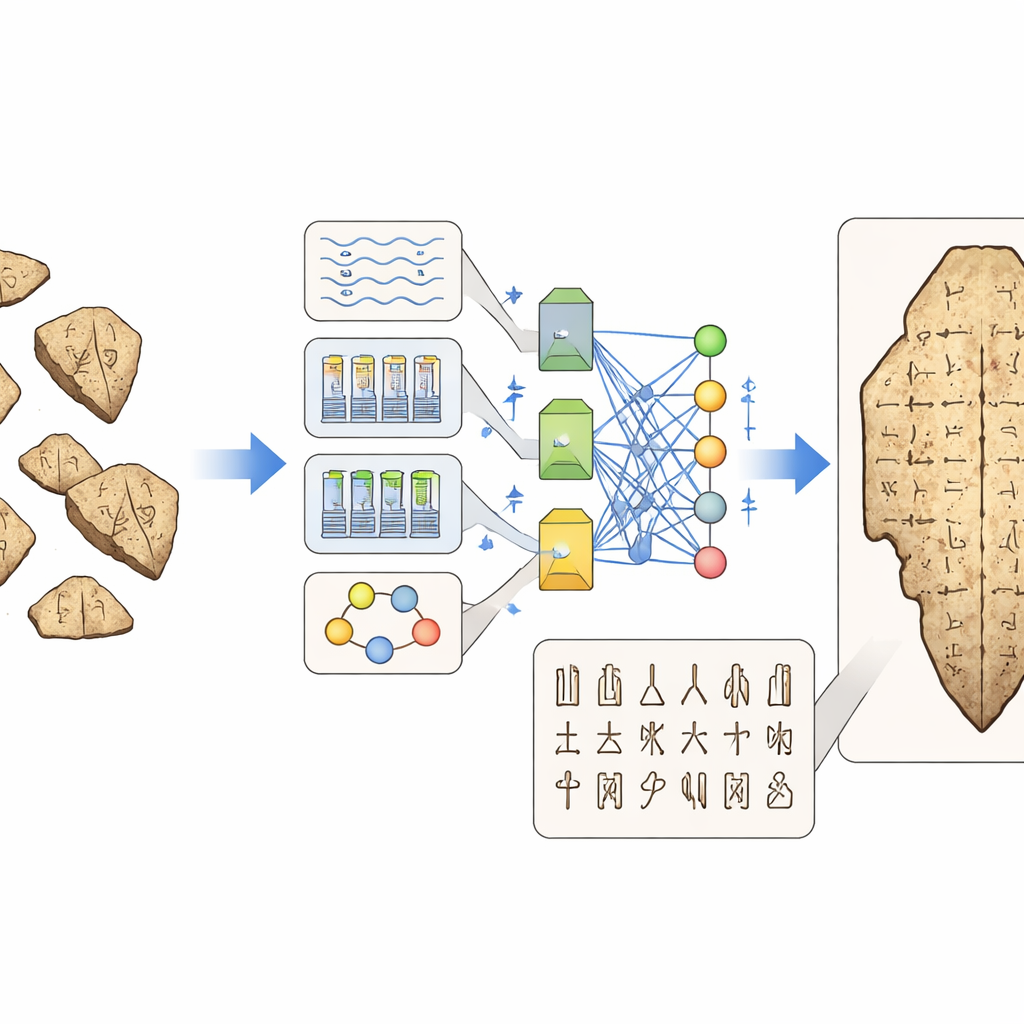
数据、评估与残破历史之谜
尽管进展迅速,综述仍指出顽固的障碍。许多最好的图像合集与三维扫描藏于博物馆或私人档案,未向公众开放,这使得公平比较方法或训练真正通用模型变得困难。即便是公开数据集也常表现出长尾类分布、标签不一致或图像质量低等问题。借用自目标检测或手写识别的标准性能得分,可能无法捕捉对历史学家真正重要的事项——例如模型是否将两个公认的同字变体混淆,或其提出的读法是否尊重一个字由更小部件构成的结构。人工评估同样支离破碎:不同研究招募不同类型的专家、提出不同的问题,且很少提供足够细节以便他人复现实验。
古代文字与未来人工智能的相遇
为推动前进,作者主张建立更丰富、文档更完备的数据集;采用奖励结构与语义理解而非仅像素级匹配的评估方法;以及促进技术人员与古代汉字专家之间更紧密的合作。他们设想可从描述生成逼真甲骨风格字符的文本到图像生成器、专门以古文字训练的基础模型、可辩论并精炼竞争性读法的多代理系统,甚至能重建破碎骨片原始形状的三维复原。简言之,文章结论是人工智能不会单独“破解”甲骨文,但它可以成为强有力的伙伴——放大专家洞见,使庞大档案可检索,并把青铜时代的声音带给更广泛的公众。
引用: Chen, Z., Hua, W., Li, J. et al. Oracle bone inscriptions information processing: a comprehensive survey. npj Herit. Sci. 14, 220 (2026). https://doi.org/10.1038/s40494-026-02511-w
关键词: 甲骨文, 中国古代文字, 数字人文, 人工智能, 多模态模型