Clear Sky Science · fr
Traitement de l'information des inscriptions sur os oraculaires : un état des lieux complet
Os anciens, questions modernes
Il y a plus de 3 000 ans, des devins en Chine gravaient des questions adressées aux souverains sur des carapaces de tortue et des os de bœuf, puis les fissuraient par la chaleur pour lire les présages. Ces inscriptions sur os oraculaires constituent la plus ancienne écriture chinoise connue et offrent une rare fenêtre sur la politique, la religion et la vie quotidienne de l’âge du Bronze. Aujourd’hui toutefois, les os sont fortement fragmentés, l’écriture est difficile à lire et de nombreux signes restent indéchiffrés. Cet article explique comment de nouvelles vagues d’intelligence artificielle transforment la manière dont les chercheurs nettoient, reconstituent, lisent et interprètent ces traces fragiles du passé, et quels défis subsistent.
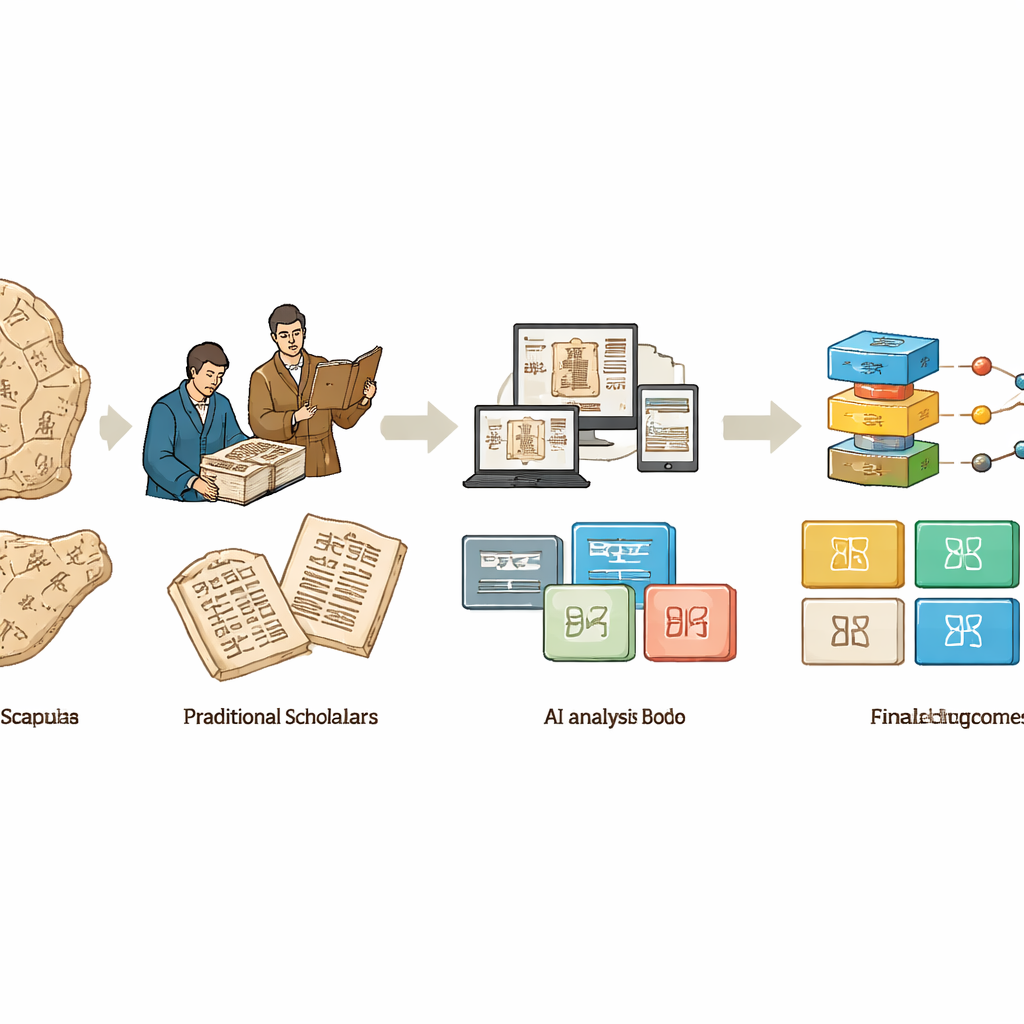
De la main et de l’œil au silicium et au code
Pendant la majeure partie du siècle dernier, les os oraculaires n’étaient accessibles qu’à un petit cercle d’experts qui examinaient laborieusement des frottis à l’encre, des relevés et des photographies. Ils ont rassemblé d’énormes catalogues imprimés, proposé des lectures de signes individuels et débattu de la datation et du groupement des inscriptions. Ce travail a posé les fondations du domaine mais était lent, difficile à reproduire et fortement dépendant de la mémoire et du jugement personnels de chaque chercheur. Avec l’arrivée des ordinateurs, les chercheurs ont commencé à numériser les frottis et à appliquer des astuces de traitement d’image basiques comme l’amélioration du contraste et la détection de contours. Ces premiers outils ont rendu les os plus faciles à voir et à partager, mais traitaient les signes comme de simples formes, et non comme une écriture porteuse de sens.
L’apprentissage profond investit les archives
L’essor de l’apprentissage profond a changé la donne. Les réseaux de neurones convolutionnels et les transformers, d’abord entraînés sur des photographies ordinaires, ont été réadaptés pour repérer des signes sur des frottis bruités, les trier en catégories et même aider à associer des fragments cassés appartenant autrefois au même os. Pour nourrir ces modèles gourmands en données, des équipes ont compilé des dizaines de jeux de données spécialisés : certains se concentraient sur l’identification de chaque caractère dans un frottis, d’autres sur la classification de glyphes recadrés, la mise en relation de radicaux et de composants, ou l’appariement de formes anciennes avec des écritures plus tardives. Mais les données reflètent la réalité historique : quelques caractères courants apparaissent des milliers de fois, tandis que de nombreux signes rares ou indéchiffrés n’apparaissent qu’une seule fois. Les chercheurs répondent par des augmentations de données ingénieuses, des modèles génératifs qui synthétisent de nouveaux exemples, et des schémas d’entraînement conçus pour reconnaître des caractères à partir de quelques—ou d’aucun—échantillon connu.
Apprendre aux machines à relier vision et sens
Dans la phase la plus récente, de grands modèles multimodaux combinant vision et langage sont adaptés aux os oraculaires. Plutôt que de se contenter de repérer où se trouvent les signes, ces systèmes tentent de relier l’apparence d’un glyphe à ce qu’il pourrait signifier, un peu comme le ferait un paléographe humain. De nouvelles évaluations testent si ces modèles peuvent reconnaître des caractères, réunir des fragments, retrouver des inscriptions similaires et proposer des lectures plausibles. Certains cadres cherchent à mapper directement les signes anciens sur des caractères chinois modernes, retraçant l’évolution visuelle sur des siècles ; d’autres relient des signes pictographiques à des images d’objets réels ; d’autres encore tentent des explications textuelles complètes de ce qu’une ligne de divination pourrait dire. Des systèmes de type agent vont plus loin en orchestrant plusieurs outils et bases de données, aidant l’utilisateur à rechercher simultanément dans des images, des transcriptions et des notes savantes au sein d’un même flux de travail.
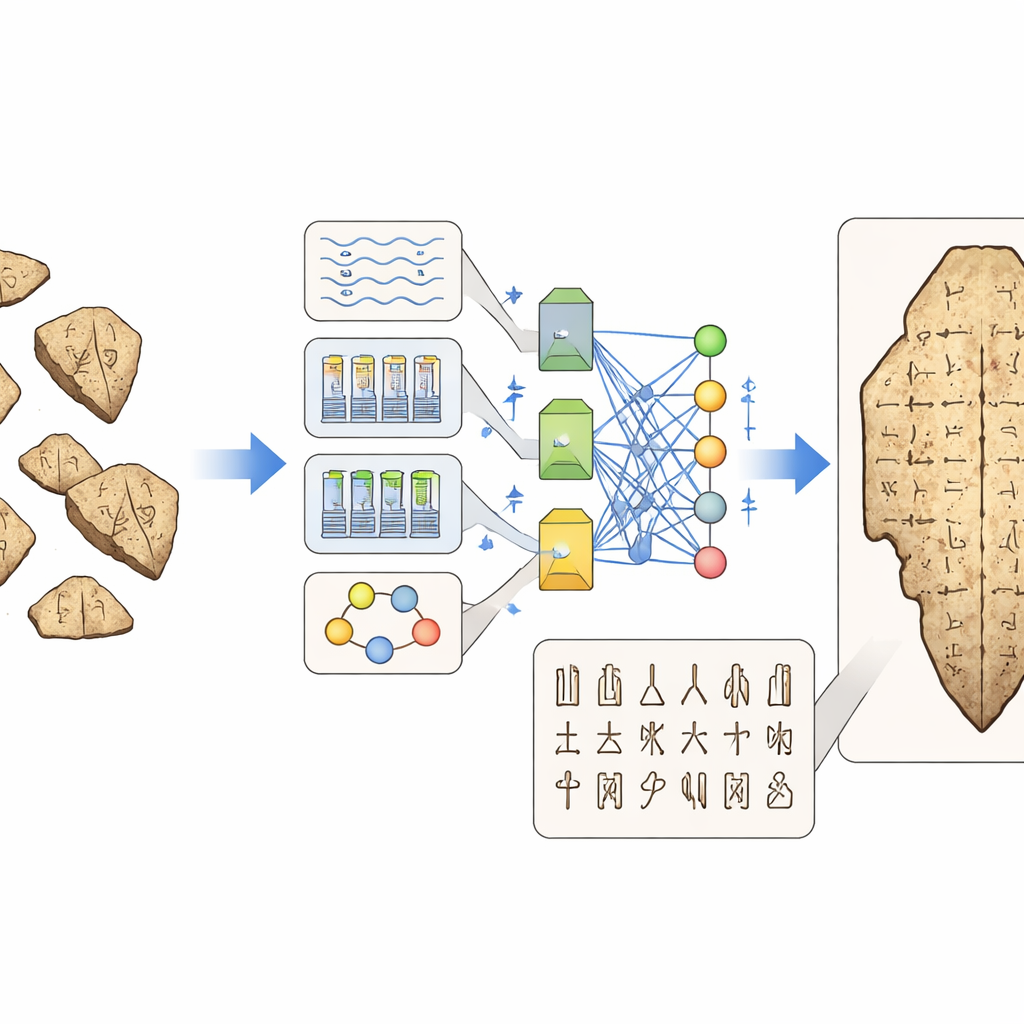
Données, évaluation et le casse-tête d’une histoire brisée
Malgré des progrès rapides, l’état des lieux met en évidence des obstacles tenaces. Nombre des meilleures collections d’images et scans 3D se trouvent dans des musées ou des archives privées et ne sont pas accessibles publiquement, ce qui complique la comparaison équitable des méthodes ou l’entraînement de modèles véritablement généraux. Même les jeux de données publics présentent souvent des distributions de classes à longue traîne, des étiquettes incohérentes ou une faible qualité d’image. Les scores de performance standard empruntés à la détection d’objets ou à la reconnaissance d’écriture manuscrite peuvent ne pas refléter ce qui importe réellement pour les historiens — par exemple si un modèle confond deux variantes acceptées d’un même caractère, ou si la lecture proposée respecte la manière dont un signe est construit à partir de parties plus petites. L’évaluation humaine est tout aussi fragmentée : les études recrutent différents types d’experts, posent des questions diverses et rapportent rarement leurs méthodes en détail suffisant pour que d’autres puissent reproduire leurs tests.
Où l’écriture ancienne rencontre l’IA du futur
Pour aller de l’avant, les auteurs plaident pour des jeux de données plus riches et mieux documentés ; des méthodes d’évaluation qui récompensent la compréhension structurelle et sémantique, pas seulement la concordance au niveau des pixels ; et une collaboration plus étroite entre technologues et spécialistes de l’écriture chinoise ancienne. Ils envisagent des générateurs texte‑vers‑image capables de produire des caractères réalistes de style oracle à partir de descriptions, des modèles de base entraînés spécifiquement sur des écritures anciennes, des systèmes multi‑agents qui débattent et affinent des lectures concurrentes, et même des reconstructions 3D qui restaurent la forme originelle des os brisés. En termes simples, la conclusion de l’article est que l’IA ne « résoudra » pas les os oraculaires à elle seule, mais peut devenir un partenaire puissant — amplifiant l’expertise, rendant d’immenses archives consultables et ouvrant les voix de l’âge du Bronze à un public beaucoup plus large.
Citation: Chen, Z., Hua, W., Li, J. et al. Oracle bone inscriptions information processing: a comprehensive survey. npj Herit. Sci. 14, 220 (2026). https://doi.org/10.1038/s40494-026-02511-w
Mots-clés: inscriptions sur os oraculaires, écriture chinoise ancienne, humanités numériques, intelligence artificielle, modèles multimodaux