Clear Sky Science · pt
Processamento de informação de inscrições em ossos oraculares: um levantamento abrangente
Ossos antigos, perguntas modernas
Há mais de 3.000 anos, adivinhos na China gravavam perguntas aos seus governantes em carapaças de tartaruga e ossos de boi, e depois os rachavam com calor para ler presságios. Essas inscrições em ossos oraculares constituem a forma mais antiga conhecida de escrita chinesa e uma janela rara para a política, a religião e a vida cotidiana da Idade do Bronze. Hoje, no entanto, os ossos estão muito fragmentados, a escrita é difícil de ler e muitos caracteres permanecem indecifráveis. Este artigo explica como novas ondas de inteligência artificial estão transformando a maneira como estudiosos limpam, reconstruem, leem e interpretam esses frágeis vestígios do passado, e quais desafios ainda permanecem.
Da mão e do olho para o silício e o código
Durante a maior parte do século passado, os ossos oraculares só podiam ser estudados por um pequeno círculo de especialistas que examinavam minuciosamente estereótipos de tinta, traçados e fotografias. Eles compilaram grandes catálogos impressos, propuseram leituras de caracteres individuais e debateram como as inscrições deviam ser datadas e agrupadas. Esse trabalho lançou as bases do campo, mas era lento, difícil de reproduzir e fortemente dependente da memória e do julgamento pessoal de cada pesquisador. Com a chegada dos computadores, os pesquisadores começaram a digitalizar estereótipos e aplicar truques básicos de processamento de imagem, como realce de contraste e detecção de bordas. Essas primeiras ferramentas tornaram os ossos mais fáceis de ver e compartilhar, mas tratavam os caracteres como meras formas, não como escrita dotada de significado.
O deep learning entra nos arquivos
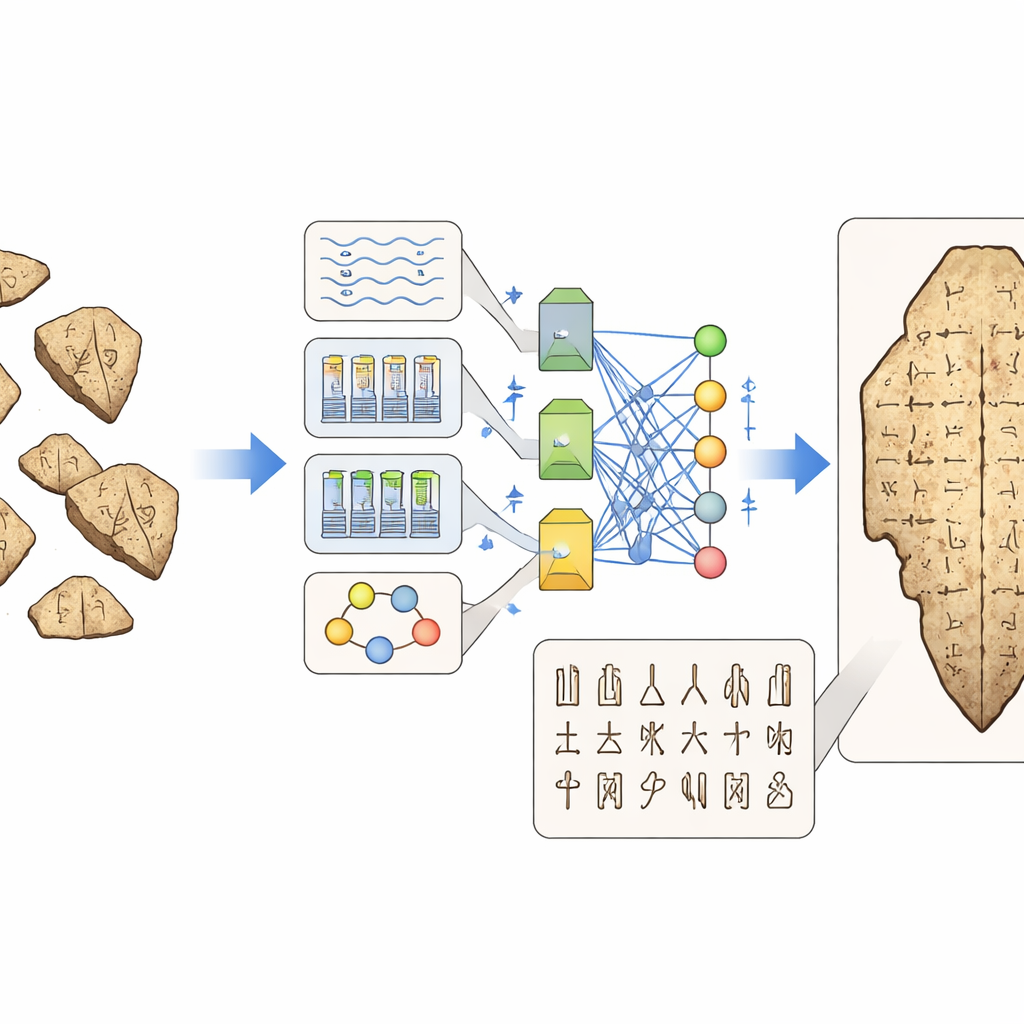
A ascensão do deep learning mudou o panorama. Redes neurais convolucionais e transformers, inicialmente afinadas em fotografias cotidianas, foram re-treinadas para identificar caracteres em estereótipos ruidosos, classificá-los em categorias e até ajudar a casar fragmentos quebrados que originalmente pertenciam ao mesmo osso. Para alimentar esses modelos famintos por dados, equipes compilaram dezenas de conjuntos de dados especializados: alguns focados em identificar cada caractere em um estereótipo, outros em classificar glifos recortados, vincular radicais e componentes, ou parear formas antigas com escritas posteriores. Ainda assim, os dados refletem a realidade histórica: alguns caracteres comuns aparecem milhares de vezes, enquanto muitos sinais raros ou indecifráveis surgem apenas uma vez. Pesquisadores respondem com estratégias engenhosas de aumento de dados, modelos generativos que sintetizam novos exemplos e esquemas de treinamento projetados para reconhecer caracteres a partir de apenas algumas — ou nenhuma — amostra conhecida.
Ensinando máquinas a ligar visão e sentido
Na fase mais recente, grandes modelos multimodais que combinam visão e linguagem vêm sendo adaptados para os ossos oraculares. Em vez de apenas localizar onde os caracteres estão, esses sistemas tentam conectar a aparência de um glifo ao seu possível sentido, tal como faz um paleógrafo humano. Novos benchmarks testam se tais modelos conseguem reconhecer caracteres, recompor fragmentos, recuperar inscrições semelhantes e sugerir leituras plausíveis. Alguns frameworks tentam mapear sinais antigos diretamente para caracteres chineses modernos, traçando a evolução visual ao longo dos séculos; outros ligam sinais pictóricos a imagens de objetos do mundo real; e outros ainda tentam produzir explicações textuais completas sobre o que uma linha de adivinhação pode dizer. Sistemas do tipo agente vão além, orquestrando múltiplas ferramentas e bases de dados para ajudar usuários a buscar através de imagens, transcrições e notas acadêmicas em um único fluxo de trabalho.
Dados, avaliação e o quebra-cabeça de uma história fragmentada
Apesar do progresso rápido, o levantamento ressalta obstáculos persistentes. Muitas das melhores coleções de imagens e digitalizações 3D estão em museus ou arquivos privados e não são abertamente acessíveis, dificultando a comparação justa de métodos ou o treinamento de modelos verdadeiramente gerais. Mesmo conjuntos de dados públicos frequentemente exibem distribuições de classes long-tail, rótulos inconsistentes ou baixa qualidade de imagem. Métricas de desempenho padrão, emprestadas de detecção de objetos ou reconhecimento de escrita, podem não capturar o que realmente importa para historiadores — por exemplo, se um modelo confunde duas variantes aceitas do mesmo caractere, ou se a leitura proposta respeita como um sinal é construído a partir de partes menores. A avaliação humana é igualmente fragmentada: estudos diferentes recrutam especialistas distintos, fazem perguntas diversas e raramente relatam detalhes suficientes para que outros possam replicar seus testes.
Onde a escrita antiga encontra a IA do futuro
Para avançar, os autores defendem conjuntos de dados mais ricos e bem documentados; métodos de avaliação que recompensem compreensão estrutural e semântica, não apenas correspondências a nível de pixel; e colaboração mais estreita entre tecnólogos e especialistas em escrita chinesa antiga. Eles imaginam geradores de texto-para-imagem que possam produzir caracteres realistas em estilo de ossos oraculares a partir de descrições, modelos fundamentais treinados especificamente em escritas antigas, sistemas multiagente que debatam e refinem leituras concorrentes e até reconstruções 3D que restaurem a forma original de ossos quebrados. Em termos claros, a conclusão do artigo é que a IA não vai “resolver” os ossos oraculares por si só, mas pode se tornar uma parceira poderosa — ampliando a percepção dos especialistas, tornando vastos arquivos pesquisáveis e abrindo as vozes da Idade do Bronze para um público muito mais amplo.
Citação: Chen, Z., Hua, W., Li, J. et al. Oracle bone inscriptions information processing: a comprehensive survey. npj Herit. Sci. 14, 220 (2026). https://doi.org/10.1038/s40494-026-02511-w
Palavras-chave: inscrições em ossos oraculares, escrita chinesa antiga, humanidades digitais, inteligência artificial, modelos multimodais