Clear Sky Science · tr
Kesin kılçık yazıtlarının bilgi işlemi: kapsamlı bir inceleme
Antik kemikler, modern sorular
3.000 yıldan fazla önce, Çin’de kahinler kaplumbağa kabukları ve öküz kemiklerine hükümdarlara sorular kazıdı, sonra kehanet okumak için bunları ısıyla çatlattı. Bu kesin kılçık yazıtları bilinen en eski Çince yazıdır ve Bronz Çağı siyaset, din ve günlük yaşama nadir bir pencere sunar. Bugün ise kemikler büyük oranda kırılmış, yazı okunması zor ve pek çok işaret hâlâ çözülememiş durumdadır. Bu makale, yapay zekanın yeni dalgalarının bilim insanlarının bu hassas geçmiş izlerini temizleme, yeniden birleştirme, okuma ve yorumlama biçimini nasıl dönüştürdüğünü ve önünde hâlâ hangi zorlukların bulunduğunu açıklar.
El ve gözden silikon ve koda
Geçen yüzyılın çoğunda, kesin kılçıklar yalnızca mürekkepli frottajlar, kopyalar ve fotoğrafları titizlikle inceleyen küçük bir uzman çevresi tarafından incelenebiliyordu. Devasa basılı katalogları derlediler, bireysel işaretlerin okunuşlarını önerdiler ve yazıtların nasıl tarihleneceği ve gruplanacağı konusunda tartıştılar. Bu çalışmalar alanın temelini attı, ancak yavaş, çoğaltması zor ve her bir bilim insanının kişisel belleğine ve yargısına güçlü biçimde bağımlıydı. Bilgisayarlar geldikçe araştırmacılar frottajları dijitalleştirmeye ve kontrast artırma ile kenar algılama gibi temel görüntü işleme yöntemlerini uygulamaya başladılar. Bu erken araçlar kemikleri görmek ve paylaşmak için işleri kolaylaştırdı, ancak işaretleri anlamlı yazı değil yalnızca şekiller olarak ele aldı.
Derin öğrenme arşivlere giriyor
Derin öğrenmenin yükselişi manzarayı değiştirdi. İlk olarak gündelik fotoğraflar üzerinde incelenen konvolüsyonel sinir ağları ve transformerlar, gürültülü frottajlarda işaretleri seçmek, bunları kategorilere ayırmak ve hatta bir zamanlar aynı kemiğe ait olan kırık parçaları eşleştirmeye yardımcı olmak üzere yeniden eğitildi. Bu veri aç modelleri beslemek için ekipler onlarca özel veri kümesi derledi: bazıları bir frottajdaki her işareti tanımlamaya odaklandı, bazıları kırpılmış glifleri sınıflandırmaya, bileşenleri ve radikalleri bağlamaya veya antik formları sonraki yazı stilleriyle eşleştirmeye yöneldi. Ancak veriler tarihsel gerçekliği yansıtır: birkaç yaygın işaret binlerce kez görünürken, birçok nadir veya çözülememiş işaret yalnızca bir kez ortaya çıkar. Araştırmacılar bunu zekice veri çoğaltma, yeni örnekler sentezleyen üretici modeller ve yalnızca birkaç—ya da hiç—bilinen örnekten karakterleri tanıyacak şekilde tasarlanmış eğitim şemalarıyla yanıtlıyor.
Makinelere görme ile anlamı köprülemeyi öğretmek
En son aşamada, görme ve dili birleştiren büyük multimodal modeller kesin kılçıklara uyarlanıyor. Bu sistemler yalnızca işaretlerin nerede olduğunu tespit etmekle kalmayıp, bir glifin nasıl göründüğünü onun ne anlama gelebileceğiyle bağlamaya çalışıyor; tıpkı bir paleografın yaptığı gibi. Yeni ölçütler bu tür modellerin karakterleri tanıyıp tanıyamayacağını, parçaları yeniden birleştirip birleştiremeyeceğini, benzer yazıtları geri çağırıp çağırmayacağını ve makul okumalar önerip önermeyeceğini test ediyor. Bazı çerçeveler antik işaretleri doğrudan modern Çince karakterlerle eşlemeye çalışarak yüzyıllar boyunca görsel evrimi izliyor; bazıları resimsel işaretleri gerçek dünya nesnelerinin görselleriyle bağlıyor; diğerleri bir kehanet satırının ne söylemiş olabileceğine dair tam metinsel açıklamalar deniyor. Ajan tarzı sistemler bir adım daha ileri giderek birden çok araç ve veritabanını düzenliyor, kullanıcılara tek bir iş akışında görüntüler, transkripsiyonlar ve bilimsel notlar arasında arama yapma konusunda yardımcı oluyor.
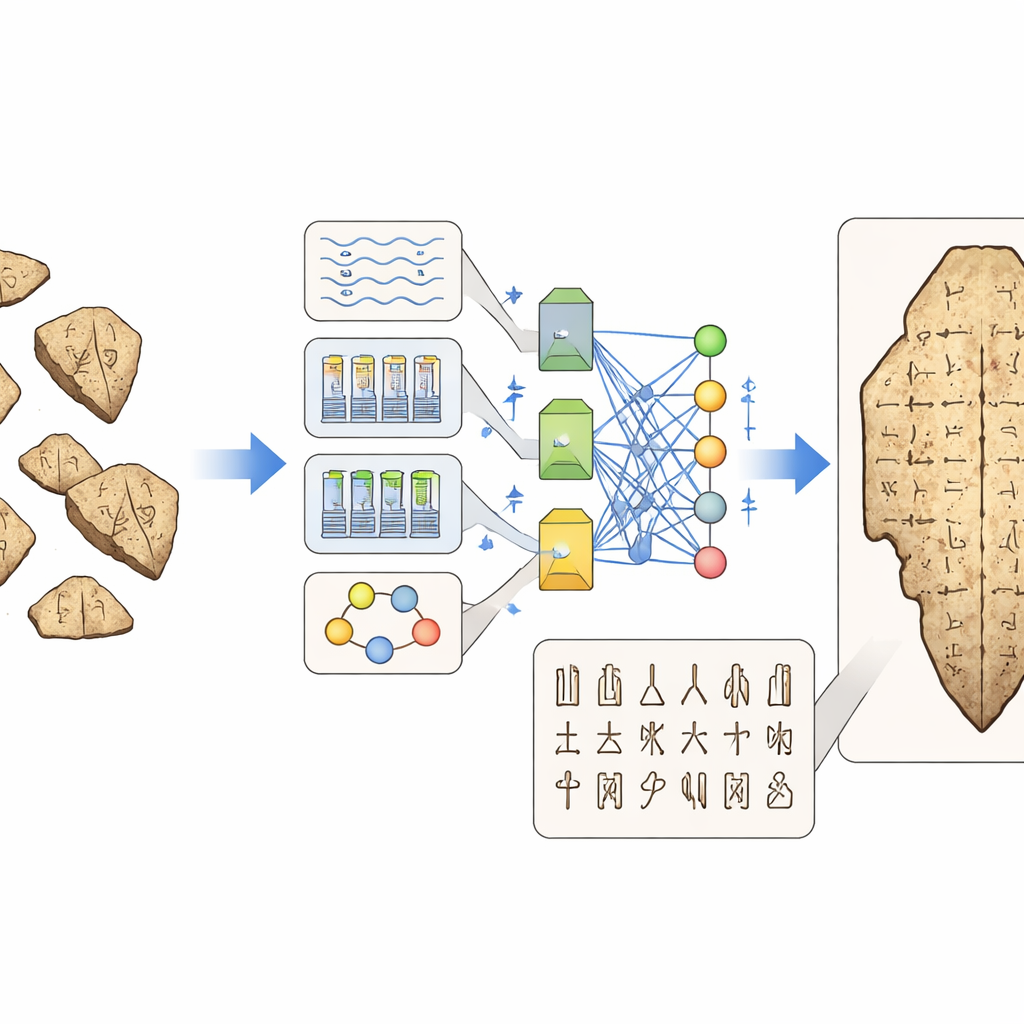
Veri, değerlendirme ve kırık tarihin bulmacası
Hızlı ilerlemelere rağmen, derleme inatçı engelleri vurguluyor. En iyi görüntü koleksiyonlarının ve 3B taramaların çoğu müzelerde veya özel arşivlerde duruyor ve açık biçimde erişilebilir değil; bu da yöntemleri adil şekilde karşılaştırmayı veya gerçekten genel modeller eğitmeyi zorlaştırıyor. Halka açık veri kümeleri bile genellikle uzun kuyruklu sınıf dağılımlarına, tutarsız etiketlemelere veya düşük görüntü kalitesine sahip. Nesne tespiti veya el yazısı tanımadan ödünç alınan standart performans skorları tarihçiler için gerçekten önemli olanı yakalamayabilir—örneğin bir modelin aynı karakterin kabul edilmiş iki varyantını karıştırıp karıştırmadığı ya da önerilen okumasının bir işaretin daha küçük parçalardan nasıl kurulduğuna saygı gösterip göstermediği gibi. İnsan değerlendirmesi de benzer şekilde parçalanmış: farklı çalışmalar farklı türde uzmanları işe alıyor, farklı sorular soruyor ve nadiren başkalarının testlerini çoğaltması için yeterince detaylı raporlama yapıyor.
Antik yazının geleceğin yapay zekasıyla buluştuğu yer
İlerlemek için yazarlar daha zengin, daha iyi belgelenmiş veri kümeleri; yalnızca piksel düzeyinde eşleşmeler değil yapısal ve anlamsal anlayışı ödüllendiren değerlendirme yöntemleri; ve teknologlar ile erken dönem Çin yazısı uzmanları arasında daha yakın iş birliği öneriyor. Tasvirlere dayanarak gerçekçi kesin kılçık tarzı karakterler üretebilecek metinden-görüntüye üreticiler, antik yazılarda özel olarak eğitilmiş temel modeller, rekabet eden okumaları tartışıp rafine eden çoklu-ajan sistemleri ve kırık kemiklerin orijinal şeklini geri kazandıran 3B yeniden yapılandırmalar hayal ediyorlar. Düz ifadeyle, makalenin sonucu şu: Yapay zeka kendi başına kesin kılçıkları “çözmeyecek”, ancak uzman sezgisini güçlendiren, geniş arşivleri aranabilir kılan ve Bronz Çağı seslerini çok daha geniş bir kamuya açan güçlü bir ortak haline gelebilir.
Atıf: Chen, Z., Hua, W., Li, J. et al. Oracle bone inscriptions information processing: a comprehensive survey. npj Herit. Sci. 14, 220 (2026). https://doi.org/10.1038/s40494-026-02511-w
Anahtar kelimeler: kesin kılçık yazıtları, antik Çin yazısı, dijital beşeri bilimler, yapay zeka, multimodal modeller